


邮箱|zhouyixiao@pingwest.com
就在上周,关于OpenAI下一代大模型即将发布的传闻不断。从业内消息到代码库中发现的新模型标识(如“o4-mini”、“o3”),种种迹象都指向眼前的发布——可能命名为GPT-4.1,被视为GPT-4o的有力继承者。
现在,靴子终于落地。OpenAI这次没有让大家等太久,正式推出了备受期待的GPT-4.1系列,完整阵容包括旗舰版GPT-4.1、高性价比的GPT-4.1 mini和超轻量的GPT-4.1 nano。值得注意的是,这次更新的焦点并非面向大众用户,仅通过API接口提供服务,OpenAI官方文档直言不讳地指出,这批新模型在各项能力上全面超越了此前的GPT-4o和GPT-4o mini,在编码能力、指令遵循、长文本处理等核心维度实现了进步,并辅以全新定价策略,其知识库也已刷新至2024年6月。OpenAI的核心目标明确:为构建Agent应用的开发者提供更强悍、更可靠且更经济的基础设施。
#01
编程评测表现优于GPT-4.5
编码能力的强化是GPT-4.1系列最耀眼的亮点之一。官方数据显示,在衡量真实世界软件工程能力的SWE-bench Verified基准测试中,GPT-4.1取得了54.6% 的分数,相比GPT-4o的33.2%,实现了高达21.4个绝对百分点的提升。
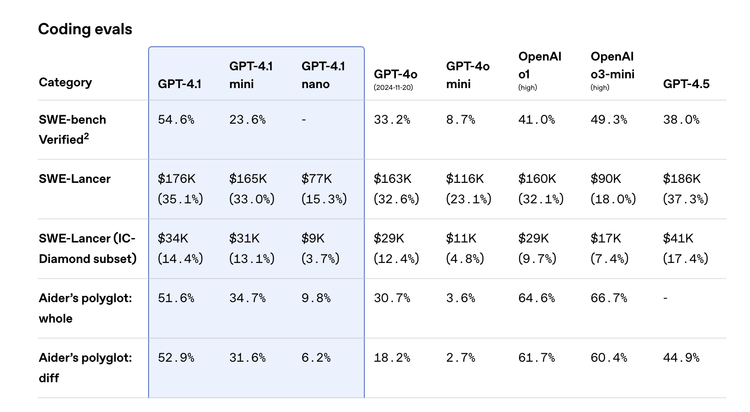
更令人玩味的是,这一成绩甚至比定位更高的GPT-4.5(38.0%)还要高出不少,上演了一出“4.1 > 4.5”的有趣戏码。这意味着GPT-4.1在理解代码库、按需完成编程任务、生成能实际运行并通过测试的代码方面有了质的飞跃。
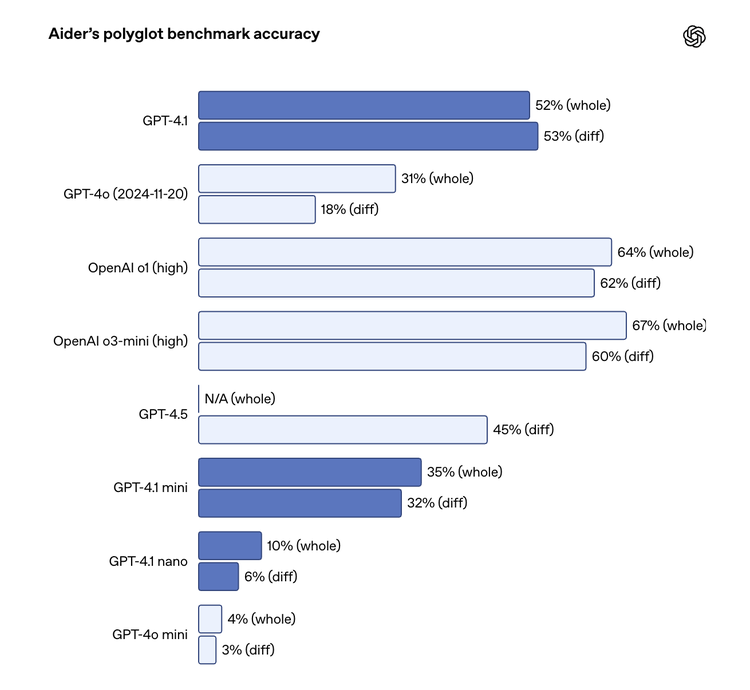
不仅如此,GPT-4.1在代码处理的细节上也更为精进。例如,它在处理代码差异(diffs)方面更加可靠,根据Aider’s polyglot diff benchmark,其表现甚至超越了GPT-4.5。官方还特别提到,模型进行无关编辑(extraneous edits)的频率从GPT-4o的9%显著降低到了2%。
对于前端开发者而言,GPT-4.1生成的网页应用在功能性和美观性上也更胜一筹,在内部测试中,人类评估者有80%的时间更偏好GPT-4.1的作品。同时,为了支持更大规模的代码编辑,GPT-4.1的最大输出Token限制也提升至32,768个(GPT-4o为16,384个)。据OpenAI官方,来自早期测试伙伴如Windsurf和Qodo的反馈也印证了这些提升,他们观察到GPT-4.1在实际代码生成和代码审查任务中效率更高、错误更少。
指令遵循能力的提升同样是本次更新的重中之重。模型现在能更精准地理解和执行复杂、多步骤的指令。在Scale’s MultiChallenge基准测试(评估多轮对话中的指令遵循能力)中,GPT-4.1得分38.3%,较GPT-4o提升了10.5个绝对百分点。
而在IFEval测试(验证模型遵循格式、长度、禁用词等具体约束的能力)中,得分也从81.0%提升至87.4%。OpenAI内部评估也显示,特别是在处理困难指令时,GPT-4.1的改进尤为明显。这种可靠性的增强,对于构建能够自主完成任务的AI Agent系统至关重要,能有效减少开发者“手把手教”的负担。
来自Blue J(税务场景)和Hex(SQL生成)等合作伙伴的真实案例也表明,GPT-4.1在处理复杂规则和歧义、遵循细微指令方面表现更佳,显著提高了应用准确性和开发效率。
#02
全系支持百万级长文本处理
全系标配且真正“可用”的百万级长文本处理能力,是GPT-4.1系列的另一大重点。不仅旗舰版GPT-4.1,连同mini和nano版本,都支持高达100万Token的上下文窗口(远超GPT-4o的128k)。OpenAI此次特别强调,这不仅仅是窗口大小的提升,更在于模型在如此长的文本中保持专注和理解的能力得到了强化。经典的“大海捞针”(Needle in a Haystack)测试结果显示,GPT-4.1系列能在1M长度的文本中稳定、准确地找到隐藏信息。
为了证明模型在更接近真实世界复杂场景下的长文本能力,OpenAI还开源了两套新的评估基准:OpenAI-MRCR(测试在长文本中区分和检索多个相似信息点的能力)和Graphwalks(评估需要跨文本多处进行逻辑跳转和推理的多跳推理能力)。
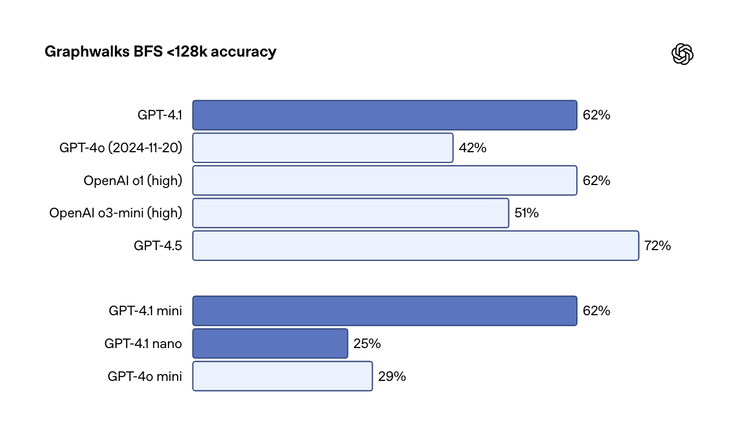
测试结果表明,GPT-4.1在这些更具挑战性的任务上,相比前代有显著优势,并且能在百万Token级别保持强大的性能。这对需要处理大量代码、多份冗长法律文件或金融报告的应用场景来说,无疑是巨大的福音。Thomson Reuters和Carlyle等金融和法律领域的早期用户反馈,GPT-4.1在处理多份复杂长文档、提取精确信息、进行跨文档推理方面,准确性显著提高,克服了以往模型在“大海捞针”、“中间丢失”和多跳推理上的局限。
当然,处理百万Token的延迟也是开发者关心的,官方给出的初步数据是,GPT-4.1处理128k Token时首个Token的p95延迟约15秒,1M Token则可能需要半分钟左右,而mini和nano版本则会快得多。
#03
更好的多模态
此外,GPT-4.1家族的视觉理解能力也保持了高水准。特别是GPT-4.1 mini,在MMMU、MathVista等多个视觉基准测试上的表现甚至优于GPT-4o。旗舰版GPT-4.1则在长视频理解基准Video-MME(无字幕长视频问答)上取得了72.0%的新SOTA成绩。

伴随性能提升而来的是极具吸引力的新定价体系。得益于推理效率的优化,GPT-4.1系列的价格相当“香”:
-
GPT-4.1: 输入 $2.00 / 输出 $8.00 (每百万Token),官方称比GPT-4o的中位数查询成本低26%。
-
GPT-4.1 mini: 输入 $0.40 / 输出 $1.60,在性能接近甚至超越GPT-4o的同时,成本和延迟大幅降低。
-
GPT-4.1 nano: 输入 $0.10 / 输出 $0.40,成为OpenAI有史以来最便宜、最快速的模型,且同样支持1M上下文。

此外,Prompt Caching(提示缓存)的折扣从之前的50%提高到了75%,对于需要重复传递相同上下文的应用能大幅节约成本。同时,使用Batch API(批量处理)还能享受额外的50%折扣。
需要注意的是,随着GPT-4.1系列的登场,之前作为预览版推出的GPT-4.5 Preview API也迎来了谢幕。OpenAI宣布,该API将在2025年7月14日正式关闭,给予开发者3个月的过渡时间,鼓励大家迁移到性能更优、成本更低的GPT-4.1系列。
#04
进步了,但很难全赢
GPT-4.1的发布,被一些市场观察者解读为OpenAI对Anthropic和Google等竞争对手近期积极动作的回应,而非一次颠覆性的技术突破。有不少评论直接指出,尽管进步显著,但在某些特定基准上,如Aider Polyglot编码测试,GPT-4.1(约52%)与Google Gemini 2.5 Pro(据报道约73%)相比仍有差距。
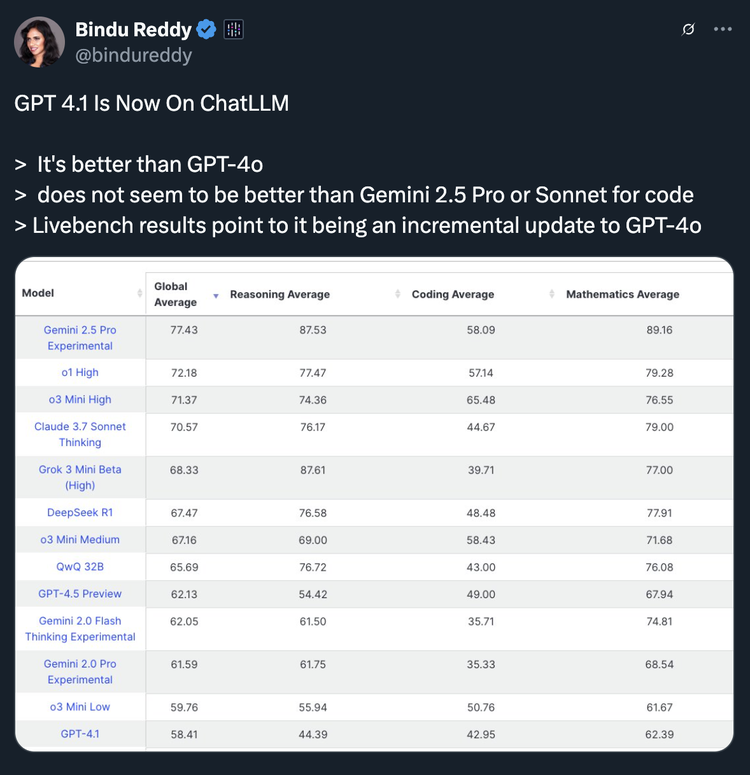
来自第三方基准平台(如与ChatLLM服务相关的Livebench)的早期结果在一定程度上支持了这种观点:虽然确认GPT-4.1相较于GPT-4o有所改进(’It’s better than GPT-4o’),但同时将其描述为一次“增量更新”(incremental update)。更值得注意的是,在OpenAI重点宣传的编码能力方面,该基准评估认为其表现“似乎并未优于Google的Gemini 2.5 Pro或Anthropic的Claude 3 Sonnet (或更高版本模型)” 。这似乎意味着AI领域的竞争已进入到更细分、更针对性的能力比拼阶段,而非全面的代际碾压。

而谈及OpenAI,其“迷幻”的命名体系总是绕不开的话题。从GPT-4o、4.5、4.1,到内部代号般的o1、o3、o4系列(还分low/medium/high/mini/pro各种后缀),再到ChatGPT界面上令人困惑的模型选项(4o、o3-mini、o1、Deep Research、4.5、带任务调度的4o…),“像正常人一样给模型命名”似乎成了一项不可能完成的任务。这对于一个力求普及AI技术的公司而言,无疑增加了用户的理解成本。
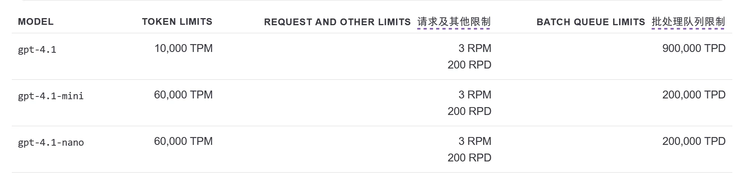
尽管如此,OpenAI此次GPT-4.1系列的发布,仍然释放了一个明确的信号:OpenAI没有忘记开发者。GPT-4.5的官方API接下来一周内也可以免费使用,每分钟3次请求,一天200次,TPM1万。
不过相较于GPT-4o在多模态交互上的惊艳问世,GPT-4.1系列更像是一次深入生产环节的“内功”修炼,精准解决了开发者在编码、指令控制、长文本处理等核心痛点。这种API优先、强调实用性和性价比的策略同时,不仅是对自身模型效率提升的自信展示,也势必给Anthropic、Google、xAI等对手带来更大的压力。
或许OpenAI真正的“大招”还在后面——毕竟o3完整版和o4 mini模型的发布也已箭在弦上。

(文:硅星GenAI)