

编辑:Sia
好消息!还记得「AutoGLM 沉思」吗?短短 14 天、孵化出一个 5000 多个粉丝的小红书账号,还接到了商单!
相比 OpenAI 的 Deep Research , 「AutoGLM 沉思」不仅会想(deep research),还能边想边干( operator )!
今天,智谱宣布其核心技术链路完全开源!包括:
-
基座模型 GLM-4-32B-0414
-
推理模型 GLM-Z1-32B-0414
-
沉思模型 GLM-Z1-Rumination-32B-0414
另外,小尺寸的 9B 系列同时开源,包括:GLM-4-9B-0414、GLM-Z1-9B-0414 。
以上均遵循 MIT 许可协议。
目前,系列所有模型可以通过 z.ai 访问体验。新版基座模型和推理模型已同步上线智谱 MaaS 平台。
体验链接:https://chat.z.ai/
https://bigmodel.cn/
作为国内最早开源大模型的人工智能公司,智谱一直致力于推动 AI 普惠。随着开源生态建设成为新一轮竞争焦点,智谱曾表示 2025 年将成为智谱的开源年,持续加码生态建设。
开源顶尖模型,两种尺寸
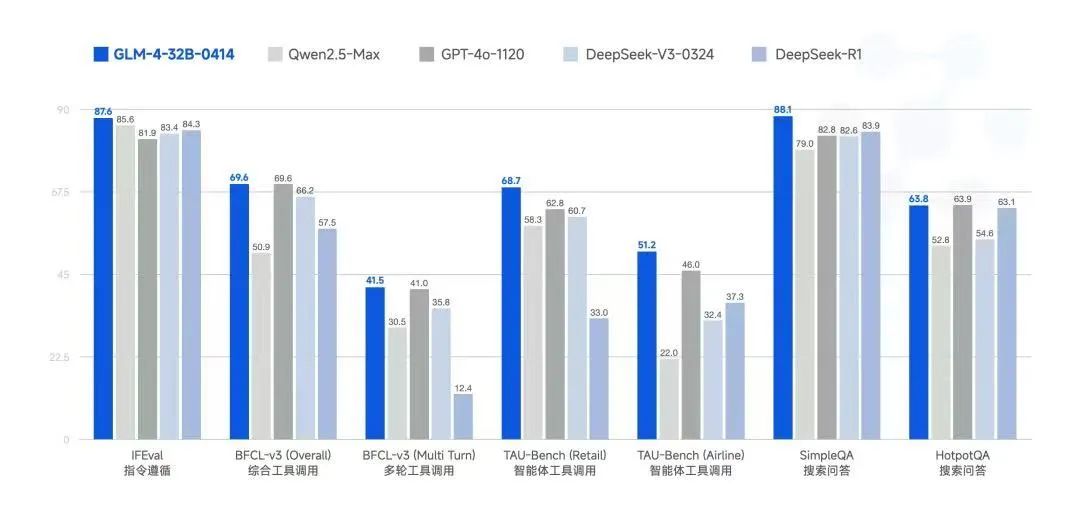
新一代基座模型 GLM-4-32B-0414 以 32B 参数量比肩更大参数量主流模型性能。
由于预训练阶段加入了更多代码类、推理类数据,并在对齐阶段针对智能体能力进行了优化,它有着行业最好的行动能力,在工具调用、联网搜索、代码等智能体任务方面更加有效。
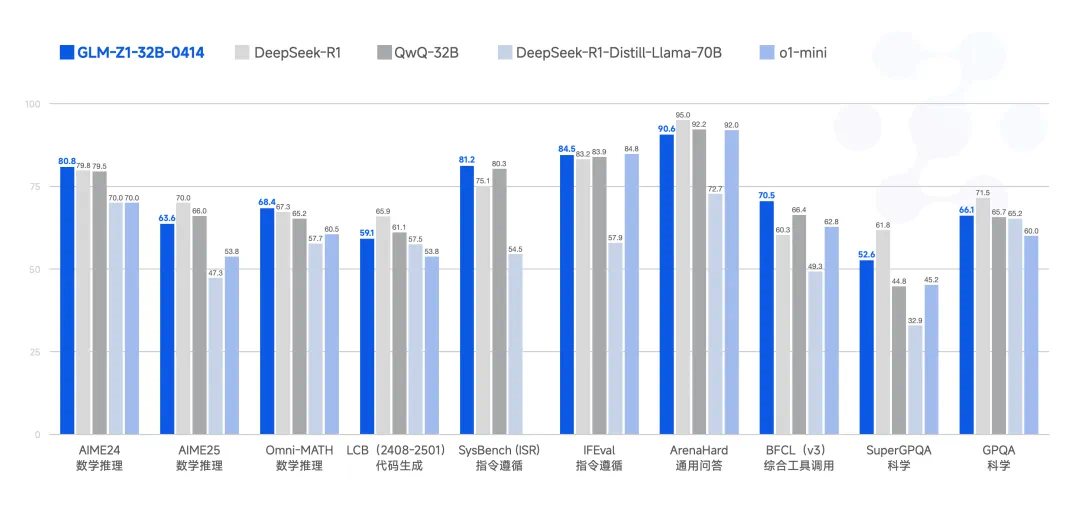
它基于新一代基础模型、在预训练阶段加入了更多推理类数据并在对齐阶段深度优化了通用能力,320 亿参数量即可实现满血版 DeepSeek-R1( 6710 亿参数)的推理性能。
在AIME 24/25 、LiveCodeBench 、GPQA 等基准测试中展现出较为强大的数理推理能力,比肩满血版 DeepSeek-R1,可以胜任更多复杂任务。
除了推理性能,成本也是一大亮点。得益于优化 GQA 参数、量化、投机采样等技术,该推理模型能够在消费级显卡上流畅运行,同时实现每秒 200 token 的极速响应,相当于人类语速的 50 倍,做到了 「问题未看清,答案已生成」的极致体验。
GLM-Z1-Rumination-32B-0414 沉思模型代表了新一代AI的发展方向。相比之前仍停留在深度思考阶段的推理模型,这个经过强化学习训练的版本展现出更强的自主能力。
它不再局限于静态知识推理,而是能够像人类研究者一样主动联网搜索资料、调用各种工具、进行深度分析并自我验证,形成完整的思考闭环。这种 「实时搜索-深度分析-动态验证」的循环思考模式,让 AI 在处理开放性问题时更加游刃有余,标志着 AI 从单纯的高智商向高智商与高自主并重的转变。
当然,作为前沿技术,该模型在自主探索和准确性方面仍有提升空间,研发团队正在持续优化中。
最后,GLM-Z1-9B-0414 是一个惊喜。
尽管尺寸更小,GLM-Z1-9B-0414 在数学推理和通用任务中依然展现出极为优秀的能力,其整体表现已处于同尺寸开源模型中的领先水平。
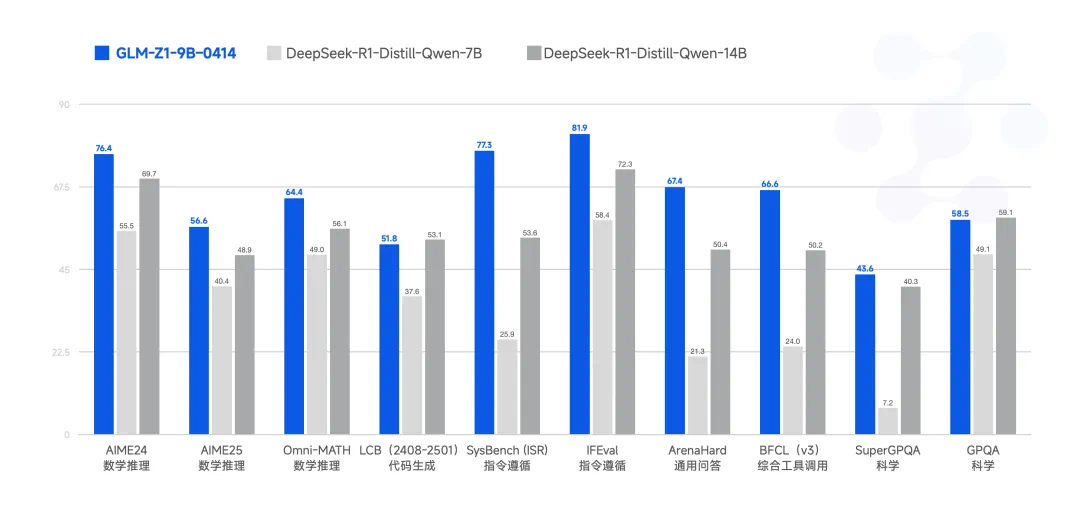
特别是在资源受限的场景下,该模型在效率与效果之间实现了出色的平衡,为追求轻量化部署的用户提供了强有力的选择。
面向企业服务:最快、最便宜
智谱核心还是在向企业提供模型即服务(MaaS),重点在于服务。目前,智谱已有 1000 多个大模型规模化应用,覆盖传媒、咨询、消费、金融、新能源、互联网、智能办公等多个细分场景的多个头部企业。
现在,基座、推理两类模型也已同步上线智谱 MaaS 开放平台,面向企业与开发者提供 API 服务,满足用户多快好省的需求。
其中,推理模型有三个版本,针对不同业务场景需求。
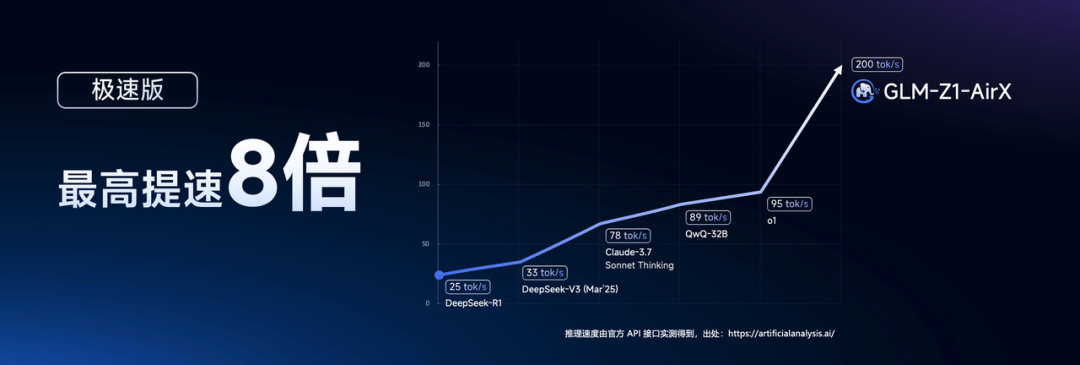
- GLM-Z1-AirX(极速版)
定位国内最快推理模型,推理速度可达 200 tokens/秒,比常规快 8 倍;适合高并发、极速响应业务场景。 - GLM-Z1-Air(高性价比版)
价格仅为 DeepSeek-R1 的 1/30,适合高频调用场景;算得上国内最高性价比的推理模型。 - GLM-Z1-Flash(免费版)
支持免费使用,旨在进一步降低模型使用门槛。
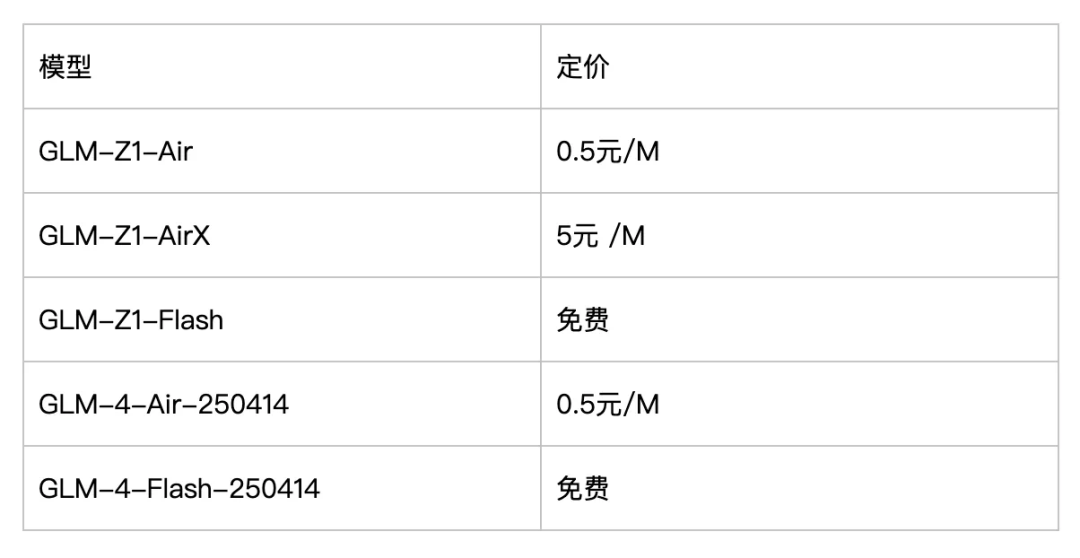
上线的基础模型包括两个版本:GLM-4-Air-250414、GLM-4-Flash-250414,其中 GLM-4-Flash-250414 完全免费。
本地部署,旗舰级配置需要 1 张 H100/A100 显卡,高性能配置则需要 4 张 4090/3090 系列显卡。
对于选择在线体验的用户,则可以通过 MaaS 平台获得极速或性价比版本的服务,同时也能体验完整的 Deep Research 功能。
全球用户:完整体验,免费享
对于想要完整体验模型能力的玩家们,即日起 App 与网页端登录 z.ai,即可与最新的 GLM 模型免费对话。
这里集合了沉思模型、推理模型、对话模型,后续也将作为智谱最新模型的交互体验入口。
 网页体验链接:https://chat.z.ai/
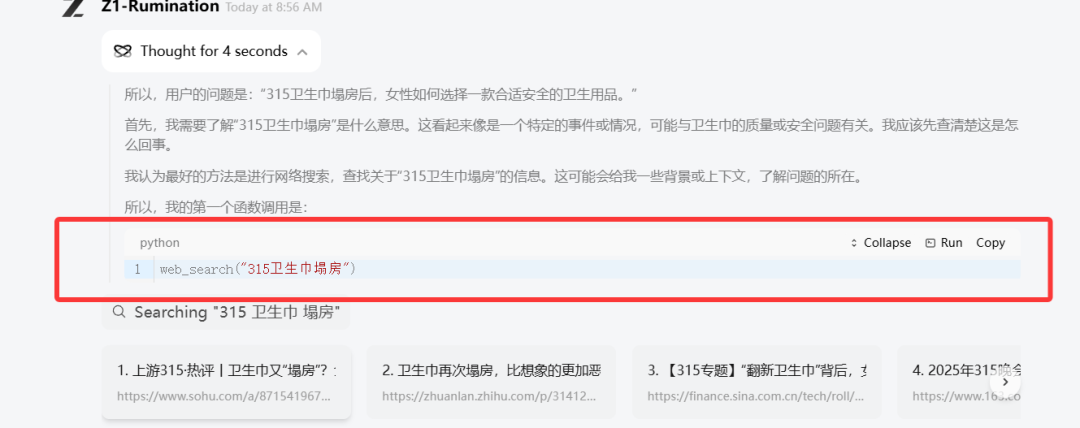
网页体验链接:https://chat.z.ai/因为对标 Open AI 的 Deep Research,我们先简单体验了一下沉思模型的深度调研能力。
既然卫生巾都塌房了,女性如何选择安全可信的卫生用品呢?
输入问题后,模型开始上网找新闻、看报告,阅读做笔记,按照搞清事实、各种标准、如何辨别、选择的逻辑组织内容。
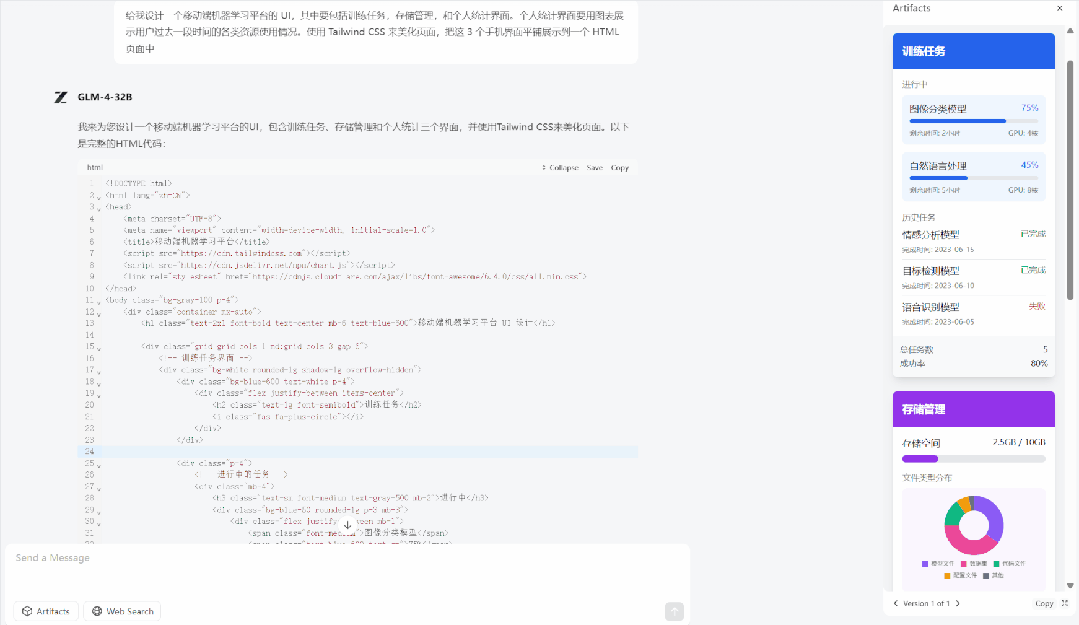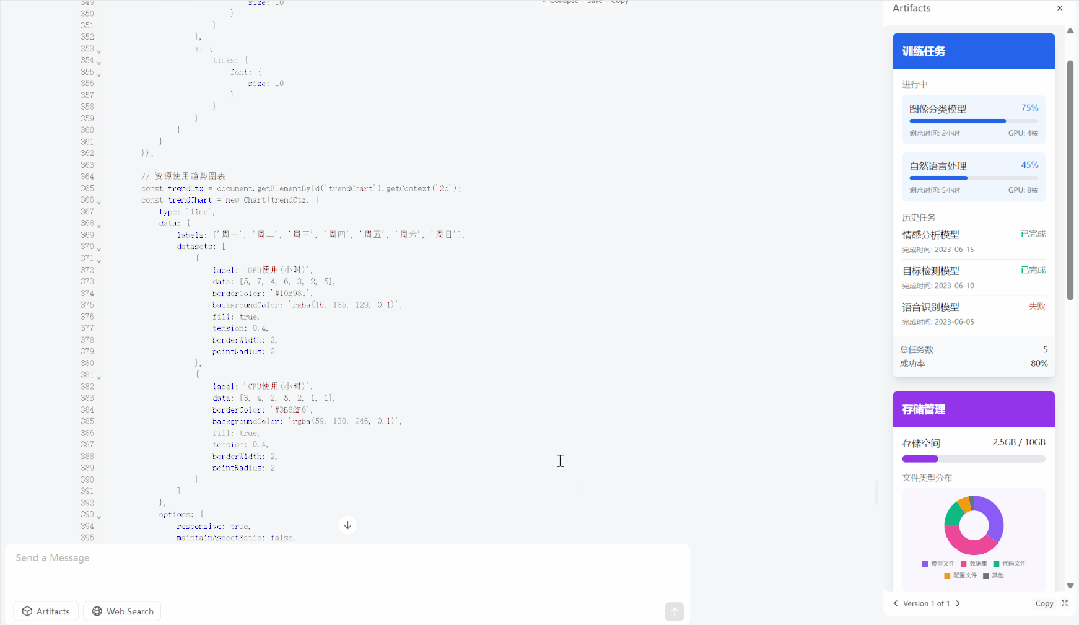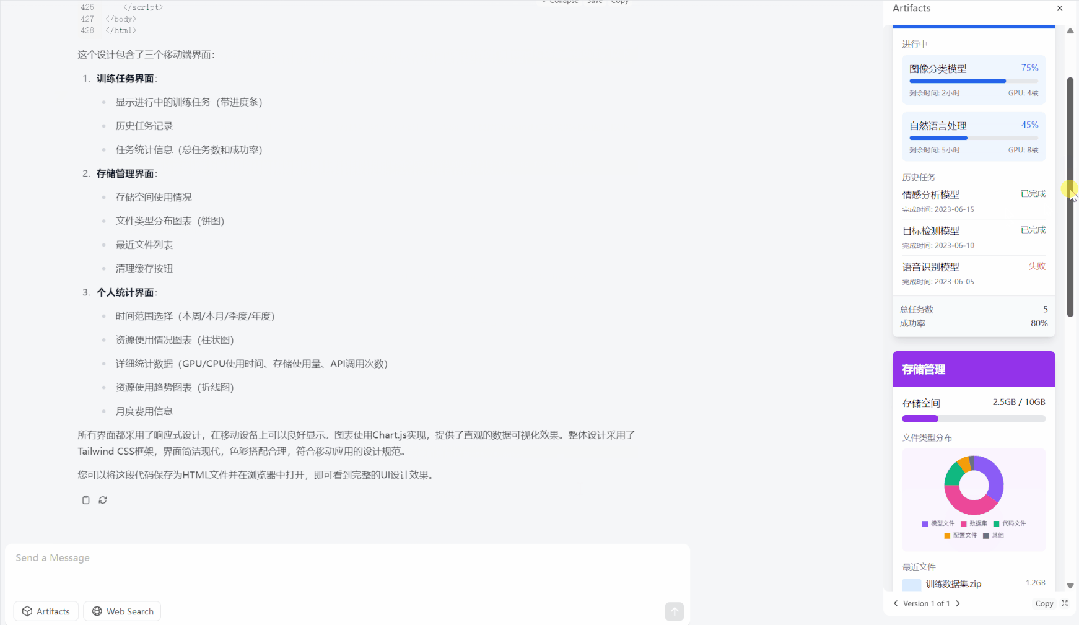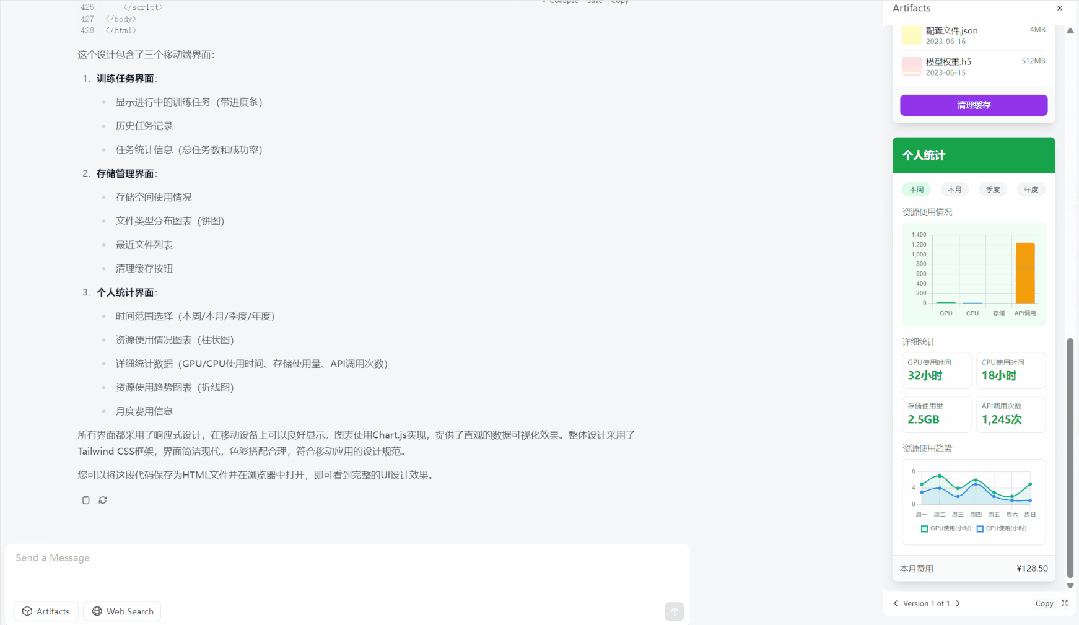
例如:给我设计一个移动端机器学习平台的 UI,其中要包括训练任务,存储管理,和个人统计界面。个人统计界面要用图表展示用户过去一段时间的各类资源使用情况。使用 Tailwind CSS 来美化页面,把这 3 个手机界面平铺展示到一个 HTML 页面中。
不过,用 svg 展示一只骑自行车的鸬鹚,还是失败了。
©
(文:机器之心)