

AI技术飞速发展的浪潮中,数据量通常被视作决定模型性能的关键因素。然而,当OpenAI、谷歌等企业纷纷借助海量用户数据来训练大型模型时,苹果却另辟蹊径,将隐私保护作为AI技术发展的核心准则。
近日,苹果公司公开了AI开发过程的关键技术细节,向外界展示了如何在保障用户隐私基础上实现AI性能突破。个人觉得这不仅是一次技术路线的革新,还会重新定义AI行业的竞争规则。
苹果公司AI技术的底层逻辑,与多数科技巨头依赖云端服务器处理用户数据不同,苹果始终以设备端为核心进行AI训练。
在邮件摘要、写作助手等功能中,用户数据直接在iPhone、iPad或Mac本地完成向量化处理,仅将脱敏后的特征向量与合成数据进行比对。
数据不动、模型动的模式,彻底颠覆了传统AI依赖数据上传的路径。
技术突破点
• 本地计算框架:借助Apple Silicon芯片的神经网络引擎,实现设备端的高效向量化运算,有效避免了原始数据外流。
• 动态隐私预算:依据数据类型自动调整差分隐私的噪声强度,从而实现精准保护。
在Genmoji功能中,苹果运用差分隐私技术收集高频指令,同时巧妙规避了隐私泄露风险。
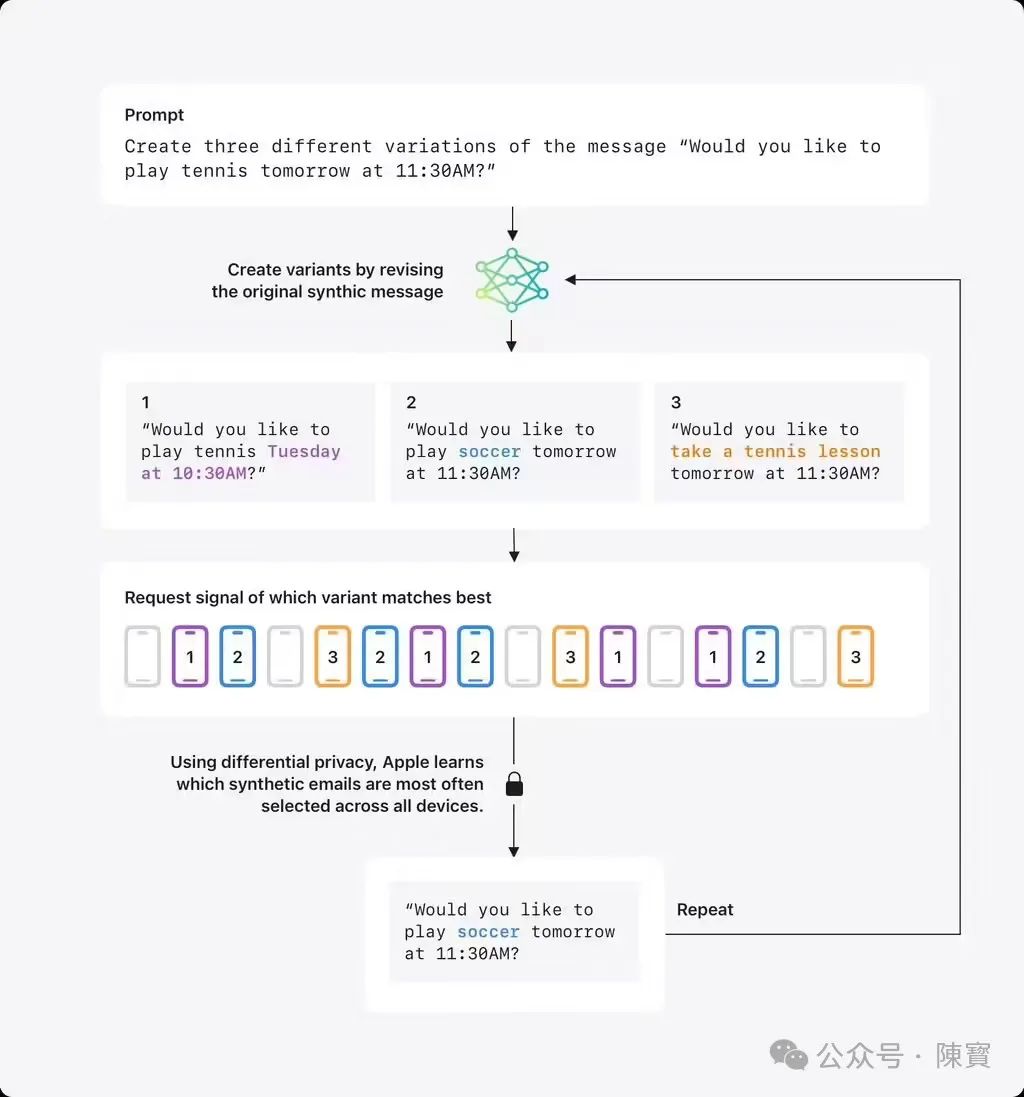
噪声注入机制中,设备端随机返回真实指令或干扰信号,只有当某指令被数百台设备同时提交后,才会被系统识别。
脱钩设计中,数据与设备ID、IP地址完全分离,即使数据被截获,也无法追溯至个体用户。
例如用户频繁请求生成“穿西装的猫”表情时,系统会优化该组合的渲染算法,但苹果始终无法知晓具体是谁在请求。
群体趋势可见,个体行为隐匿,是差分隐私的精髓。
⋯ ⋯
苹果公司合成数据策略分为三个步骤:
(一)生成上,利用大语言模型批量创建虚拟邮件,涵盖多样化的主题和语言风格。
(二)向量映射中,将合成邮件转换为包含语义特征的数字向量,构建特征库。
(三)动态校准上,设备端将真实邮件向量与合成库进行比对,通过差分隐私反馈最接近的类别,进而迭代优化合成数据集。
合成数据自动过滤社保号、银行卡号等隐私字段,从源头降低泄露风险。
通过调整生成模型的参数,可定向补充稀缺场景数据,解决传统合成数据分布偏差问题。
苹果的合成数据并非静态资源,而是构建了一个“生成 – 比对 – 优化”的动态闭环。
设备端记录用户对AI建议的采纳率,通过联邦学习更新模型。
每轮迭代后,生成模型会参考用户偏好调整输出,使合成数据更贴近真实需求。使得苹果的AI模型在合规框架下实现越用越聪明,而无需触碰原始数据。
⋯ ⋯
传统AI竞赛中,数据规模往往决定模型能力。导致头部公司形成数据垄断,苹果的隐私技术路线打破了这一逻辑。
通过合成数据增强和差分隐私分析,用更少的数据实现更高的训练效率,iOS 18.5测试版邮件摘要准确率提升37% 就是最好的证明。
苹果公司依赖Apple Silicon芯片的本地算力,其他厂商难以复制设备端处理能力,从而形成技术护城河。
也进一步将隐私转化为产品竞争力,因为用户深知设备在“学习”自己的写作风格,但由于数据永不离开设备,他们选择信任。
在GDPR、CCPA等法规日益严格的背景下,苹果的隐私原生设计减少了法律风险,吸引了企业用户。
苹果的技术实践正在推动AI隐私保护标准化,差分隐私库开源之后,TensorFlow Privacy、PyDP等工具也将普及,进一步降低了行业应用门槛。
⋯ ⋯
未来会出现第三方机构对合成数据的隐私安全认证,我认为会成为AI模型合规性的新指标。
(一)但技术局限性也是存在的,当设备端数据有限时,合成数据难以充分模拟真实分布。本地差分隐私处理增加了芯片能耗,会影响设备续航。
(二)生态博弈过程中,第三方APP需重构数据处理流程以适应苹果的隐私框架,也会引发生态摩擦。如何在保护隐私的前提下实现安卓与iOS的AI协同,仍需技术突破。
(三)未来趋势上,专为差分隐私优化的硬件模块有机会成为下一代iPhone的卖点。
也会出现合规的合成数据交易平台,企业可购买特定场景的虚拟数据集来训练模型。
⋯ ⋯
苹果公司的探索表明,隐私保护与AI性能并非零和博弈。通过差分隐私与合成数据的技术融合,苹果正在构建一个用户主权AI的新范式。
数据价值由用户掌控,模型进化以隐私为边界。这场静悄悄的技术革命,或许比任何AI功能的炫技更能定义未来。
出其不意,攻其不备,这是获得胜利的关键。当其他公司还在争论数据收集的底线时,苹果已用数学公式和芯片架构给出了答案:真正的智能,从尊重隐私开始。
(文:陳寳)