

导读
随着大语言模型角色扮演能力的提升,越来越多的学者将大语言模型引入到社会科学研究中,在模拟社会调查、评估传播效果、仿真政治行为等场景都取得了正面的结果。现有的研究存在两个局限性:(1)泛化能力不足。当前研究聚焦在某个特定场景/任务,方法和结论难以推广和复用。(2)可扩展性不佳。当前的研究往往以大语言模型为中心设计模拟过程,缺乏系统性的视角,难以扩展到更复杂场景。
大规模社会模拟通过构建现实世界的参照,达到建模目标群体的行为模式、预测群体事件的演化趋势、辅助现实重大决策的目的。社会模拟研究的核心问题在于模拟过程如何做到与现实世界的“对齐”。基于此,复旦大学交叉学科团队联合上海创智学院、罗切斯特大学、小红书提出了一种面向社会模拟的世界模型 SocioVerse,首次提出从环境、目标用户、交互机制和行为模式四个维度的“对齐”理念,并设计了包含社会环境、用户引擎、场景引擎和行为引擎的对齐框架,构建了1000万真实人口池,以实现高精度、系统性、可泛化的大规模社会模拟。
SocioVerse 在美国总统大选、新闻热点传播、社会经济调查三个场景中展现出高精度的对齐效果。项目开源100万英文社交媒体平台的用户池,推出众生 · SocioVerse社会调查模拟平台,提供在线社会模拟仿真,助力交叉学科研究。
-
众生 · SocioVerse项目地址:http://www.fudan-disc.com/socioverse/(点击文末阅读原文访问并试用)
-
论文:https://arxiv.org/abs/2504.10157
-
评测仓库:https://github.com/FudanDISC/SocioVerse
-
用户池地址:https://huggingface.co/datasets/Lishi0905/SocioVerse
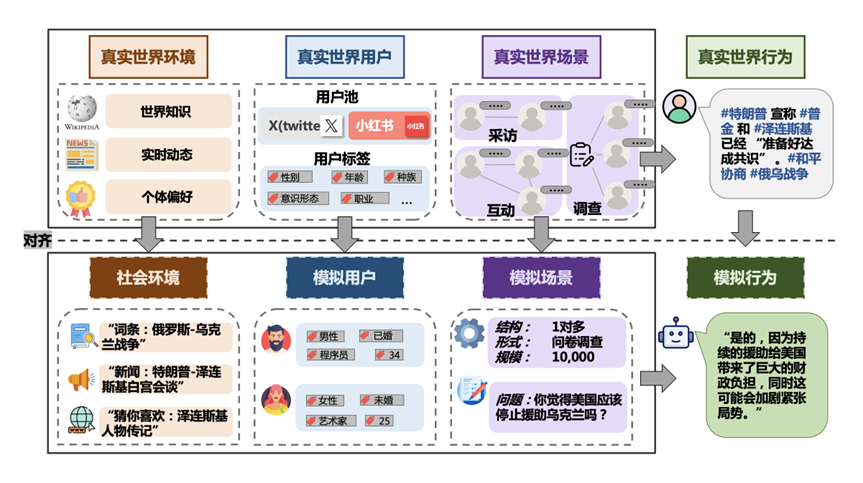
SocioVerse在俄乌冲突事件中的模拟流程示例。本文提到的关于环境、用户、场景和行为的对齐问题都被较好地考虑和处理到。
社会模拟的关键挑战:对齐
为了理解人类在社会情境中的行为,传统方法通常采用如问卷、访谈和行为观察等方式,但是面临着高成本、小样本和伦理问题等限制。因此,社会模拟作为替代手段逐渐兴起,运用数学建模、大数据分析等方法,通过构建智能体模拟观察个体决策如何汇聚成群体行为。随着大语言模型的发展,智能体的推理与互动能力显著增强,从而能够构建更加真实和复杂的社会模拟。然而,现有方法在与真实世界对齐时仍面临四个关键挑战:
-
1. 环境对齐:如何使模拟环境与实时发生的现实世界事件同步。
-
2. 用户对齐:如何精准对齐模拟智能体与目标用户的特征与分布。
-
3. 互动机制对齐:如何设计统一、可扩展的互动方式来匹配现实中的交流模式。
-
4. 行为模式对齐:如何确保智能体生成的行为能真实反映用户群体的多样性和偏好。
为此,我们提出了 SocioVerse,一个由大模型智能体驱动的大规模社会模拟世界模型,具备四个对齐模块,并配备一个包含一千万真实用户的池。我们在政治、新闻和经济三大场景中验证其有效性,结果显示 SocioVerse 能够高效、可信地模拟大规模群体行为。
SocioVerse框架
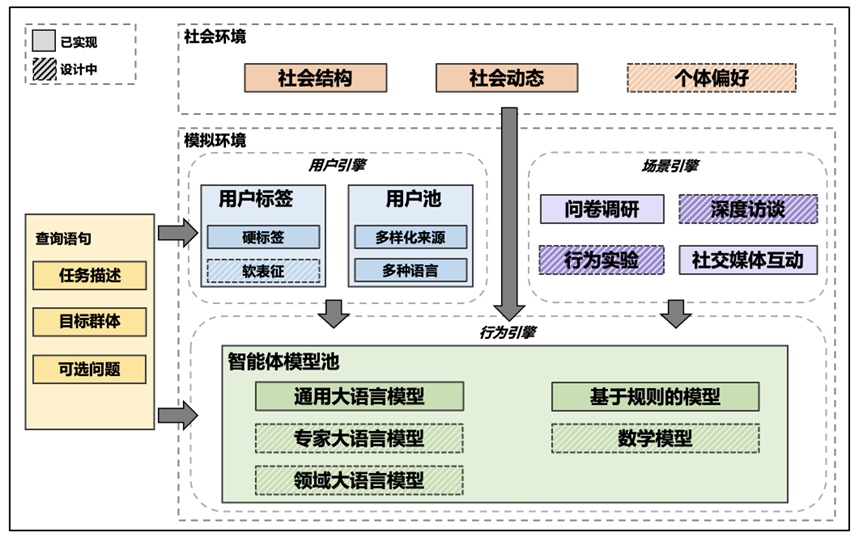
SocioVerse框架示意图,包含四个强大的对齐组件。社会环境为模拟提供了事实的上下文信息。在模拟过程中,行为引擎接受来自用户引擎和场景引擎的用户画像信息和模拟场景设定,结合社会环境提供的信息生成针对查询语句的模拟结果。
SocioVerse的整体框架包括四部分:社会环境模块、用户引擎、场景引擎、行为引擎。
1. 社会环境模块
-
作用:为模拟注入最新事件、社会统计与偏好内容,使模拟环境与现实环境对齐,帮助智能体对当前社会背景作出合理反应。
-
组件:
-
Updated Events(事件更新):构建带时间戳的新闻事件库、事件词条库,供LLMs检索与引用,实现事件轨迹追踪与情境还原。
-
Social Statistics(社会统计):提供结构化数据,如人口分布、城市结构与社会习俗,使智能体行为更符合所在的群体特征。
-
Preference Content(偏好内容):通过推荐系统为不同智能体推送兴趣相关内容,提升行为生成的多样性和个性化。
2. 用户引擎
-
作用:根据真实用户采样模拟样本,构建复杂的目标用户画像,确保模拟智能体的人群特征与现实分布对齐。
-
组件:
-
User Pools(用户池):使用来自 X 和 Rednote 等平台的历史发言构成 1000 万用户的大规模池。
-
User Labels(用户标签):结合了可标注的硬标签(如性别、年龄)与可训练的软表征向量。其中,硬标签利用多个LLM进行初步标注,人工校验后训练分类器,实现15类人口属性的自动推断(如种族、政党、性格等)。
3. 场景引擎
-
作用:将模拟场景与真实场景对齐,根据任务类型设计相应的交互结构,并按人口分布将模拟推广至大规模群体。
-
组件:
-
Questionnaire(问卷):1对多的单轮结构,用于收集大规模样本对某一话题的观点意见(如选举、民意调查)。
-
In-depth Interview(深入访谈):1对1多轮交互,便于挖掘受访者的态度动机,适用于用户体验与心理研究。
-
Behavior Experiment(行为实验):1对多或多对多结构,在控制条件下观测个体与群体的决策行为与社会偏差。
-
Social Media Interaction(社交互动):多对多场景下构建多智能体的动态发帖与评论,模拟舆情演化、信息扩散与网络影响。
4. 行为引擎
-
作用:在模拟过程中结合用户画像、场景结构与社会背景,驱动智能体生成合理的模拟行为,确保其行为模式与真实用户群体对齐。
-
组件:
-
LLM Agents(大模型智能体):包括三类(1)通用型LLM:如GPT或Qwen,通过提示对齐用户画像;(2)专家型LLM:为特定领域微调,用于生成专业行为;(3)领域LLM:应对复杂任务或知识密集型模拟。
-
Traditional ABM(传统建模智能体):基于规则或数学模型,通过启发式或理论函数实现交互,适合低影响力的边缘用户建模,具有效率优势。
千万真实用户池
1. 数据收集
用户池的数据主要来自多个社交媒体平台,如 X(原Twitter) 和 Rednote(小红书),涵盖不同语言、文化与年龄层的用户群体。为了保障用户隐私,数据仅包含公开可见的内容,如文本、互动行为(点赞、评论、转发)等。在构建过程中,通过设定文本重复率阈值,可以识别并剔除机器人与广告账户,从源头保障数据质量。按用户索引并清洗后的数据构成如下:

2. 人口统计学标注
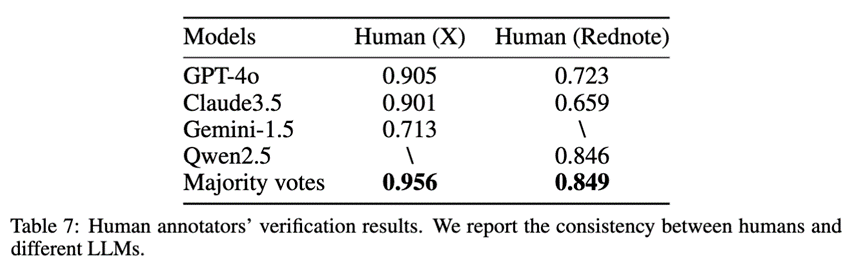
由于用户的人口统计信息无法直接获取,我们设计了一个人口属性标注系统,用于推断和标注用户特征。该流程首先由多个大语言模型作为初始标注器,对用户在多个人口统计维度上进行分类。随后,人类标注员对LLM生成的标签进行评估与修正,从而确保用户标签数据集的可靠性。经过人工审核后的数据集将用于训练人口属性分类器,从而以成本较低的方式支持大规模的自动标注。具体而言,我们在15个人口统计维度上对用户进行了标注,包括:年龄、性别、职业、种族、收入、教育水平、居住类型、地区、就业状态、婚姻状况、宗教信仰、政党倾向、意识形态、大五人格特质(BigFive)以及兴趣爱好。每一项属性均由对应子数据集训练的专用分类器进行推断。在小红书和X数据上经过如上标注流程后,各个标注模型与人类标注的一致性如下表所示:
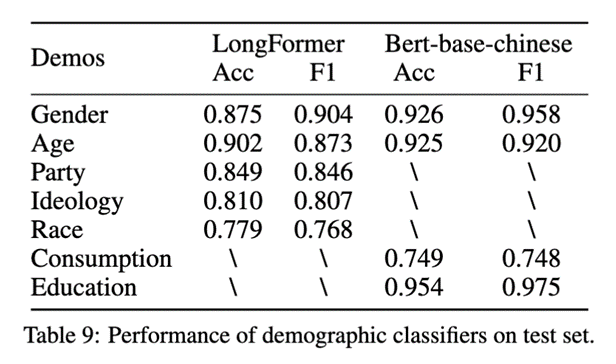
在标注器训练部分,我们采用多个大语言模型(LLM)之间多数投票的标签结果来构建训练数据集。鉴于不同平台所使用的主流语言存在差异,我们在X平台的数据上使用 LongFormer 模型,在Rednote平台的数据上使用 Bert-base-chinese 模型。最终标注器在测试集的各个人口统计学特征中的标注表现如下:
场景模拟实验
三个场景模拟实验的示意图
我们在三个场景模拟实验中测试了SocioVerse的性能表现。当前,三个场景实验均为基于问卷的单轮调查模拟。
-
美国总统选举预测:按1/1000采样全美51个州的人口进行选举投票预测,模拟30w智能体的投票结果。
-
热点新闻反馈模拟:从社交媒体中采样对科技领域感兴趣的目标人群,模拟1w用户对ChatGPT(生成式人工智能)的问世的观点态度。
-
中国国民经济调查:从中国31个省级行政区(除港澳台外)中按人口比例采样,模拟共1.6w智能体日常各项消费支出的水平。
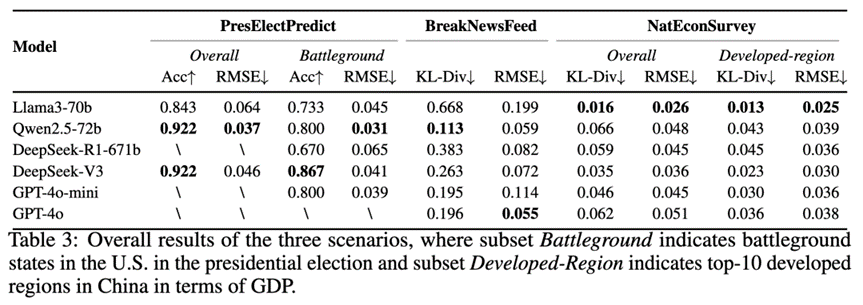
1. 整体实验结果:SocioVerse可以支持多样且精确的大规模社会模拟
-
总统选举预测:模拟结果能准确还原美国总统选举的州级结果,尤其在“赢家通吃”规则下能准确预测90%以上的州的选举结果,呈现出对现实宏观格局的高度还原。DeepSeek-V3与Qwen2.5-72b在准确率和RMSE上表现优异,而DeepSeek-R1-671b 则存在“过度思考”导致偏差的情况。
-
热点新闻反馈:各模型对公众态度的模拟与真实用户群体表现一致。Qwen2.5-72b 在KL散度和NRMSE两个评价维度上与真实用户的态度一致性分别达到83%和70%,能较准确捕捉传播效果与观点分布。
-
国民经济调查:所有模型在模拟各地区消费支出时均接近真实统计数据,尤其在发达地区表现更佳。Llama3-70b 在该场景中表现最强,在所有地区和发达地区与真实居民的消费一致性分别达到69%和76%,说明 SocioVerse 能有效模拟用户在经济决策中的行为模式,特别是在发达地区。
2. 拓展分析:先验的人口统计学分布与真实世界经验显著提升了选举预测精度
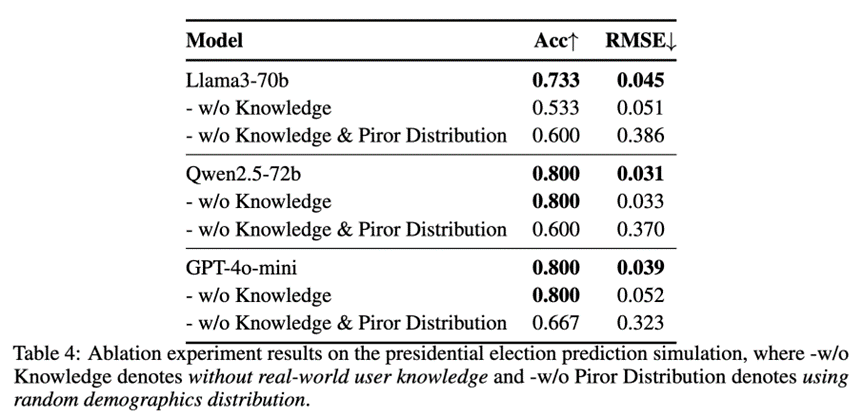
在总统选举模拟中,我们通过消融实验评估“真实用户知识”和“先验人口分布”的作用。结果表明先验分布显著提升了预测精度,而随机分布下模型准确率明显下降。同时,历史发言数据可提升细粒度性能,尤其是在RMSE方面表现明显。这说明SocioVerse框架中的两项关键输入——先验分布与用户知识——对于提升模拟的现实对齐性至关重要。
3. 拓展分析:热点新闻反馈模拟中的群体偏好与观点能被有效还原
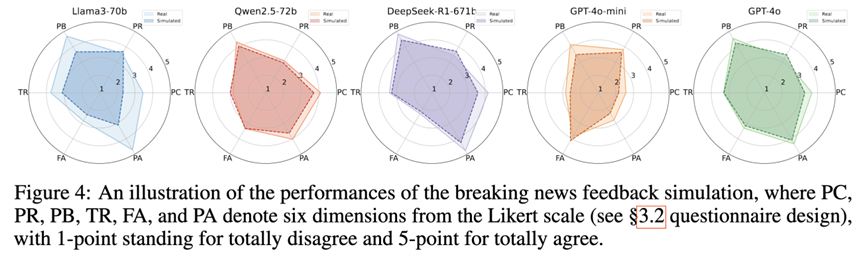
在 ChatGPT问世事件的反馈模拟中,我们将观点问卷量化为六个维度的1–5 分Likert 量表,并将模拟结果与真实用户群体逐项比对。结果表明,多数模型在六个维度(公众认知PC, 感知风险PR, 感知利益PB, 信任度TR, 公平性FA, 公众接受度PA)上均与真实用户高度一致。同时,也需要注意,所有模型的模拟回答整体偏保守,暗示着模拟中可能存在一定由于LLM引入的偏差风险。
4. 拓展分析:模型在经济调查中对不同领域的模拟表现差异显著
在全国经济调查中,模型需预测共八项月度消费支出。结果表明:所有模型在大多数维度上与真实数据高度一致,尤其在“日用品”维度表现最优。在“住房支出”这一复杂领域,各模型误差普遍偏大,说明 LLM 对高复杂经济行为的模拟仍具挑战。Llama3-70b 在整体表现上优于其他模型,说明其在高稳定性场景中更具优势。
SocioVerse大规模社会调查模拟平台
平台功能介绍与视频
SocioVerse大规模社会调查模拟平台基于大模型智能体与千万级真实人群数据库,突破传统调研的时空与成本限制,支持复杂社会现象的动态推演,帮助学术研究、政策制定、商业分析等领域用户快速获取群体行为反馈。
复旦大学数据智能与社会计算实验室
Fudan DISC
联系方式:disclab@fudan.edu.cn
地址:复旦大学邯郸校区计算中心

点击“阅读原文”跳转至项目地址试用SocioVerse
关于我们

(文:机器学习算法与自然语言处理)