
SD-LoRA团队 投稿
量子位 | 公众号 QbitAI
彻底摆脱传统方法对旧数据存储的依赖!
哈佛团队联手香港城大、西安交大最新发布的SD-LoRA技术,通过固定已学习任务的方向参数,仅调整幅度权重,完全避免了历史数据的存储需求。
能够在减少50%以上参数存储的同时保持最高准确率,并且在不增加推理开销的前提下显著缓解了灾难性遗忘问题。
该研究成果已被 ICLR 2025 接收为Oral Presentation。

作者针对预训练模型的持续学习,不同于之前⼴泛采⽤的混合专家模型的思路(将CL的瓶颈转化为选择准确的对应专家模型), 本⽂提出的SD-LoRA算法逐步引入低秩矩阵,通过分解其⽅向和幅值,在提升持续学习性能的同时,实现了更好的参数效率。
同时,本⽂也从low-loss path的角度出发,⾸次对该类⽅法的有效性进⾏了深入解释和理论分析,为理解基于预训练模型的持续学习提供了新的视角。
论文亮点
作者提出了⼀种⾯向预训练⼤模型的持续学习⽅法SD-LoRA,具备⽆需回放(rehearsal-free)、推理⾼效、可端到端训练等优点,并进⼀步设计了两个参数更⾼效的变体。
从理论与实证层⾯深入分析了SD-LoRA的⼯作机制,解释其如何避免依赖任务特定模块的选择(Prompt或者LoRA) ,为持续学习提供了新的解决思路和⽅案。
在多个持续学习基准与主流预训练模型上进⾏了全⾯实验评估,验证了所提⽅法在准确率与效率上的优越性。
背景
持续学习:假定有 个流式任务
个流式任务 ,第
,第 个任务的训练集表示为
个任务的训练集表示为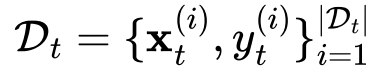 ,其中
,其中 表示输入图像,
表示输入图像,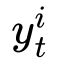 为对应的标签。当训练到第个任务时,前
为对应的标签。当训练到第个任务时,前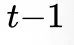 个任务的数据已无法获取,对应的训练目标函数为:
个任务的数据已无法获取,对应的训练目标函数为:

其中, 表示分类模型,
表示分类模型, 为逐样本的交叉熵损失。
为逐样本的交叉熵损失。
LoRA:令分类模型 的某一层参数为
的某一层参数为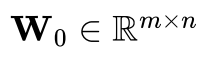 ,模型更新参数为
,模型更新参数为 ,其中矩阵
,其中矩阵 ,那么该层对应的输出为:
,那么该层对应的输出为:

研究动机
作者总结现有研究发现,当前基于预训练模型的持续学习⽅法,如prompt-based和LoRA-based⽅法,通常在训练和测试阶段采⽤路由机制选择对应的任务特定模块,借此缓解灾难性遗忘问题。
这类⽅法本质上沿⽤了“混合专家模型(MoE)”的思路。
然⽽,为了精准选择对应专家模块,路由机制往往依赖于⼤量历史任务的样本或中间特征,带来了较⾼的存储成本。
这不仅违背了持续学习在多任务场景下对“轻量化”的要求,还在推理阶段引入了额外计算,降低了推理效率。

△表1:从Rehearsal-free,Inference Efficiency以及End-to-end Optimization的角度对现有⽅法的分析。
HiDE-Prompt和InfLoRA性能表现优异,但是他们都需要存储⼤量过去任务样本的特征。⽽L2P、DualPrompt、CODA-Prompt则需要引入路由机制选择对应的task-specific的prompt,这在模型推理的时候引入了新的计算量。
作者希望能够设计探索⼀种MoE逻辑之外的基于预训练模型的持续学习算法:
-
满⾜Rehearsal-free,Inference Efficiency,和End-to-end Optimization三个特征,使得在多任务持续学习场景下,避免存储过多过去任务样本及特征,提升推理效率。
-
从实验和理论两个维度深入分析模型缓解灾难性遗忘的内在机制,为持续学习问题提供⼀种不同于现有专家选择策略的新解法。
SD-LoRA方法
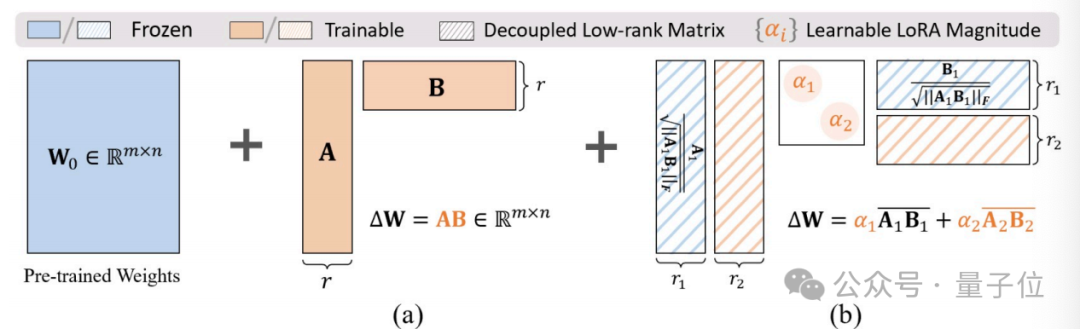
△图1:模型参数更新,(a)传统LoRA,(b)所提的SD-LoRA(以训练到第2个任务为例)
本⽂所提的SD-LoRA算法主要包含两个模块:
-
将LoRA矩阵的magnitude
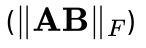 和direction
和direction 解耦出来,
解耦出来,

-
固定之前任务所学习的LoRA矩阵的⽅向,但是同时学习调整对应magnitude。其中橙⾊的部分为learnable的部分。

实验结果发现SD-LoRA在满⾜rehearsal-free,Inference Efficiency,End-to-end Optimization的同时也取得了很好的性能表现。
为了更好的解释SD-LoRA的实验性能,下⾯我们将分别从实验及理论两个角度进⾏了深入分析,从low-loss path的角度对SD-LoRA提供了新的解释。
Empirical Finding 1:(Low-loss Region的存在性):当直接在不同下游任务上微调基础模型时, 得到的任务特定权重之间的距离,比它们与原始模型权重的距离更接近。
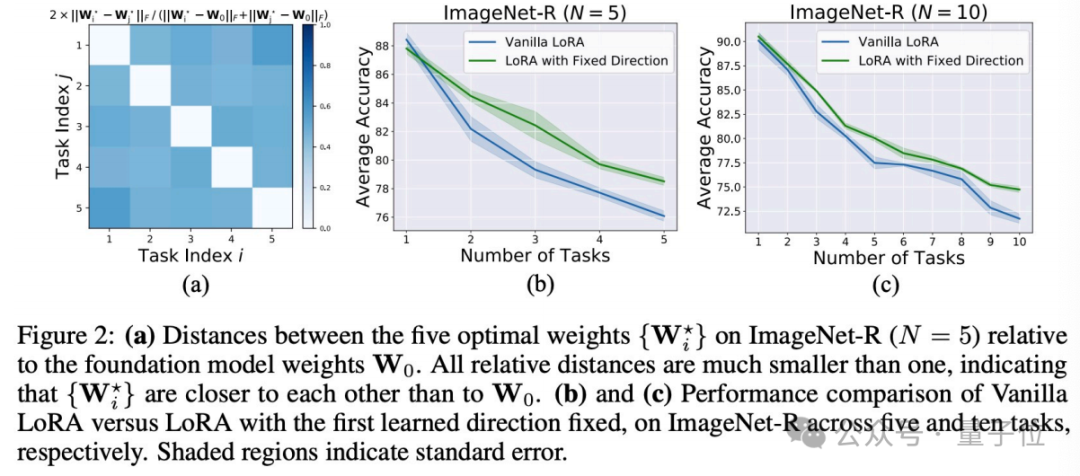
(a). 表示预训练模型的权重,
表示预训练模型的权重, 表示模型直接在第
表示模型直接在第 个任务上finetune所得到的参数。(a)图表明参数空间中测量相对距离,这些下游任务特定的权重彼此之间的距离相比于基础模型初始权重更加接近,呈现出聚集趋势。
个任务上finetune所得到的参数。(a)图表明参数空间中测量相对距离,这些下游任务特定的权重彼此之间的距离相比于基础模型初始权重更加接近,呈现出聚集趋势。
(b)(c).在训练完第一个任务后,我们固定其方向 ,只调整magnitude去学习,即
,只调整magnitude去学习,即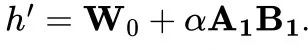 可见其性能甚至优于Vanilla LoRA,说明对所有任务最优的参数可能位于方向附近,仅通过调整magnitude即可学到。进一步说明了下游任务模型最优参数可能位于一个low-loss region里。
可见其性能甚至优于Vanilla LoRA,说明对所有任务最优的参数可能位于方向附近,仅通过调整magnitude即可学到。进一步说明了下游任务模型最优参数可能位于一个low-loss region里。
Empirical Finding 2:(可学习参数 的可视化):在持续学习过程中,来自先前任务的方向(即
的可视化):在持续学习过程中,来自先前任务的方向(即 )起到了关键作用——尤其是早期任务中学到的方向。
)起到了关键作用——尤其是早期任务中学到的方向。

(a).我们首先计算了当前任务方向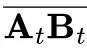 与之前任务方向集合之间的最小二乘拟合残差。结果显示该残差随时间逐渐增大,说明在训练初期,新学到的方向与早期任务高度对齐,可以有效复用已学习的方向;随着训练的推进,逐渐偏离,逐步引入细微变化以适配新任务。
与之前任务方向集合之间的最小二乘拟合残差。结果显示该残差随时间逐渐增大,说明在训练初期,新学到的方向与早期任务高度对齐,可以有效复用已学习的方向;随着训练的推进,逐渐偏离,逐步引入细微变化以适配新任务。
(b)(c).早期任务对应的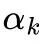 值迅速上升,而后期任务则呈现出整体下降趋势。这表明模型在推理过程中越来越依赖于早期学习到的方向,而新引入的方向主要用于轻微调整,以满足后续任务的特定需求。
值迅速上升,而后期任务则呈现出整体下降趋势。这表明模型在推理过程中越来越依赖于早期学习到的方向,而新引入的方向主要用于轻微调整,以满足后续任务的特定需求。
Empirical Finding 3:(模型缓解遗忘的假设及验证):SD-LoRA通过结合先前任务中固定的方与学习到的magnitude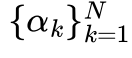 ,有效地挖掘出一条low-loss path,指向所有任务共享的低损区域。
,有效地挖掘出一条low-loss path,指向所有任务共享的低损区域。
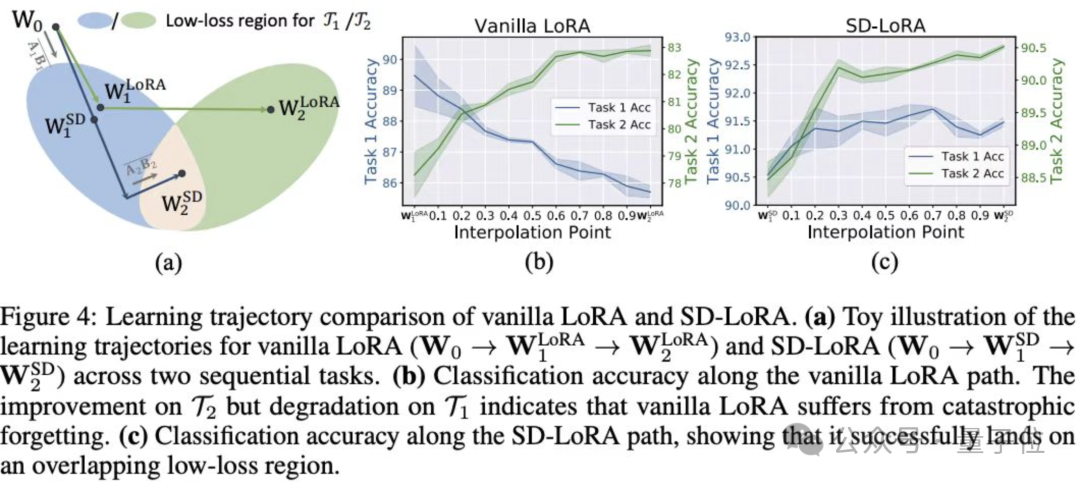
(a).SD-LoRA算法有效的假设,通过调整magnitude,模型更加容易找到low-loss path从而收敛到shared low-loss region。
(b)(c).分别对LoRA和SD-LoRA进行插值,验证了(a)假设,SD-LoRA相对LoRA,在维持task 1性能的同时,有效的提升了task 2的性能,说明了SD-LoRA收敛到了shared low-loss region。
理论分析

我们从矩阵逼近的角度分析,令 表示CL最优的模型参数。随着训练的进行,学习得到的矩阵
表示CL最优的模型参数。随着训练的进行,学习得到的矩阵 会逐渐逼近的主成分。
会逐渐逼近的主成分。
这也印证了finding 2中模型所学习到的 逐渐下降的趋势。
逐渐下降的趋势。
SD-LoRA的高效版本
尽管所提SD-LoRA算法避免了存储过去任务的样本及特征,但仍需要存储不同任务LoRA矩阵的方向信息,为了进一步实现理想的可扩展的持续学习算法,我们在SD-LoRA的基础上提出了两个efficient的版本。
(SD-LoRA-RR)。我们在theoretical和finding 2都证实了后面引入的LoRA matrix不如前面的重要。基于此,我们动态的降低了后续引入LoRA矩阵的rank,从而降低了需要存储的LoRA矩阵的参数量。

(SD-LoRA-KD)。尽管SD-LoRA-RR可以降低存储的LoRA矩阵的参数量,但是他还是不可避免的在训练新任务时引入新的低秩矩阵。SD-LoRA-KD通过判定新引入LoRA矩阵方向信息是否冗余,将知识蒸馏到之前所学习到的LoRA矩阵上,从而避免了引入新的矩阵。

SD-LoRA及其efficient版本相应的伪代码如下:

实验结果
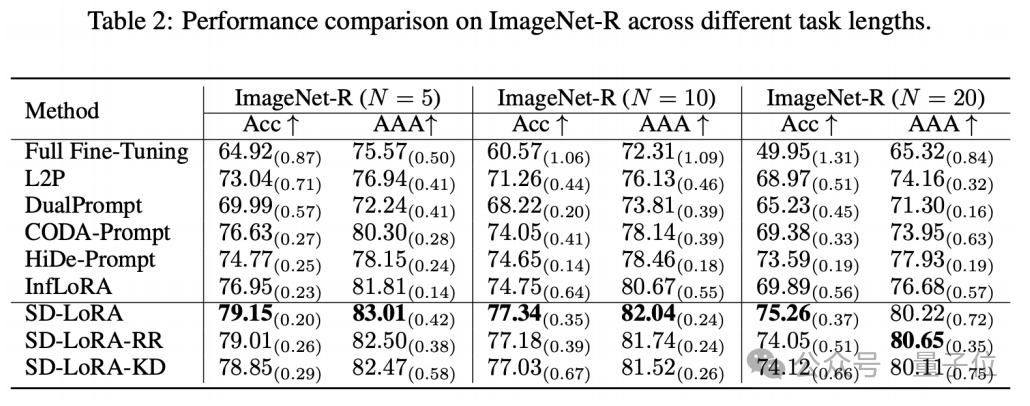
1.:SD-LoRA在不同的任务长度,benchmarks上的性能。

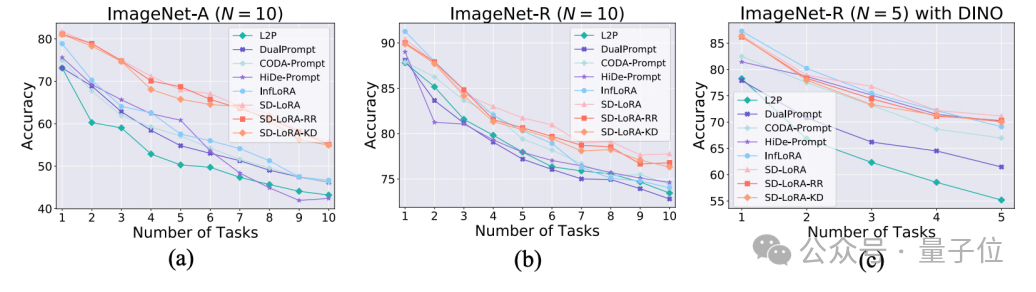
2.:SD-LORA在训练过程中的多个任务的平均性能。
3.:SD-LORA的消融实验。

4.:不同方法的复杂度分析。

结论
本文提出的SD-LoRA是一种rehearsal-free、推理高效、可端到端优化的持续学习方法。
不同于以往依赖混合专家模型的做法,SD-LoRA通过逐步引入低秩矩阵,并将其方向与幅值分解,实现了参数高效、无路由机制的持续学习。
在多个基准任务和预训练模型上的实验表明,SD-LoRA在不增加推理开销的前提下显著缓解了灾难性遗忘问题。
同时,本文还从经验和理论两个角度深入分析了SD-LoRA的工作机制,揭示了其能有效挖掘不同任务共享低损路径的本质,提供了一种全新的持续学习解决思路。
论文地址:
https://openreview.net/pdf?id=5U1rlpX68A
代码地址:
https://github.com/WuYichen-97/SD-Lora-CL
本文第一作者Yichen WU (个人主页:https://wuyichen-97.github.io/) 正在找关于Continual Learning, LLM Hallucination等相关领域的Postdoc Postion, 欢迎大家有合适岗位联系: yichen@seas.harvard.edu
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!
— 完 —
学术投稿请于工作日发邮件到:
ai@qbitai.com
标题注明【投稿】,告诉我们:
你是谁,从哪来,投稿内容
附上论文/项目主页链接,以及联系方式哦
我们会(尽量)及时回复你

🌟 点亮星标 🌟
(文:量子位)