

极市导读
阿里巴巴与浙江大学联合提出的CMMCoT框架,为复杂多图像理解任务注入“慢思考”能力,融合多模态推理链与记忆增强机制,大幅提升模型的跨图像推理与可解释性能力。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
在多模态大语言模型(MLLMs)领域,单图像理解任务已取得显著进展,但面对复杂的多图像场景,现有的模型往往力不从心。近日,来自阿里巴巴集团和浙江大学的联合团队在arXiv上发布了一篇题为《CMMCoT: Enhancing Complex Multi-Image Comprehension via Multi-Modal Chain-of-Thought and Memory Augmentation》的论文,提出了一种创新框架——Complex Multi-Modal Chain-of-Thought (CMMCoT) ,为多图像理解任务注入了“慢思考”能力,显著提升了模型在复杂场景下的推理性能。
论文链接:https://arxiv.org/pdf/2503.05255
代码地址:https://github.com/zhangguanghao523/CMMCoT
研究动机:
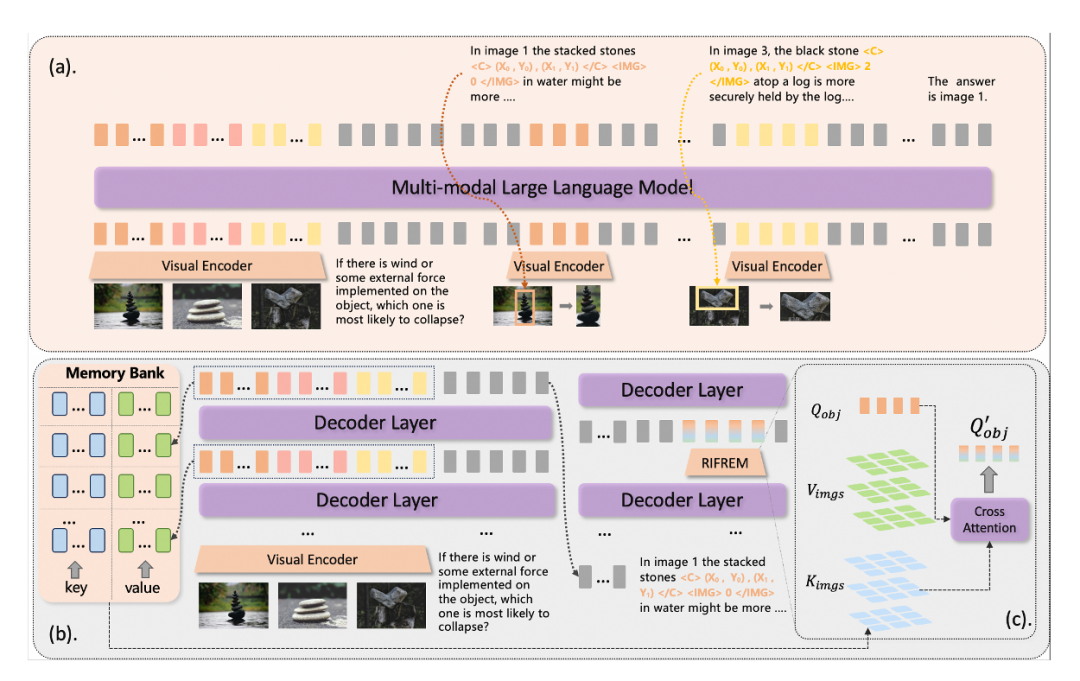
人类在处理多图像任务时,往往通过跨图像的视觉对比和关键视觉概念的动态记忆来进行复杂推理。然而,现有MLLMs多依赖文本主导的中间推理过程,缺乏对视觉信息的深度挖掘和跨图像关联能力的支持,尤其在多图像场景下表现受限。论文指出,当前模型在复杂多图像任务中存在两大痛点:一是忽略跨模态数据中的潜在证据特征,导致预测错误;二是决策过程缺乏可解释性,影响模型在关键应用中的可靠性。受人类双重认知机制(视觉信号解读与文本推理的协同)的启发,研究团队提出CMMCoT框架,旨在模拟人类“慢思考”过程,结合具体图像区域和文本进行联合推理,提升多图像理解能力,过程如图所示:
新数据集的构建:
为了支持多图像复杂推理任务的研究,团队构建了一个全新的数据集——CMMCoT-260K,包含26万条精心标注的数据实例。该数据集基于GRIT、Flickr30k-Entities、VoCoT和Mantis等多个现有资源,涵盖四种数据类型:Caption(描述)、Co-reference(共指)、Comparison(对比)和Reason(推理),旨在训练模型在多图像场景下的语义解析、实体一致性识别及逻辑推理能力。与传统数据集不同,CMMCoT-260K的独特之处在于每条数据都附带明确的推理链,结合空间坐标和实体图像,支持多层次推理分析。
本文创新点:
本工作的核心是CMMCoT框架,一个多步推理系统,基于Qwen2-VL模型(一个强大的视觉语言基线)进行优化。方法设计灵感来源于人类认知,分为训练和推理两个阶段,引入两个关键创新:
-
交错的多模态推理链:AI在推理时,不再只输出文本,而是生成交替的文本-视觉序列。例如,遇到一个多图像问题,AI会先输出文本描述(如“图像1中的石头堆”),然后用坐标标记关键区域(如< C > (X_min, Y_min), (X_max, Y_max) < /C >),并提取对应的视觉标记(通过视觉编码器)。这模仿人类“看-想-比”的过程,避免了纯文本推理的局限。训练时,采用两阶段策略:先在CMMCoT-260k上专注多图像训练,再混合通用数据集,防止“灾难性遗忘”(即专注新任务后忘记旧技能)。
-
测试时记忆增强模块(RIFREM):推理过程中,AI需要“记住”跨图像特征,但参数膨胀会增加成本。论文引入RIFREM(Retrieval-based Image Feature Reasoning Enhancement Module),一个高效的记忆库机制。在推理时,AI存储多图像的键-值对(Key-Value),当遇到关键坐标时,通过注意力机制从记忆库中检索相关特征,实现跨图像特征挖掘。简单说,就像AI有个“备忘录”,能动态调用图像细节进行比较,而不需额外参数。
这个框架的关键是平衡性能和效率:训练时监督视觉推理,推理时通过RIFREM增强跨模态互动,让AI在多图像任务中更“聪明”。
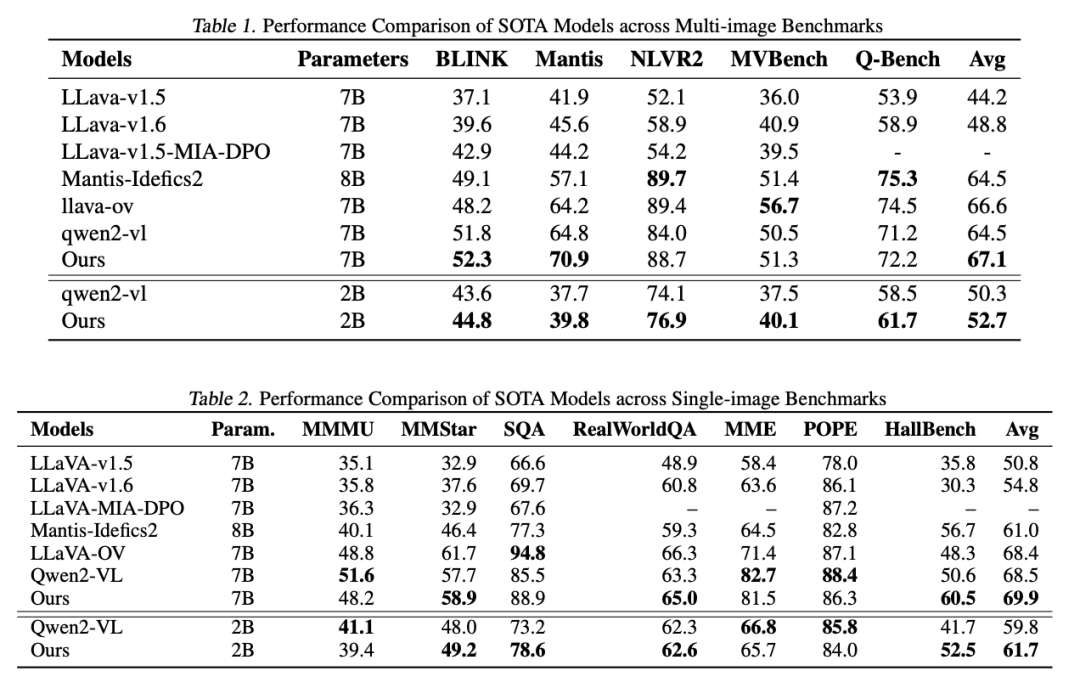
论文在多个多图像和单图像基准测试上验证了CMMCoT的优越性。在多图像任务中,CMMCoT-7B模型在Mantis-Eval(70.9)、NLVR2(88.7)等基准上取得了领先成绩,平均性能比Qwen2-VL提升2.6个百分点;即使是参数更少的2B版本,也在多图像逻辑分析和视觉-文本验证任务中展现出强大竞争力。在单图像任务中,CMMCoT同样表现出色,在MMMU、MMStar等数据集上的平均性能达到69.9,超越了同规模的现有模型。
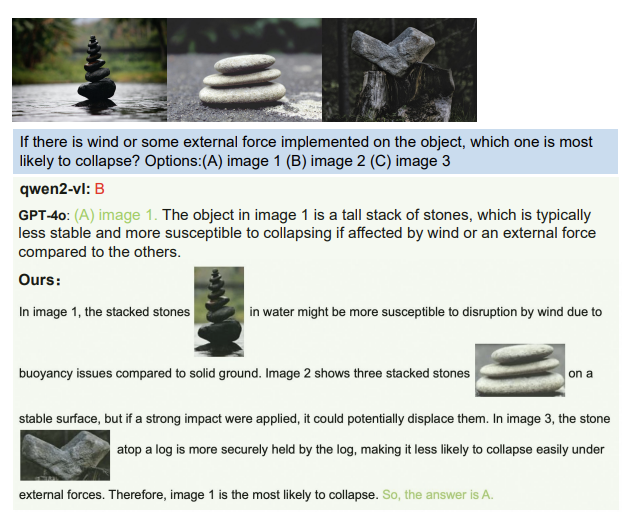
消融实验进一步揭示了各组件的贡献:结合坐标信息与实体图像显著提升了模型性能,而RIFREM模块在推理阶段带来了额外的性能增益。案例分析显示,CMMCoT在空间推理、对象检测及逻辑异常检测等方面均优于GPT-4V和Qwen2-VL,展现出更高的准确性和可解释性。在可视化示例中,可以看到本文提出的模型能够对图像中关键物体的特性,数量,逻辑性等结合文本进行深入分析,并把相关视觉区域可视化在推理过程中,这不仅能够提高模型的推理效果,还能进一步提高可解释性。



(文:极市干货)