

还记得两个月前那个引爆 Github 的 VLM-R1 吗?上线 12 小时狂揽 2000+ Star,48 小时冲上趋势榜第一,连 AI 大佬们都直呼这框架有点东西!如今,它的官方技术报告终于来了!
这篇被全球开发者催更两个月的硬核说明书,首次完整揭秘了 VLM-R1 如何用强化学习颠覆视觉语言模型——从 Reward Hacking 的破解妙招,到让模型突然开窍的 OD Aha Moment,再到 7B→32B 参数下的 Scaling Law 验证… 每一个细节都堪称 RL 在视觉任务中的教科书级实践。
今天,我们就带大家逐帧拆解这份技术报告,看看 VLM-R1 凭什么能吊打传统 SFT,甚至被业界称为视觉 AGI 的关键拼图。
论文、代码和 Demo 体验地址如下:

论文标题:
VLM-R1: A Stable and Generalizable R1-style Large Vision-Language Model
论文地址:
https://arxiv.org/pdf/2504.07615
代码地址:
https://github.com/om-ai-lab/VLM-R1
Demo体验:
https://huggingface.co/spaces/omlab/VLM-R1-Referral-Expression

视觉感知任务引入GRPO
VLM-R1 专注于视觉感知任务,选取了 Referring Expression Compression (REC) 以及 Open-Vocabulary Object Detection (OVD) 两个任务,设计了规则奖励系统并成功运行 GRPO 算法。
整体的框架设计如下:
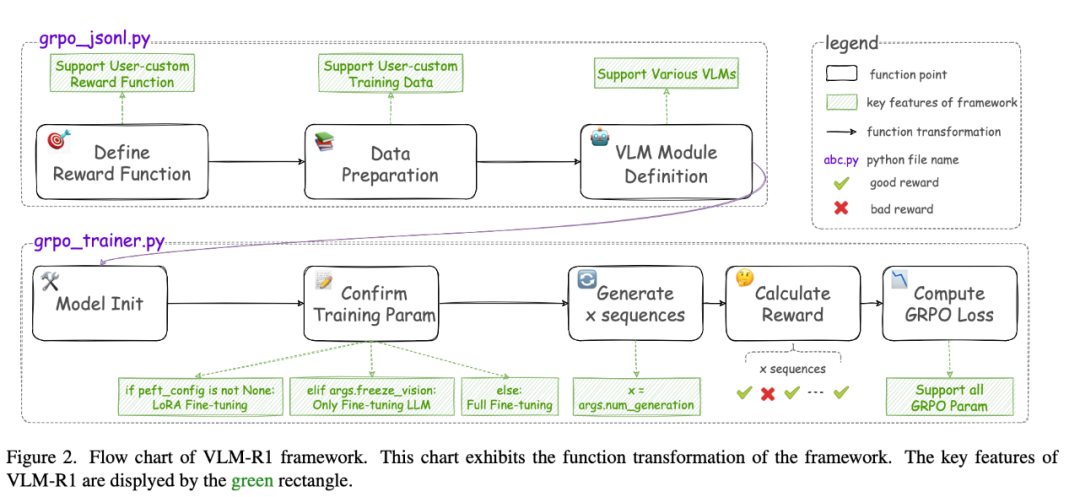
在奖励系统的设计上,VLM-R1 引入了两种奖励机制:格式奖励和准确率奖励 。前者确保模型输出符合指定格式,后者则衡量模型预测结果与真实标注的一致性。训练层面,VLM-R1 支持经典的 GRPO 算法,并兼容多种高效训练方式,如 LoRA 微调和视觉模块冻结等,满足不同场景下的需求。
与传统监督微调(SFT)方法相比,VLM-R1 在多项指标上均表现出显著优势:
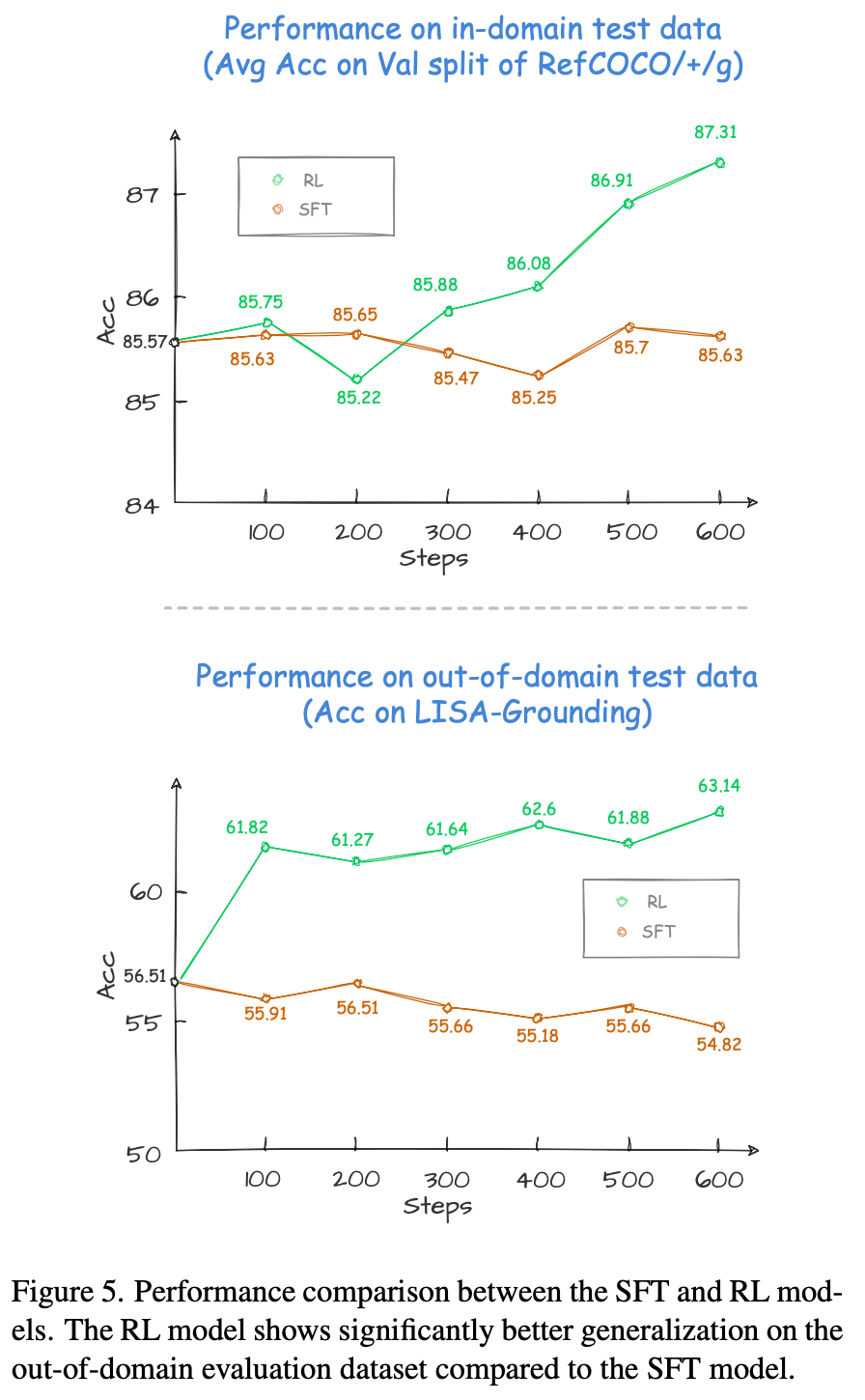
具体而言,在域内测试数据中,随着训练进行,SFT 相较于原始模型的提升始终较为有限,而 RL 则始终保持稳定的性能增长。
此外,在域外测试数据中,SFT 模型的性能会随着训练的深入而略有下降,而 RL 模型则有效将其推理能力泛化至新任务。实验结果充分证明了强化学习在提升 VLM 推理能力和泛化能力方面的巨大潜力。

深入探究视觉任务上的RL特性
与 LLM 上的 RL 一样,VLM-R1 在视觉任务中也展现出了一致的特性:
Reward Hacking:在 OVD 任务中,使用官方的 AP 值作为奖励函数时,模型倾向于预测所有可能的类别以追求更高的奖励分数,导致冗余输出的问题。
为了解决这一现象,VLM-R1 设计了 odLength 奖励机制 ,通过惩罚多余预测,有效抑制了这种 reward hacking 的行为。
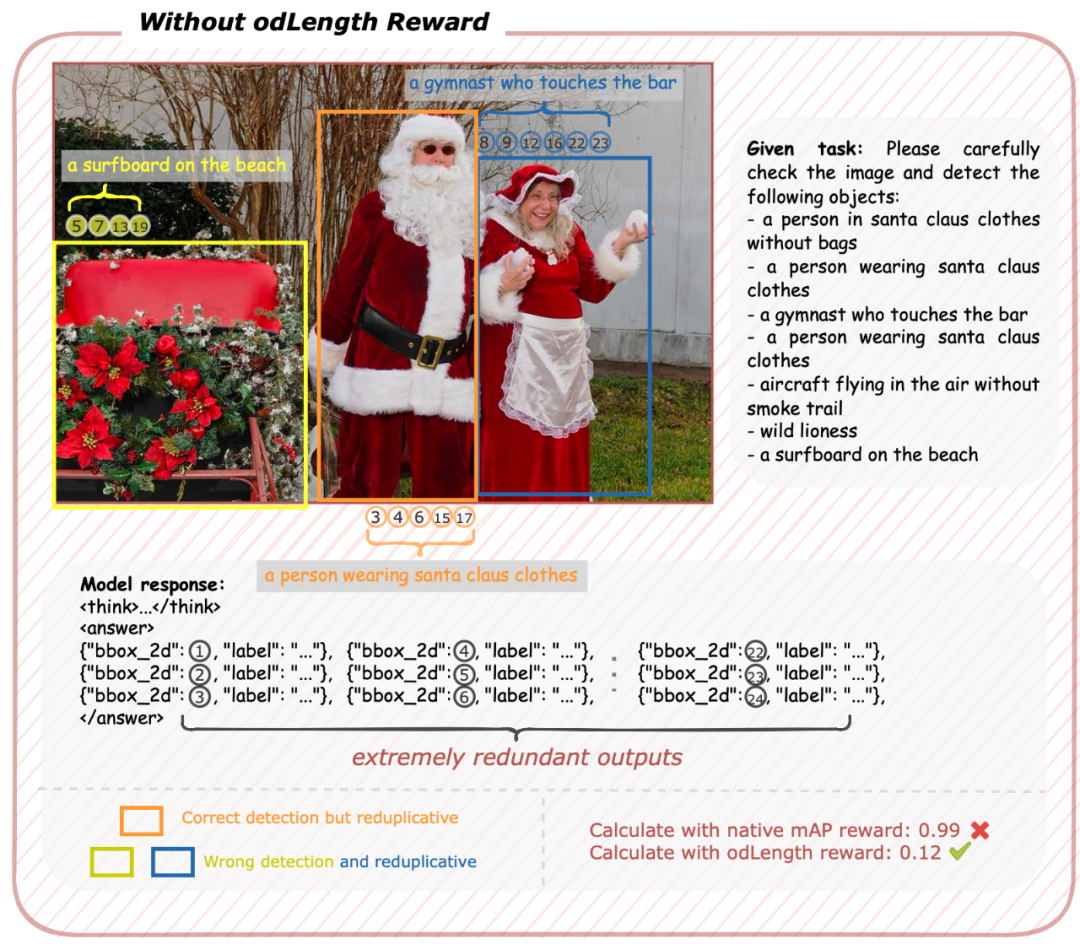
OD Aha Moment:在 odLength 奖励的引导下,模型逐渐学会了一种两步推理策略——通过思考判断目标是否存在,再生成精确的边界框。这种“OD Aha Moment”的出现,标志着模型开始具备更深层次的推理能力。

Scaling Law:实验结果表明,模型规模对 RL 的效果有显著影响。较大的模型(如 7B 和 32B)在复杂任务上的表现明显优于较小模型(如 3B)。这进一步验证了 RL 对于挖掘大规模模型潜在能力的可行性与有效性。
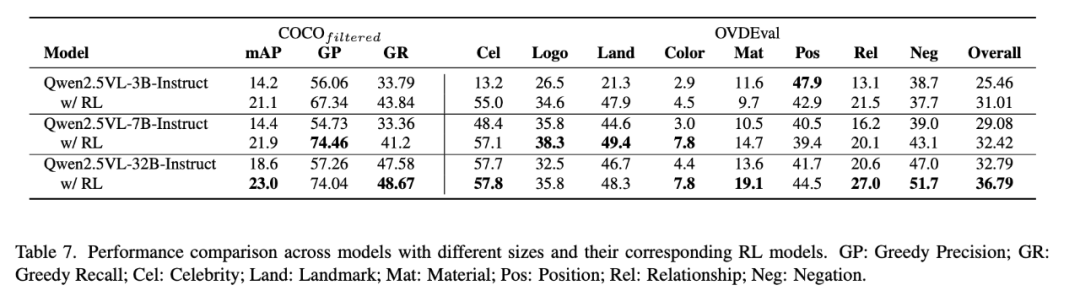
此外,研究还发现,高质量、语义丰富的训练数据能够显著提升模型的推理能力,而低质量或过于简单的数据则可能限制模型的泛化能力。这些洞见为未来的研究提供了重要参考。

整体来看,VLM-R1 提供了一个模块化、灵活且高效的框架,支持多种功能,包括:
-
GRPO 兼容性:完全支持原生 GRPO 算法,并允许用户对超参数进行细粒度控制。
-
LoRA 微调:通过低秩适应(LoRA)实现参数高效训练,适合资源有限的场景。
-
多节点分布式训练:支持跨多个 GPU 或服务器节点的分布式训练,提升训练效率。
-
多模态混合训练:支持同时训练图像-文本和纯文本数据集,满足多样化任务需求。自定义数据集和奖励函数 :用户可以轻松集成自己的数据集和奖励设计,适配特定任务或领域。
VLM-R1 提供了统一、模块化且高度可扩展的训练流程,成为视觉语言强化学习研究的强大工具。更重要的是,整体框架完全开源!这将有力推动社区进一步研究 RL 在 VLM 上的潜力!

总的来说,VLM-R1 证明了 R1 类似的思路完全可以成功复现于视觉任务,并且强化学习显著提升了视觉模型的泛化能力。通过精心设计的奖励机制和高质量的训练数据,VLM-R1 在特定任务上实现了突破性表现。
这些成果不仅为视觉语言模型的研究开辟了新方向,也为强化学习在多模态任务中的应用提供了重要参考。
未来,随着更多任务和模型的加入,VLM-R1 有望进一步拓展其应用场景,成为推动视觉 AGI 发展的重要力量。让我们共同期待 VLM-R1 在视觉语言模型领域的更多精彩表现!
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧

(文:PaperWeekly)