

当前,基于强化学习提升多模态模型的推理能力已经取得一定的进展。但大多研究者们选择 7B+ 的模型作为基座,这对于许多资源有限的科研人员而言仍存在显著的门槛。
同时,在视频推理领域,由于高质量强推理性数据较为稀少,通用问答数据较难激发模型的深层次逻辑推理能力,因此先前一些初步尝试的效果大多不尽如人意。
近日,北京航空航天大学的研究团队推出小尺寸视频推理模型 TinyLLaVA-Video-R1,其模型权重、代码以及训练数据全部开源!
该工作验证了小尺寸模型在通用问答数据集上进行强化学习也能有不错的效果,与使用相同数据进行监督微调的模型相比,TinyLLaVA-Video-R1 在多个 benchmark 上都有性能提升。同时,模型还能在训练与测试的过程中多次展现自我反思与回溯行为!

-
论文标题:TinyLLaVA-Video-R1: Towards Smaller LMMs for Video Reasoning
-
论文地址:https://arxiv.org/abs/2504.09641
-
Github:https://github.com/ZhangXJ199/TinyLLaVA-Video-R1
在推特上,HuggingFace AK 也连续两次转发推荐了这篇文章:
为什么选择 TinyLLaVA-Video 作为 Base Model?
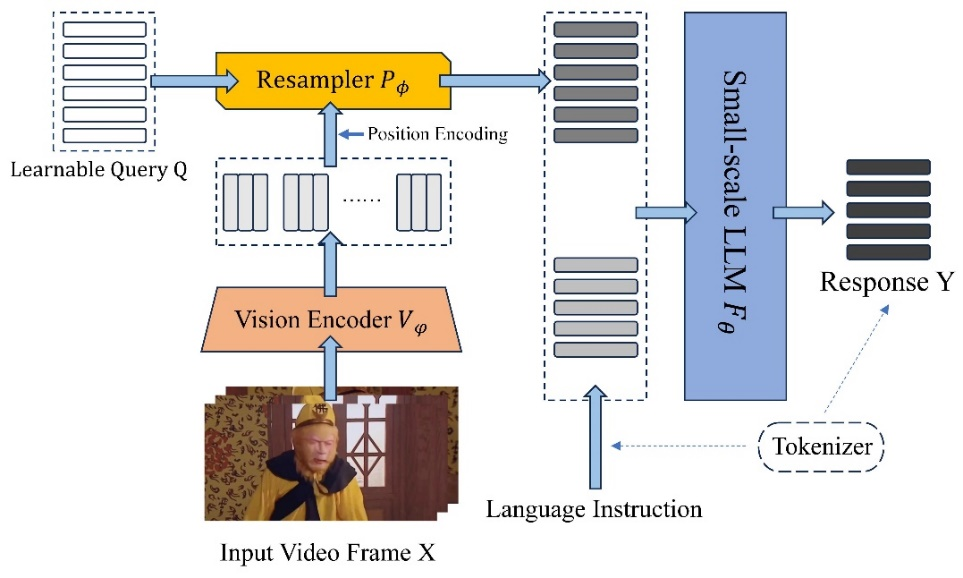
图表 1 TinyLLaVA-Video 整体框架
虽然现有的开源视频理解模型基座具有强大的理解与感知能力,但由于其训练数据不透明,使用开源视频数据进行后训练可能会引入不可控的变量,从而影响实验结果和结论的可靠性。
因此,北航团队选择训练过程完全可溯源的 TinyLLaVA-Video 作为 Base Model,该模型采用 Qwen2.5-3B 作为语言模型,SigLIP 作为视觉编码器。虽然 TinyLLaVA-Video 仅有 3.6B 的参数,且在预训练阶段为了控制训练时长并未使用大量数据,但其仍能在多个 Benchmark 上能够优于现有的多个 7B+ 模型。
TinyLLaVA-Video-R1 主要做了什么?
而当使用人工标注的 16 条 CoT 数据为模型进行冷启动后,在实验的过程中就不再出现这样的现象,同时,模型也将更快学会遵守格式要求。因此该工作认为,冷启动对于小尺寸模型推理是必要的,即使是极少量的冷启动数据,对于稳定模型训练也是很有帮助的。
引入长度奖励与答案错误惩罚
现有的许多推理工作仅仅设置格式奖励而没有添加长度奖励,但受限于小尺寸语言模型的能力,在这种设置下进行训练并不会使模型的响应长度增加,甚至出现一点下降。
在引入连续长度奖励后,模型的响应长度在训练过程中显著增加,如图所示。然而在这种设置下,模型为了增加响应长度而进行了一些无意义的推理,这不仅没有提高性能,反而导致训练时间显著增加。
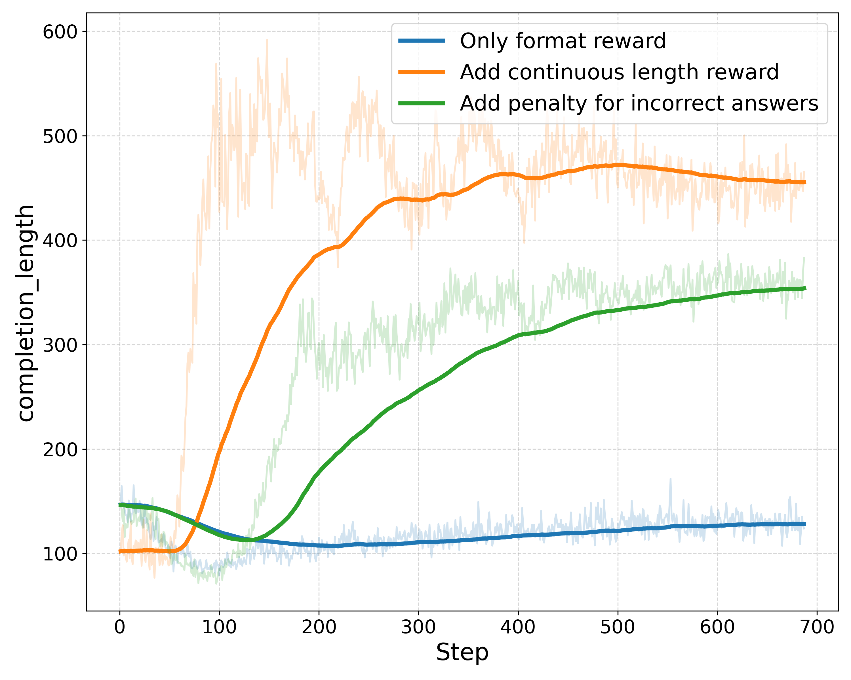
因此,TinyLLaVA-Video-R1 进一步将答案错误惩罚纳入总奖励,观察到模型响应的质量有所提升,并且在整个训练过程中输出长度和奖励也能够保持增长。
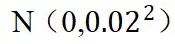 ,尽管这种噪声仅引起轻微的扰动,但它能够确保组内响应优势的多样性。
,尽管这种噪声仅引起轻微的扰动,但它能够确保组内响应优势的多样性。实验结果
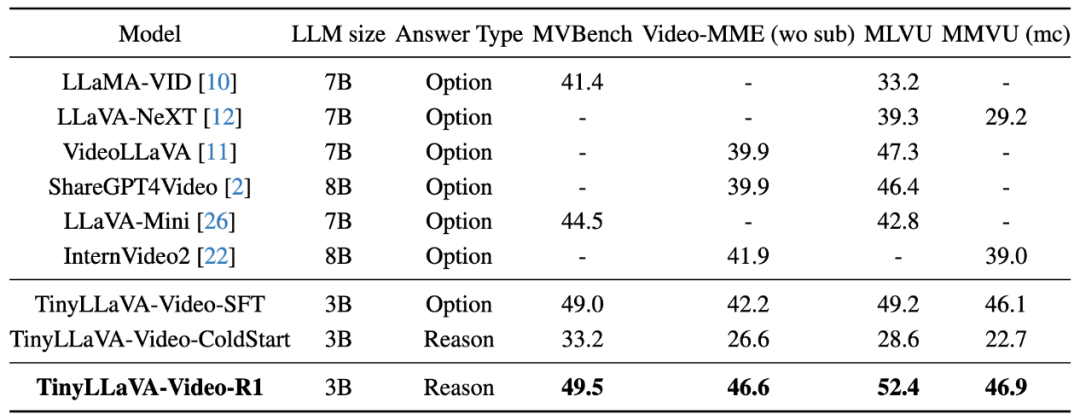
首先,TinyLLaVA-Video-R1 验证了使用强化学习能够明显提升模型性能,与使用相同数据进行监督微调的 TinyLLaVA-Video-SFT 相比,TinyLLaVA-Video-R1 在多个 benchmark 中均有更佳的表现。

同时,TinyLLaVA-Video-R1 能够理解和分析视频内容,逐步评估每个选项,并最终给出答案。与仅输出最终答案的模型相比,该模型能够生成有意义的思考过程,使其回答更加可解释且有价值。这也是视频推理模型相对于传统视频理解模型的重要提升与优势。

与其他使用强化学习提升模型推理能力的工作相似,北航团队也在 TinyLLaVA-Video-R1 上复现了「Aha Moment」,即模型在思考的过程中引发紧急验证等行为。实验结果也验证了,即使使用弱推理的通用视频数据对小尺寸模型进行训练,也能够引发模型的回溯与自我反思。
后续,北航团队也将进一步研究小尺寸视频推理模型,未来工作将包括引入高质量视频推理数据与强化学习算法改进。
同时,TinyLLaVA 系列项目也始终致力于在有限计算资源下研究小尺寸模型的训练与设计空间,坚持完全开源原则,完整公开模型权重、源代码及训练数据,为资源有限的研究者们理解与探索多模态模型提供平台。
©
(文:机器之心)