
大家好,好久不见,最近我在细看vllm v1 和 sglang的代码,所以接下来会写一系列的文章来介绍它们。
在本文开始前,插一个题外话,简单解释下今年我很久不更新的原因:我在xhs等平台上,大量发现盗取我的文章进行售卖的行为,这点让我非常愤怒且无能为力,也确实打击到了我写blog的热情。一番考虑后,我想让自己更轻松一些,同时也花更多时间在写代码上,所以我放慢了更新频率(但不会因此改变更新的质量)。如果大家在别的平台上也看见这种盗取售卖的行为,欢迎和我说,我要去对线!!
现在继续回到正文内容,vllm v1的系列文章基于的代码版本是vllm 0.8.2(当前已更新到0.8.4),在代码细节上,不同版本间可能有diff,但在大框架上是不变的。本文将对vllm v1的整体运作流程进行介绍,在后面的系列中,再来看关于调度器、KV cache管理、分布式推理等更多细节。对于首次了解vllm的朋友,推荐先阅读以下2篇文章:
-
vllm原理篇 -
vllm v0整体运作流程
一、Offline batching(离线批处理)
1.1 调用方式
from vllm import LLM, SamplingParams
if __name == "__main__":
# Sample prompts.
prompts = [
"Hello, my name is",
"The president of the United States is",
"The capital of France is",
"The future of AI is",
]
# Create a sampling params object.
sampling_params = SamplingParams(temperature=0.8, top_p=0.95)
# 创建llm实例,在这个过程中也创建了llm实例下维护的llm_engine
llm = LLM(model="facebook/opt-125m")
# 执行offline batching推理,得到这批prompts的输出
outputs = llm.generate(prompts, sampling_params)
# 打印输出
for output in outputs:
prompt = output.prompt
generated_text = output.outputs[0].text
print(f"Prompt: {prompt!r}, Generated text: {generated_text!r}")
1.2 整体流程
Offline batching下的整体流程如下图所示,在后文中,我们称请求为req:
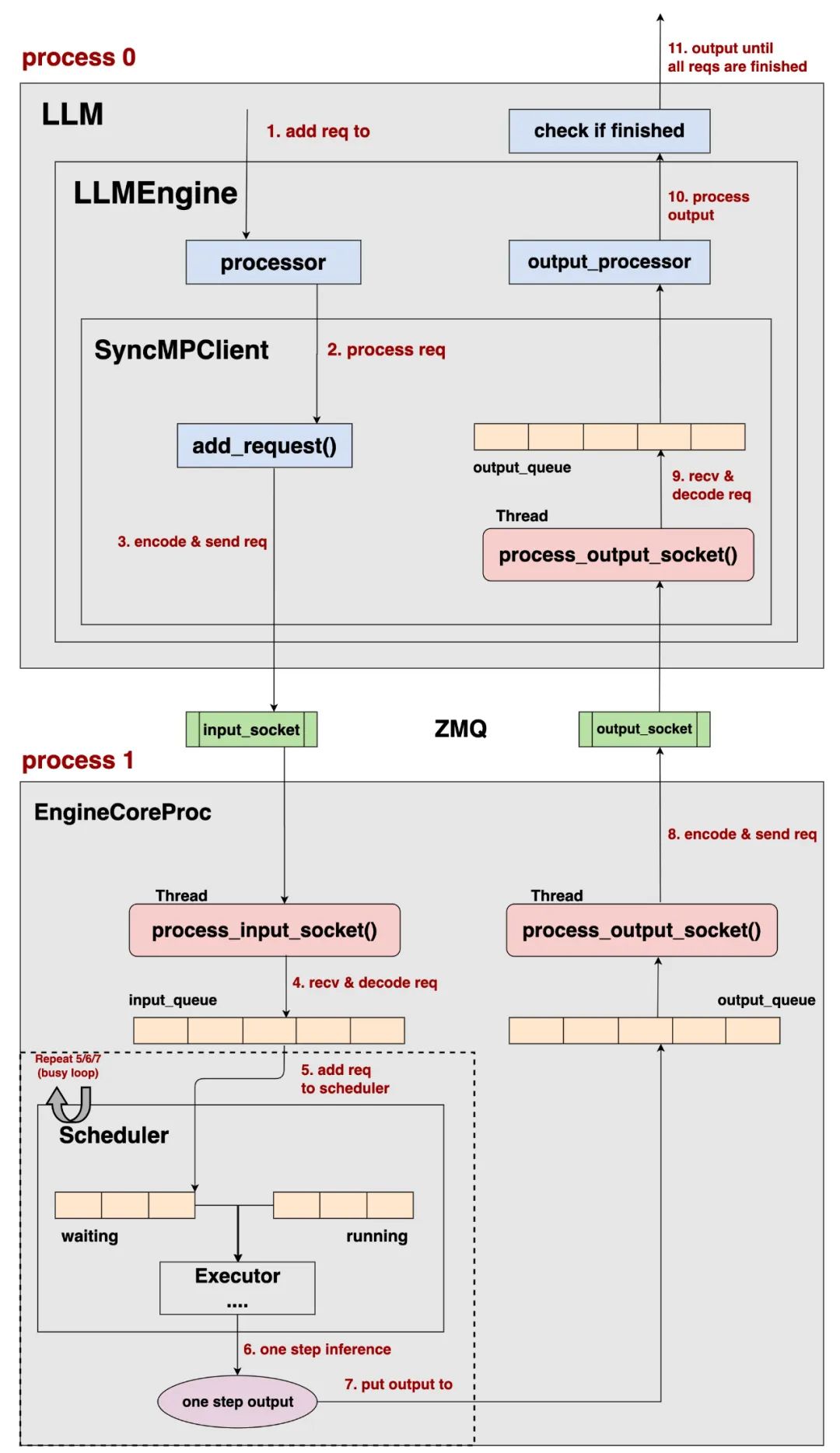
我们先忽略图中七七八八的细节,从大面上来看一下这个流程:
-
首先,观察到我们采用2个不同的进程(process0,process1)来完成整个推理。
-
process0上维护的核心对象是SyncMPClient(Sync MultiProcessing Client),我们简称其为客户端。process1上维护的核心对象是EngineCoreProc,我们简称其为EngineCore。
-
vllm使用ZMQ来负责不同进程间的数据收发(不了解ZMQ的朋友,到此为止只要先了解它的主要功能是这个即可,后续再慢慢了解它的其余细节)
-
观察到:
-
对于req的输入输出处理(processor、 output_processor)是由客户端执行的;而req的实际推理过程(Scheduler -> ModelExecutor)则由EngineCore来执行。
-
也就是说,vllm v1将cpu和gpu上的调度拆成2个进程进行处理,这样可以更好实现cpu和gpu的overlap。举例来说,在先前vllm版本的推理中,我们经常会发现detokenize(tokenid -> 文本)这个步骤会成为推理瓶颈,特别是遇到长序列的情况。在等待序列做detokenize的过程中,gpu是空转的。现在通过这种拆解,让原来是串行的事情并行化。
最后,客户端的类型有很多种,由于本节我们讨论的是offline batching,所以展示的是SyncMPClient。在下一节中,我们会来看其余类型的客户端。
有了以上大体上的感知,现在我们可以来介绍图中细节了:
1、add req to:LLM端接收req,并将req发送至LLMEngine的processor。
2、process req:原始req -> EngineCoreRequest,processor的作用是对req进行预处理,具体包括:
-
Tokenize -
验证输入参数的合法性 -
将req封装成特定形式(EngineCoreRequest)等等
3、encode & send req:
-
将EngineCoreRequest发送给SyncMPClient -
SyncMPClient会对其做encode操作:EngineCoreRequest -> pickle EngineCoreRequest -
通过zmq input_socket,将pickle EngineCoreRequest 发送给 EngineCoreProc(这里SyncMPClient和EngineCoreProc分别运行在2个不同的进程上,vllm选择使用ZMQ来负责进程间的数据通信)
———————– 进程分割线(Client -> EngineCoreProc) ————————–
4、recv & decode req:
-
在EngineCoreProc所在的进程上,会启动一个线程,在该线程中执行process_input_socket()函数,这个函数具体做了如下事情: -
持续监听通过input_socket传来的pickle EngineCoreRequest -
decode:(pickle EngineCoreRequest -> EngineCoreRequest) -
将 EngineCoreRequest 装入 input_queue 队列中
5、add req to scheduler:EngineCoreRequest 被添加进 Scheduler的waiting队列中
6、one step inference
-
Scheduler执行一步调度,从waiting和running队列中选择req进行推理,输出一步推理后的结果(EngineCoreOutputs)。这边的细节我们暂时略过,留到后文细说。
7、put output to output_queue:将一步推理结果放入 output_queue队列中这里我们会重复执行5/6/7步骤,即重复执行【一步调度->一步推理】的过程,直到 input_queue 和 scheduler中再无req存量。
8、encode & send req:
-
在EngineCoreProc所在的进程上,会启动一个线程,在该线程中执行process_output_socket()函数,这个函数具体做了如下事情: -
持续监听output_queue中装入的一步推理输出结果(EngineCoreOutputs) -
encode:EngineCoreOutputs -> pickle EngineCoreOutputs -
使用zmq output_socket作为通信管道,将pickle EngineCoreOutputs发送给SyncMPClient
———————– 进程分割线(EngineCoreProc -> Client) ————————–
9、recv & decode req
-
在SyncMPClient所在进程上,会启动一个线程,在该线程中执行process_output_socket()函数,这个函数具体做了如下事情: -
持续监听通过output_socket传递来的pickle EngineCoreOutputs -
decode:pickle EngineCoreOutputs -> EngineCoreOutputs -
将 EngineCoreOutputs 装入 output_queue 中
10、process_output,对EngineCoreOutputs做一些后置处理,例如detokenize等操作。
11、output until all reqs are finished:LLM回去检测每一条req是否已做完推理(req.finished的状态),由于目前我们是offline batching的模式,所以等到全部的req都完成推理后,LLM会一起输出推理结果。
二、Online Serving
2.1 调用方式
这里我假设起的online serving是这份脚本:
https://github.com/vllm-project/vllm/blob/4283a28c2fb7595c5d72d3edc7ad356c87273d94/vllm/entrypoints/openai/api_server.py
2.2 整体流程
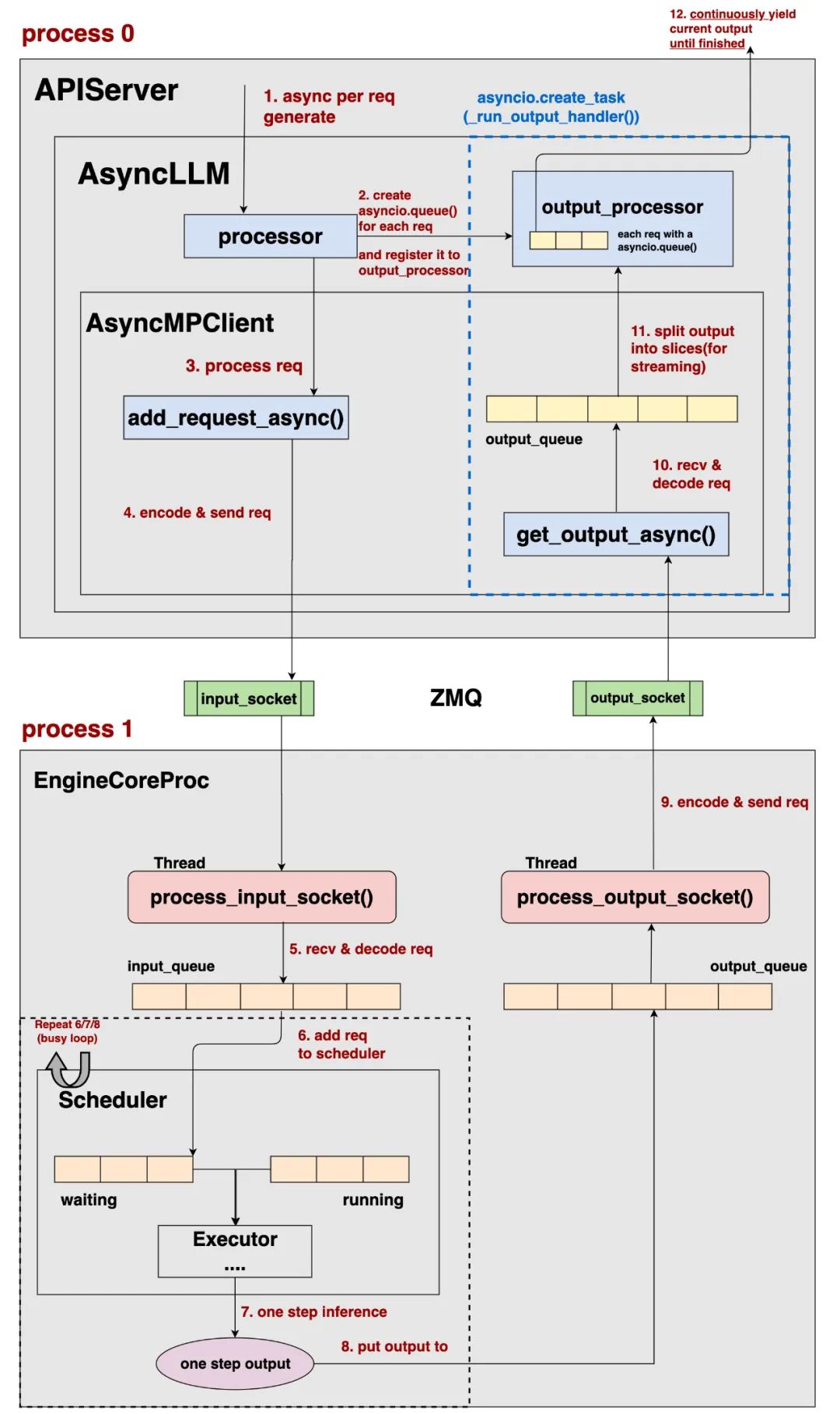
我们还是先从整体上来感知online serving的运作流程:
-
和offline bacthing相比,EngineCoreProc部分的逻辑没有变 -
Client和EngineCoreProc交互的逻辑没有变 -
所以现在,我们只需要关注Client的实现细节
Online Serving的Client实现细节如下:
1、async per req generate:用户发送req给vllm的API server,server对单req发起generate操作。这里会首先将req发送给AsyncLLM
2、create asynico.queue() for each req和register the queue to output_processor:
-
这两个步骤都在AsyncLLM上执行 -
create asynico.queue() for each req:会针对每一个req创建一个异步队列,这个异步队列将用于存储这个req的输出结果。 -
register the queue to output_processor:会把这个req的异步队列注册到output_processor中。 -
为什么每个req需要一个单独的队列: -
在online serving中,req的输出结果是流式的(一块一块地把结果返回给用户) -
在online serving中,用户时常有多轮对话的需求等等 -
基于这样的考虑,相比于offline batching对所有req的一次性统一输出,online serving下更有必要将各个req的输出隔离开来,因此才单独针对每个req创建一个用于盛放输出结果的异步队列。
3、prcocess req 和 4、encode & send req和offline batching逻辑基本一致,这里不再赘述
———————– 进程分割线(Client -> EngineCoreProc) ————————–
EngineCorePro会实际执行req的推理过程,5~9的步骤我们在offline batching中详细解释过,这里不再赘述
———————– 进程分割线(EngineCoreProc-> Client) ————————–
在AsyncLLM上,我们会启动一个异步任务asyncio.create_task(_run_output_handler()),这个异步任务上会执行_run_output_handler()函数,这个函数的主要作用是异步接受、处理来自EngineCore的模型输出结果,具体流程如下:
10、`AsyncMPClient上发起get_output_async()`:
-
持续监听通过output_socket传递来的pickle EngineCoreOutputs -
decode:pickle EngineCoreOutputs -> EngineCoreOutputs -
将 EngineCoreOutputs 装入 output_queue 中
11、split output into slices:
-
将output_queue中的数据切成slices,方便后续做流式输出 -
将slices数据装入这个req注册在output_processor中、只属于这个req的异步队列 -
output_processor将会以slices为维度,对输出数据做诸如detokenize等的操作。
12、continously yield current output:
-
对于一条请求,AsyncLLM将会持续从output_processor中获取它当前的输出结果,返回给用户,直到这条请求推理完毕
此外,Vllm官方文档中,也给出了一张online serving的架构图(https://blog.vllm.ai/2025/01/27/v1-alpha-release.html),上面的内容可以说是这张架构图的细节扩展,大家可以比对进行理解:
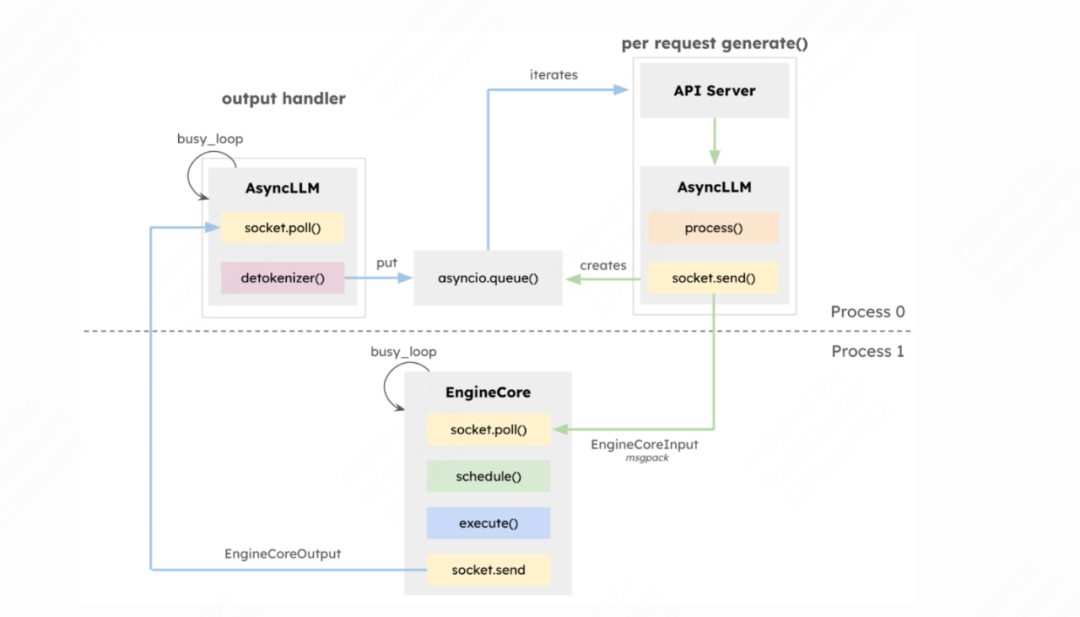
到此为止,我们就把V1的大致运作流程介绍完了,在后面的文章中,我们会来看关于调度器、KV Cache管理和分布式模型执行的更多细节。
(文:GiantPandaCV)