

本篇工作已被电子设计自动化领域顶级会议 DAC 2025 接收,由上海交大计算机学院蒋力教授与刘方鑫助理教授带领的 IMPACT 课题组完成,同时也获得了华为 2012 实验室和上海期智研究院的支持。第一作者是博士生汪宗武与硕士生许鹏。
在通用人工智能的黎明时刻,大语言模型被越来越多地应用到复杂任务中,虽然展现出了巨大的潜力和价值,但对计算和存储资源也提出了前所未有的挑战。在以 transformer 模型为基础的大模型中,键值缓存虽然用以存代算的思想显著加速了推理速度,但在长上下文场景中成为了存储瓶颈。例如,半精度的 LLaMA-2-7B 模型权重约 14GB,在上下文长度为 128K 时键值缓存占据 64GB,总和已经接近高端卡 NVIDIA A100 的 80GB 显存容量上限。键值量化可被用于压缩缓存,但往往受到异常值的干扰,导致模型性能的显著下降。为此,本文的研究者提出了 MILLION,一种基于乘积量化的键值缓存压缩和推理加速设计。

-
arxiv 链接:https://arxiv.org/abs/2504.03661
-
开源链接:https://github.com/ZongwuWang/MILLION
整型量化的软肋:异常值
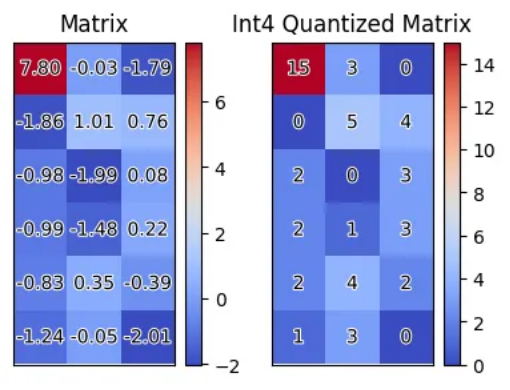
图 1:矩阵量化可视化。红色代表的异常值显著大于其他值,导致均匀量化后高位编码被浪费。
量化中受到广泛使用的整型均匀量化受到异常值的影响较为显著。图 1 展示了矩阵中的量化。在一组分布较为集中的数据中,一个显著偏离其他值的异常值会导致其他值的量化结果全部落在较低区间,浪费了高位编码的表示能力。
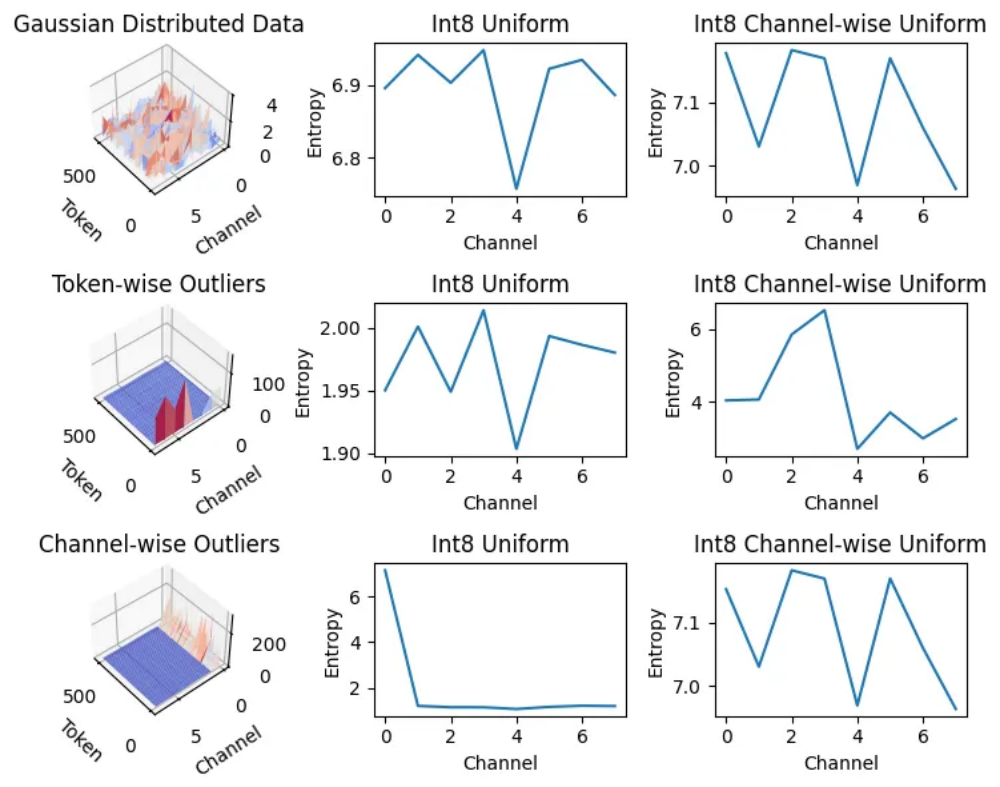
图 2:图中使用 「通道熵」 定量比较不同方案的量化效果,越大表明越有效地利用了通道容量,即整型的宽度。沿通道量化只能解决沿该方向分布的异常值,而在面对另一方向异常值时效果不佳。
在实际的键值量化中,为了更好的表示能力,通常对于每个通道(即键值向量的维度)或每个 token 采取不同的量化参数,这种方法被称为沿通道量化(channel-wise quantization)或沿词元量化(token-wise quantization)。然而,如图 2 所示,沿特定方向量化只能解决沿该方向分布的异常值。
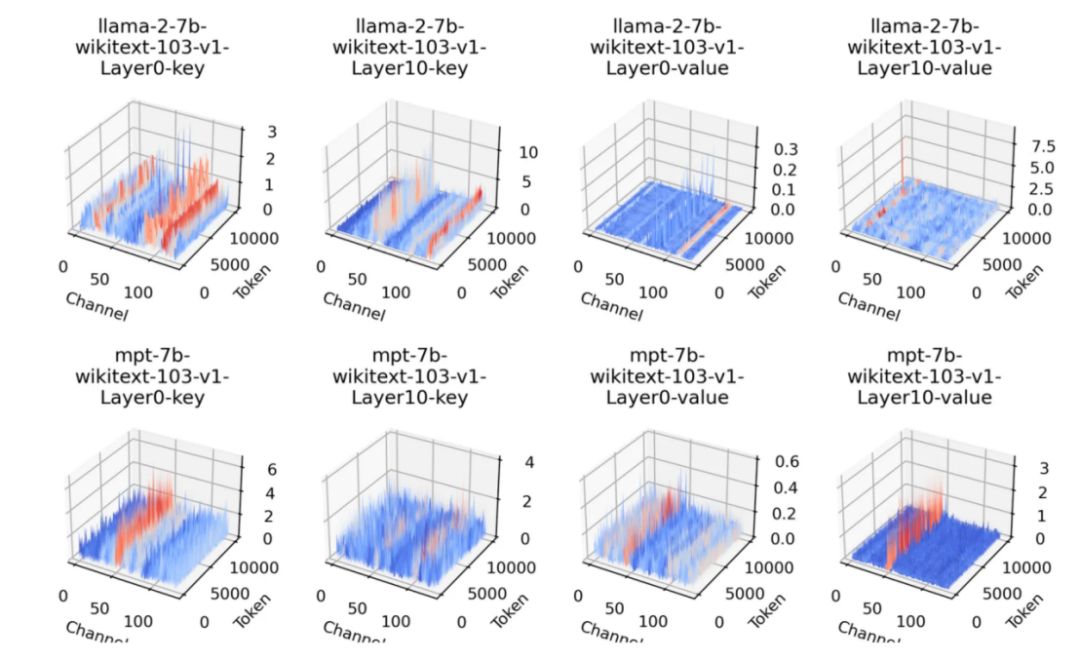
图 3:实际采样获得的键值缓存分布。在 llama-2-7b-wikitext-103-v1-layer10-value 中,异常值并不遵循简单的沿通道分布,而是呈现为较复杂的点状和团状。
研究团队通过实际采样数据发现,在键值缓存中,沿通道方向分布的异常值占多数,但也存在并不明显的情况,如图 3 所示。这表明,上述量化方案并不是一劳永逸的解决方式,仍然存在优化空间。
异常值的解决方案:乘积量化
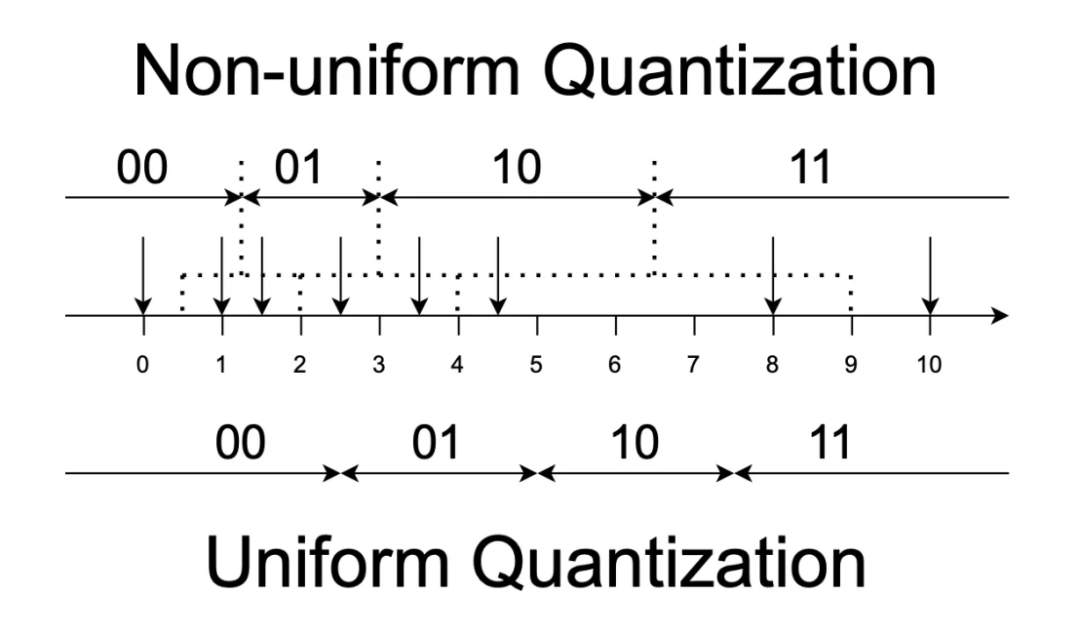
图 4:数轴上的均匀和非均匀量化对比。在对 8 个数据点进行 2 比特量化过程中,均匀量化浪费了 10 编码。而基于聚类的非均匀量化则编码更合理。
如图 4 所示,非均匀量化通过聚类的方式允许量化区间不等长,从而更合理地分配编码,提升量化效率。研究团队观察到,由于通道间的数据分布可能存在关联(即互信息非负),将通道融合后在向量空间中聚类,效果一定不亚于独立通道的量化,如图 5 所示。
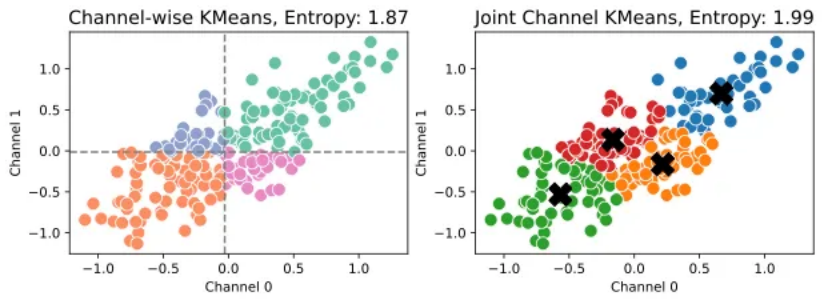
图 5:左图为两个通道独立进行 1 比特量化,右图为在通道融合后进行 4 分类的 KMeans 聚类。融合通道量化的通道熵更加接近 2 比特的容量极限,展示出更好的量化效果。
由于高维空间中聚类较为困难,因此将整个向量空间划分为多个低维子空间的笛卡尔积,可以平衡聚类复杂度和量化效果。这与最近邻搜索中使用的乘积量化思想一致。研究团队通过实验发现,子空间维度为 2 或 4 是较好的平衡点。
推理加速手段:高效的系统和算子实现
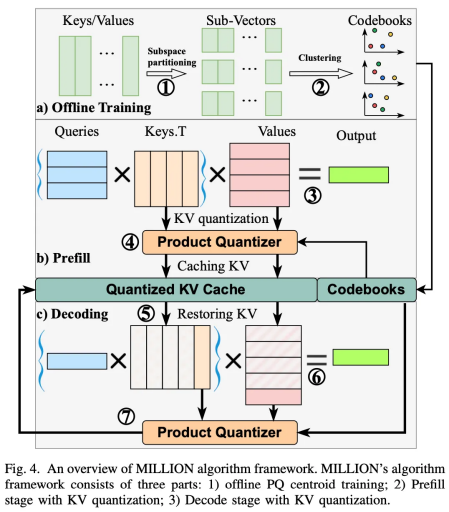
图 6:三阶段的推理系统设计

图 7:分块注意力机制使得批量延迟量化成为可能
图 6 展示了离线训练、在线预填充、在线解码三阶段的量化推理系统设计。其中,码本训练(量化校准)属于秒级轻量化任务,并且离线进行,不影响运行时开销;在线预填充阶段使用训练好的码本对键值缓存进行量化压缩,达到节省显存的目的;在线解码阶段采用分块注意力机制的方法,将预填充阶段的历史注意力和生成 token 的自注意力分开计算(如图 7 所示),达成批量延迟量化的目的,掩藏了在线量化的开销,确保模型输出的高速性。并且,在历史注意力阶段,由于历史键值对数远大于码本长度,因此先用查询向量与码本计算好非对称距离查找表(ad-LUT),可以大大减少内积距离计算量,达到加速计算的目的。
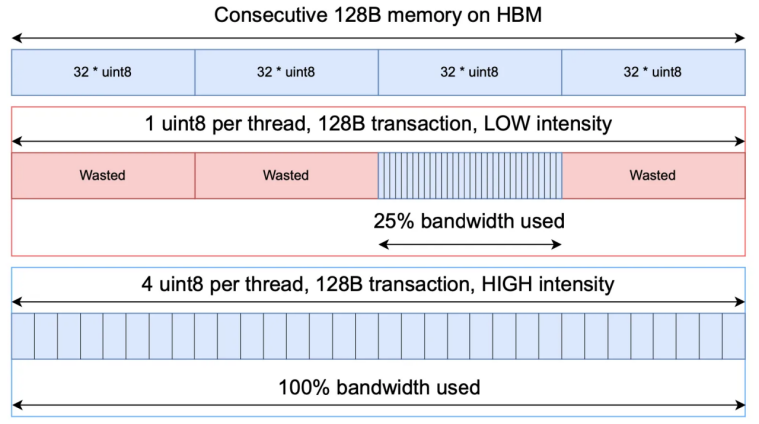
图 8:向量化加载可有效使带宽饱和
在算子优化方面,研究团队在 flash decoding 的基础上使用了宽数据(如 float4)向量化加载的方式,将多个乘积量化编码打包为宽数据,有效使带宽饱和(如图 8 所示)。同时,在表查找阶段,子空间之间的表具有独立性,并且可以被放入少量缓存行中,研究团队利用这一空间局部性极大提高了表查找的 L2 缓存命中率。此外,研究团队还仔细扫描了不同上下文长度下可能的内核参数,找到最优配置,形成了细粒度的预设,在实际运行时动态调整,充分利用 GPU 的计算资源。具体实现可以在开源仓库中找到。
实验结果
实验设置
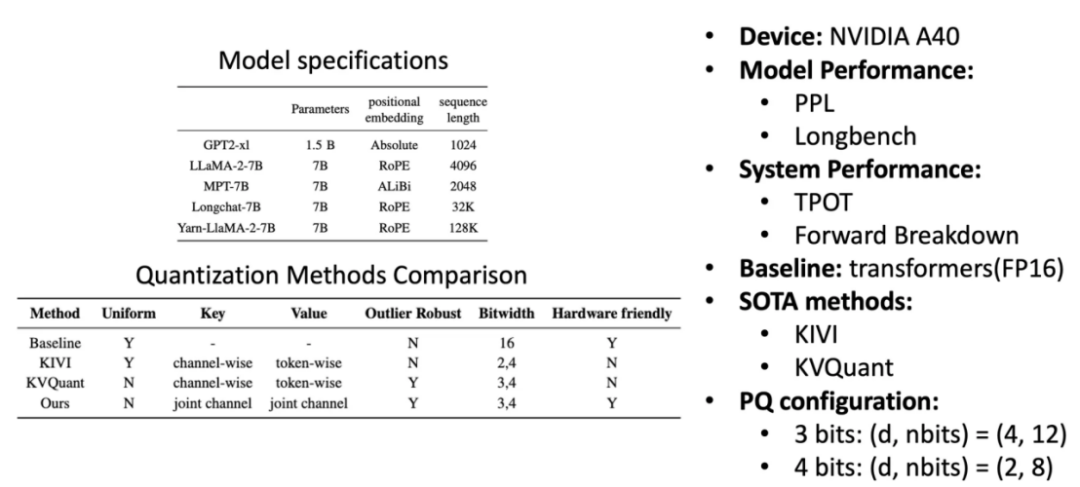
图 9:实验设置
实验采用了不同位置编码、不同上下文长度的多种模型进行了详细的评估。在模型性能方面,采用困惑度(Perplexity,PPL)和 Longbench 两种指标;在系统性能方面,采用每词元输出间隔(Time Per Output Token, TPOT)定量分析,并给出了注意力层详细的剖析。对比采用方案和乘积量化参数如图 9 所示。
模型性能
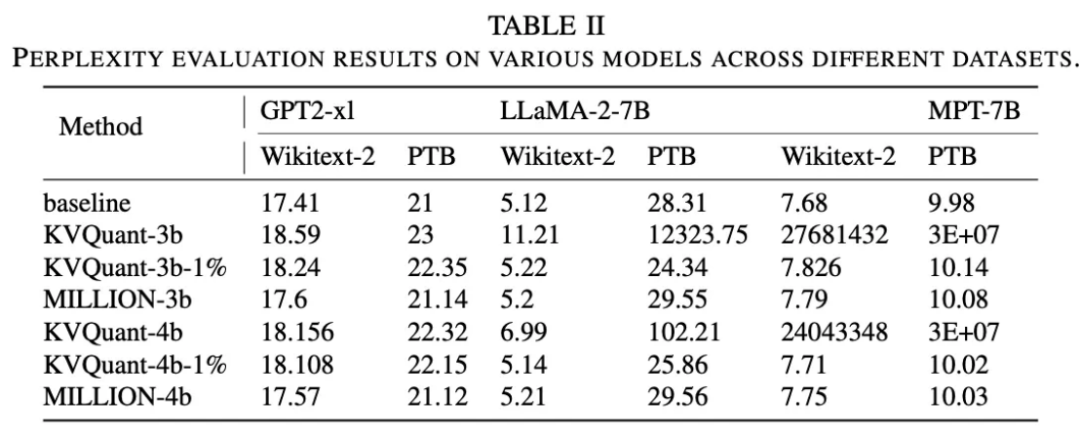
图 10:困惑度指标。其中 「-1%」 表示该方法额外存储 1% 的异常值不参与量化。
困惑度越小表明模型输出质量越高。实验结果表明,MILLION 与额外处理了异常值的 SOTA 方案输出质量保持一致,展现出对异常值良好的鲁棒性。而 SOTA 方案在不处理异常值的情况下可能会遭遇严重的输出质量损失。
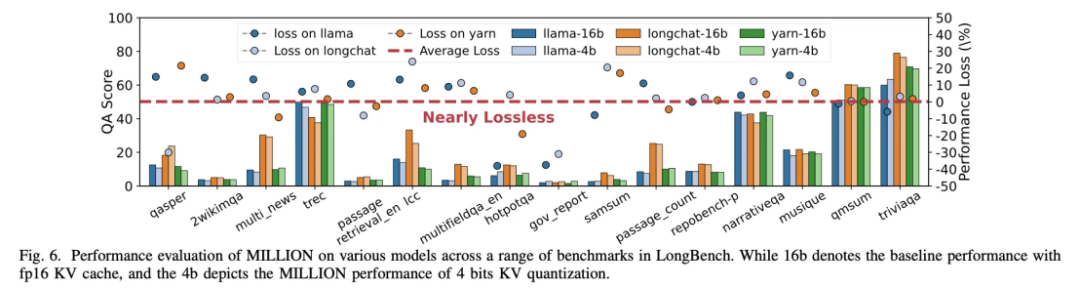
图 11:Longbench 问答数据集得分展示
在长对话问答任务中,不同模型在各种数据集上的得分均表明,MILLION 方案能够在 4 倍键值缓存压缩效率下保持几乎无损的表现。
系统性能
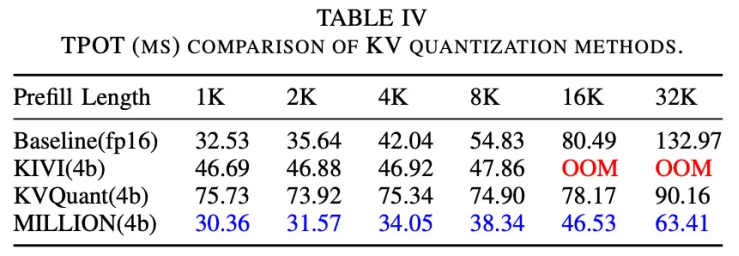
图 12:每词元输出时间。对比其他方案,MILLION 的优势持续增长,在 32K 上下文时达到 2 倍加速比。
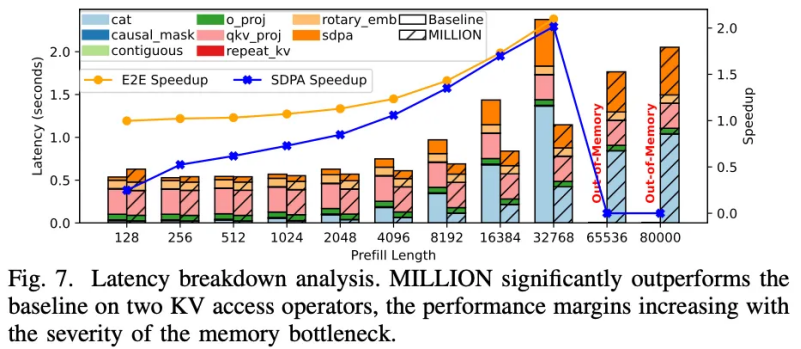
图 13:注意力层时间剖析
在 TPOT 评估中,MILLION 能够在 32K 上下文语境下同时达成 4 倍键值缓存压缩比和 2 倍端到端加速比。注意力层的深入分析表明,MILLION 在访存和内核函数方面对比 baseline 取得显著优势。
总结
MILLION 的主要贡献在于:(1)深入分析键值缓存分布;(2)提出基于乘积量化的非均匀量化算法;(3)设计高效的推理系统及内核。研究团队首先证实了键值缓存中异常值存在的普遍性,并指出异常值的不同分布是当前主流的量化方案精度不足的根本原因;然后提出通过将高维向量空间分解为多个子空间,并在每个子空间内独立进行向量量化的方法,更有效地利用了通道间的互信息,并且对异常值展现出极强的鲁棒性;接着通过 CUDA 异步流和高效的算子设计,充分利用了 GPU 的并行计算能力和内存层次结构,以支持乘积量化的高效执行。实验表明,对比主流框架 transformers 的半精度实现,MILLION 在 32K 上下文场景中同时达成 4 倍压缩率和 2 倍加速比,并且在多种语言任务中精度表现几乎无损。
©
(文:机器之心)