


继董小姐之后,Chatbot Arena 曾是 LLM 竞技场的「金标尺」,如今却曝出评分被有意扭曲的证据!
开源AI研究者对Chatbot Arena提出质疑!
Cohere Labs等机构研究人员于 4 月 29 日上线的论文《The Leaderboard Illusion》详细梳理了 Chatbot Arena 内部一系列暗箱操作,揭露了目前最具权威的AI模型排名榜单——

Chatbot Arena存在系统性偏向问题。

对于这场「排行榜幻觉」让我们不禁要问:我们真的能信任这些排名吗?
私下测试与选择性上榜——大厂独享的隐形特权
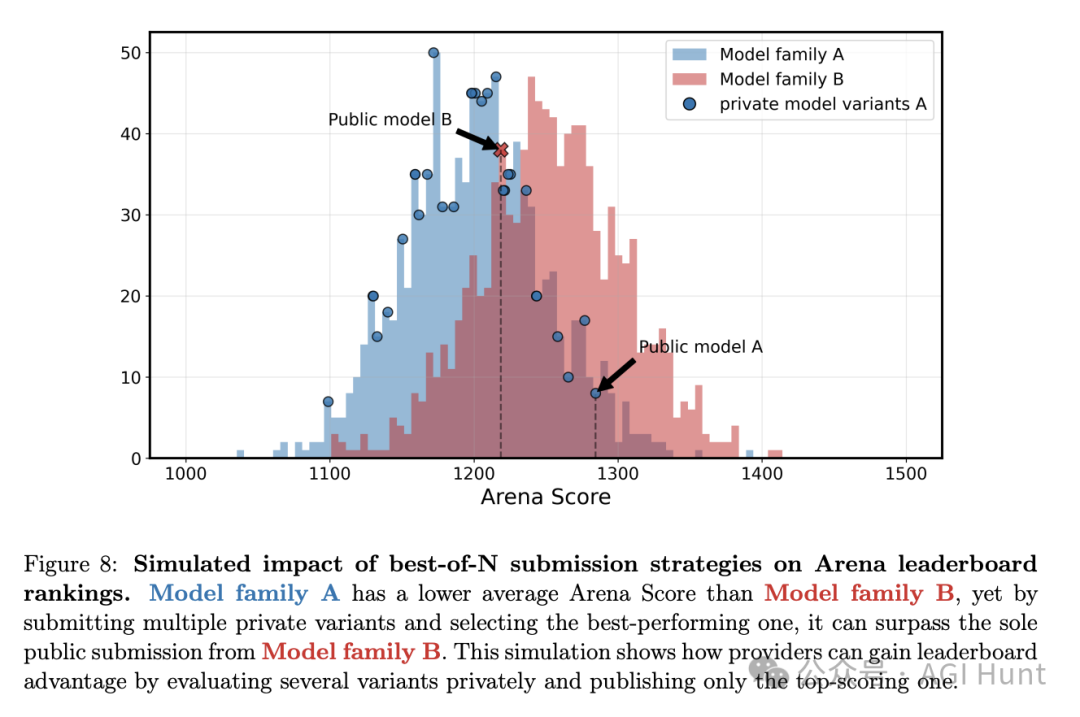
论文作者在审查Chatbot Arena的数据后发现,一些大型AI公司享有未公开的特权位置,可以同时测试多个模型变体,然后只选择表现最好的版本公开发布。

数据显示,2025年1月至3月期间,Meta一个月内私下测试了27个模型,而Google也有10个,这些测试都发生在他们正式发布Llama 4和Gemma 3之前。
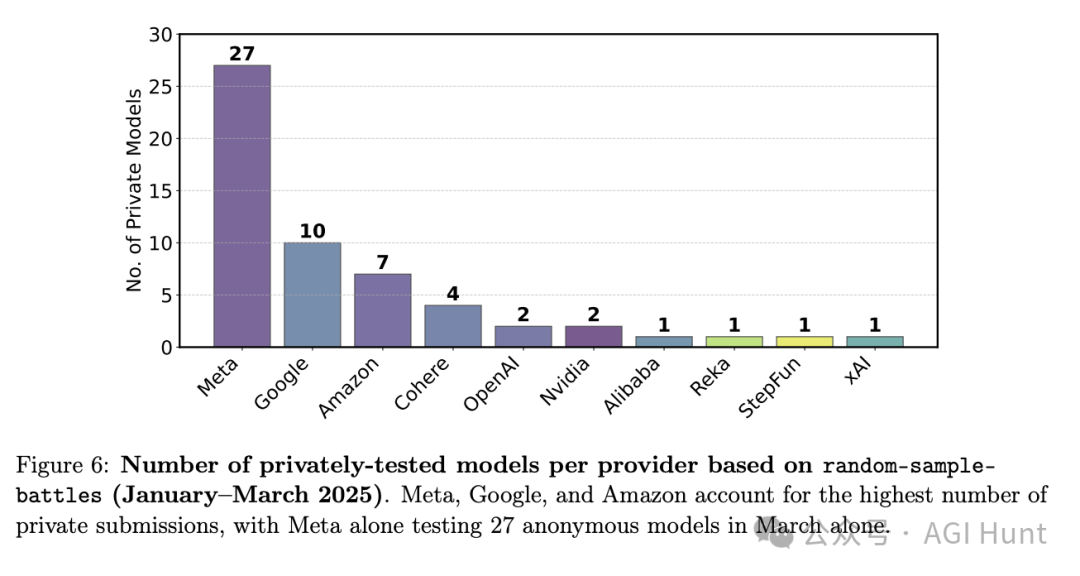
更惊人的是,如果再算上Vision榜单上的测试变体,Meta实际上测试了多达43个变体!
在这种机制下,大公司可以从多个变体中挑选出表现最佳的那个,而其他不知情的参与者则只能提交单一版本。
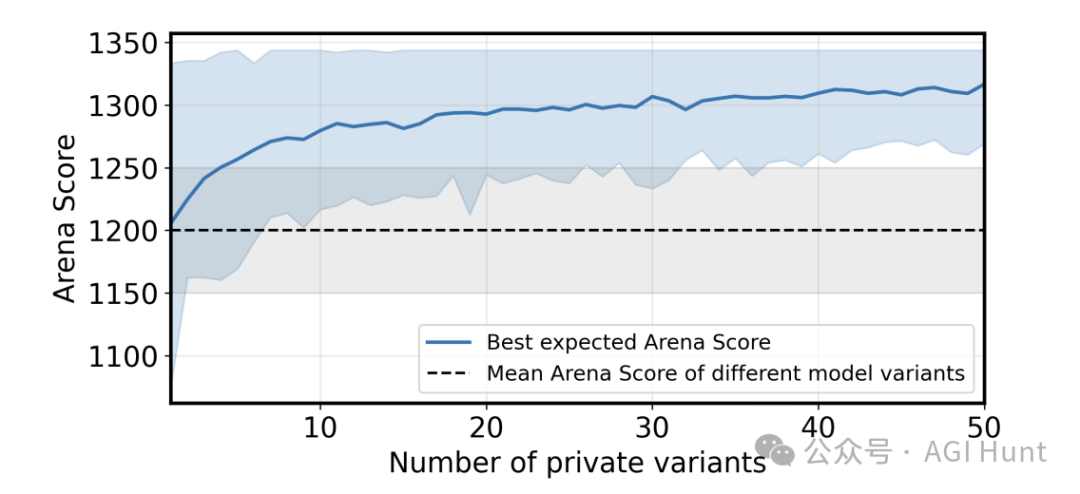
研究人员通过实验证明,这种「最佳-N选择」策略会系统性地提高Arena分数,违背了基础的布拉德利-特里模型(Bradley-Terry model)假设。
元宇宙AI研究者Stella Biderman对此评论道:
这真令人失望。LLM社区已经很难信任公司发布的数字,但@lmarena_ai通常被视为可信的独立机构。看起来这种信任被误置了。
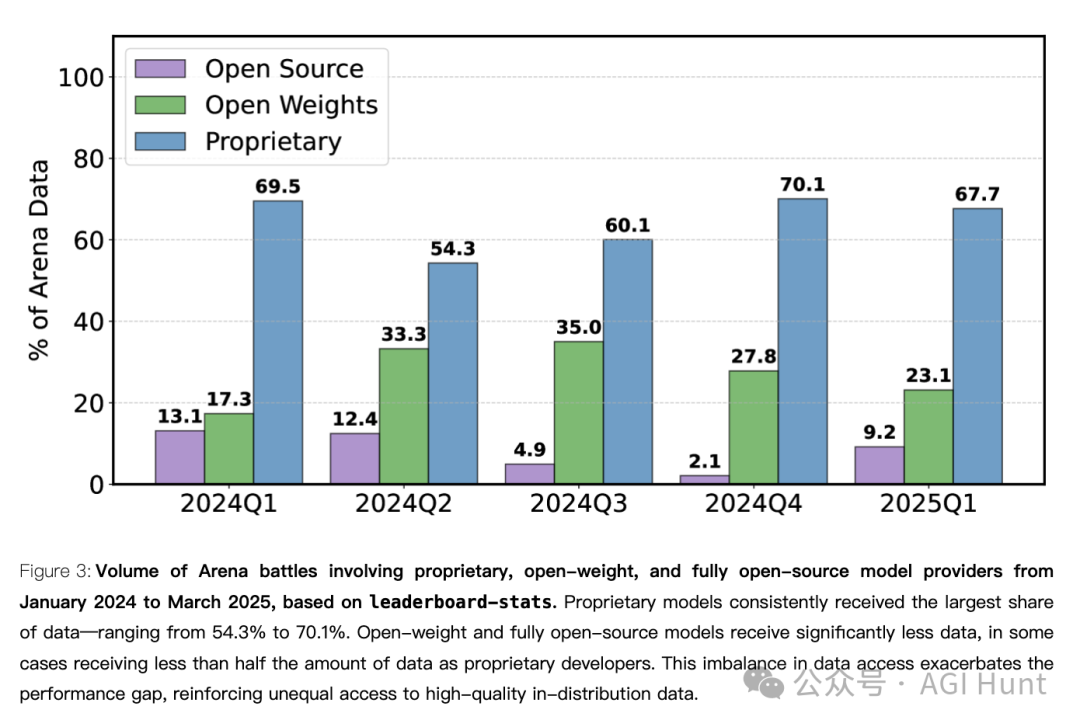
数据获取不平等:开源模型被严重边缘化
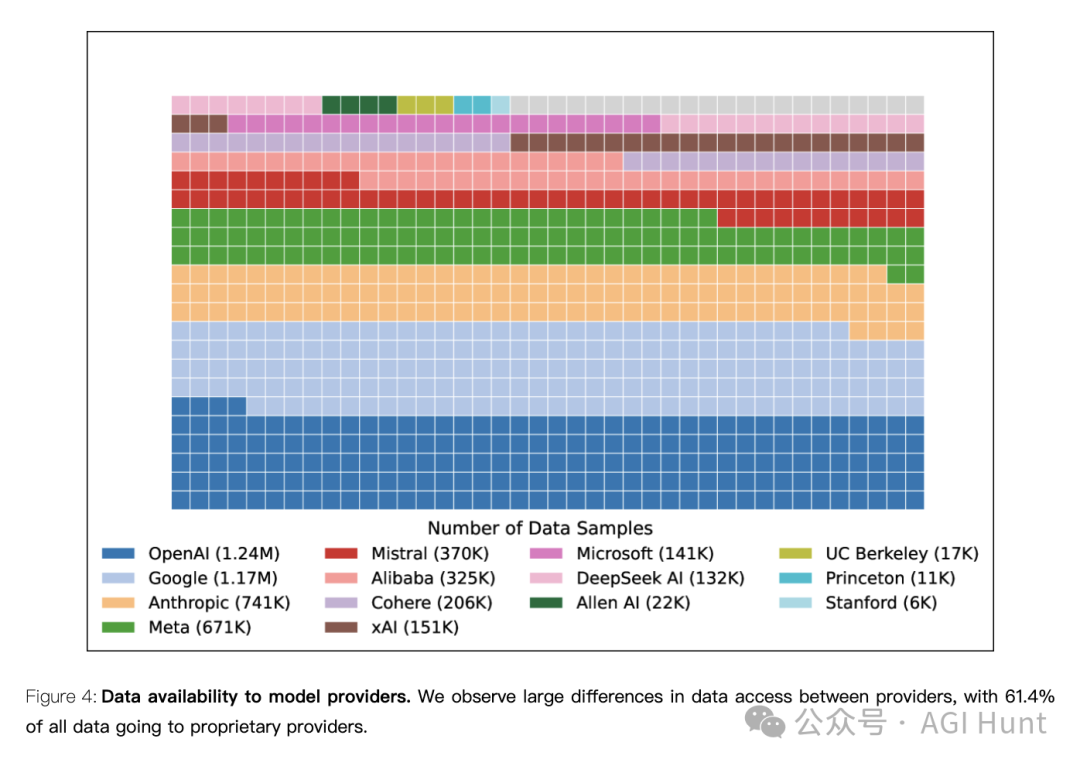
研究发现,用户在Chatbot Arena上贡献的宝贵反馈数据分配极不平等。
尤其令人震惊的是:
-
OpenAI和Google分别获得了约20.4%和19.2%的所有测试数据
-
而全部83个开源权重模型加起来只获得了约29.7%的数据
-
学术和非营利机构(如Allen AI、斯坦福、普林斯顿和加州伯克利)的总份额仅为0.9%
这种不平等来源于多个因素:私下测试的模型数量、采样率差异、模型下线政策,以及API支持模式。

比如,研究者观察到OpenAI和Google的模型每天最高采样率达到34%,而其他提供商如Allen AI的采样率要低10倍。
Stella Biderman在此问题上声明:
利益冲突声明:@AiEleuther的lm eval harness可以说是Arena的竞争对手。一些公司使用我们的库来发布提示和脚本以重现他们的结果。我们为用户提供这些选项,以便他们可以进行跨模型的苹果对苹果比较。
数据获取优势带来巨大性能提升
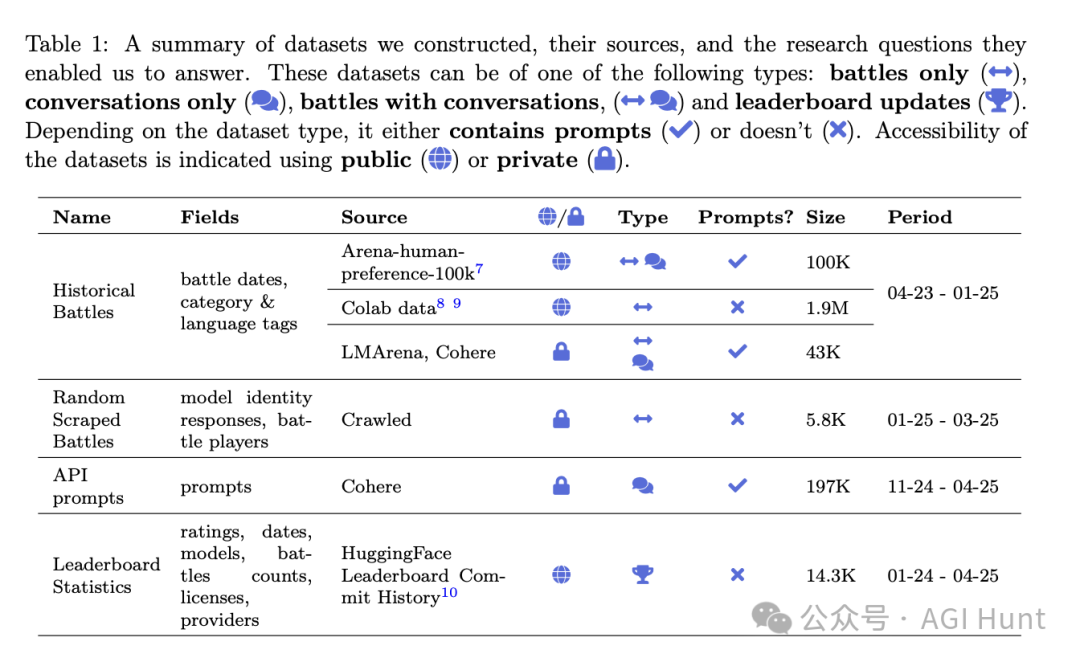
研究团队进行了控制实验,证明拥有Arena数据可以显著提高模型表现。他们在固定训练预算下,调整Arena数据与非Arena指令数据的比例,发现:
-
在ArenaHard测试集上,增加Arena数据(从0%到70%)使胜率从23.5%提升至近50%
-
这意味着模型表现提升了惊人的112%
-
而这还只是保守估计——大型实验室拥有的数据更多
这说明了拥有Arena数据确实能带来显著的排名优势,而这种优势主要被少数大型商业实体独享。
Stella Biderman进一步解释:
我们的目标是提供更好的评估数字透明度,使研究人员能够轻松比较各种基准测试中的不同模型。在过去,我们被要求对模型进行私人评估并分享结果。我们始终拒绝这样做。
模型下线政策缺乏透明度
研究发现Chatbot Arena的模型下线政策存在严重问题:

-
在243个公开模型中,205个已被悄悄下线,远超官方列为已下线的47个模型
-
开源权重和完全开源的模型下线率高达87.8%和89%,而专有模型的下线率较低,为80%
这种不平等的下线政策,加上评估条件的变化,严重影响了排名结果的可靠性。


研究者通过模拟实验证明,当评估条件随时间变化时,提前下线模型会违反布拉德利-特里模型的传递性假设,导致排名失真。
数据不对称=精准过拟合
研究团队把 Arena 真实对话按 0 %、30 %、70 % 不同比例混入同等训练预算的 SFT 样本中:在 ArenaHard 集上,30 % 配比模型赢率暴涨 81 %,70 % 配比甚至翻倍达 112 %,可在 MMLU 上反而略降。

这证明拿到 Arena 数据的公司能「定向打榜」而非全面提升。
恢复公平:五项关键建议
研究团队提出了五项关键建议,以恢复Chatbot Arena的公平性和可信度:
-
禁止提交后撤回分数:所有模型评估结果必须永久公开,不得选择性隐藏
-
限制每个提供商的私有模型数量:建立透明的限制(如每个提供商最多同时测试3个模型变体)
-
确保模型下线平等应用:对专有、开源权重和开源模型采用相同的标准
-
实现公平采样:回归Arena组织者自己提出的主动采样方法
-
提供透明度:公开所有被下线的模型信息
Chatbot Arena作为一个由社区驱动的开放榜单,在AI社区中已经扮演了重要角色。
但如果没有公平和透明的机制,它可能会导致研究者和开发者为了榜单表现而非真正的模型能力进行优化,最终阻碍整个领域的真正进步。
如研究人员所说:
「要诚实地衡量进步,我们需要可靠、公平的基准。」
虽然 Arena 对社区贡献巨大,但若不尽快堵上漏洞,「排行榜幻觉」将继续误导资本、研究方向与公众认知,公平竞争也将成为空谈。
是时候对Chatbot Arena进行一些必要的改革了。

信任基石已被撬动,接下来何去何从?
——轮到 Arena 给出回应。
不得不说,世界真是个巨大的草台班子啊!
处处都是关系,处处都是利益,处处都是人情世故啊!
论文地址:
https://arxiv.org/pdf/2504.20879v1
(文:AGI Hunt)