

作者:Henry Zhu
机器之心编译
在 AI 领域里,大模型通常具有百亿甚至数千亿参数,训练和推理过程对计算资源、存储系统和数据访问效率提出了极高要求。
2 月 28 日,DeepSeek 开源了一种高性能分布式文件系统 3FS,官方表示其目的是解决人工智能训练和推理工作负载的挑战。
作为一种并行文件系统,3FS 可以在 180 节点集群中实现 6.6 TiB/s 的聚合读取吞吐量,对于提高 DeepSeek V3、R1 大模型的训练数据预处理、数据集加载、检查点保存/重新加载、嵌入向量搜索和 KVCache 查找等工作的效率有重要帮助。
人们认为,DeepSeek 通过开源 3FS 与 smallpond 等工具,在 AI 基础设施领域树立了新的设计范式。其价值不仅在展现技术实力,更是在驱动核心基础设施创新。
DeepSeek 提出的文件系统是如何运作的,又能如何提高模型效率?最近,来自伊利诺伊大学厄巴纳-香槟分校的在读博士生 Henry Zhu 对 3FS 进行了解读。
以下是博客原文:
什么是 3FS?
3FS(Fire-Flyer File System)是 DeepSeek 在开源发布周期间发布的分布式文件系统,旨在充分利用现代固态硬盘(SSD)和远程直接内存访问(RDMA)网络的全部带宽,能够加速和推动 DeepSeek 平台上所有数据访问操作。
本文将深入探讨什么是分布式文件系统以及 3FS 的运作方式,首先介绍一些背景知识。
什么是分布式文件系统?
分布式文件系统会欺骗应用程序,使其以为它们正在对一个常规的本地文件系统进行通信。这种抽象非常强大:一个实际上分散在 10 台不同机器上的文件,看起来就像一个简单的文件路径,例如 /3fs/stage/notes.txt。

使用分布式文件系统与使用本地文件系统并无二致。
在上图中,我们通过运行 mkdir 和 cat 命令在本地和分布式文件系统上创建了相同的文件夹和文件,命令完全相同。使用分布式文件系统,所有这些细节都被抽象出来,用户只需操作文件即可,无需担心后台涉及多少台机器、有多少网络调用或多少硬盘。
分布式文件系统的优势
与本地存储相比,分布式文件系统主要有两大优势:它们可以处理海量数据(高达 PB 级),并提供超越单机能力的高吞吐量。它具备容错能力(即使一台机器宕机,系统仍能继续运行)和冗余能力(即使一个节点上的数据损坏,其他节点仍可获得原始副本)。
分布式文件系统广泛应用于许多实际应用:
-
并行处理框架(支持 Spark 的 HDFS);
-
带有数据加载器和 check point 的机器学习训练流水线;
-
由 Google Colossus 支持的内部大型代码/数据存储库;
-
旅行等行业应用;
-
照片存储服务等业务。
深入了解 3FS
那么,DeepSeek 开源的 3FS 是如何工作的呢?
它的核心由四种主要节点类型组成:
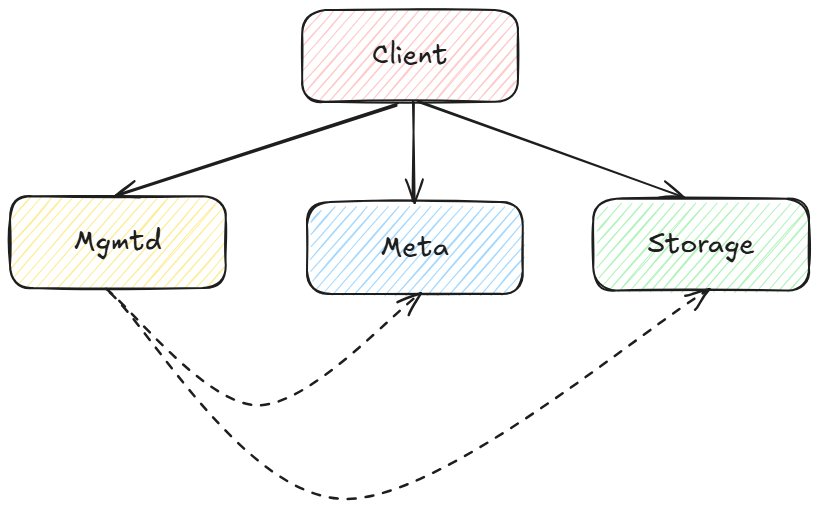
3FS 中涉及的组件。
这些组件的作用各不相同:
1. Meta – 管理元数据:文件位置、属性、路径等;
2. Mgmtd – 管理服务器控制集群配置:其他节点在哪里、哪些节点处于活动状态以及复制系数;
-
可以将其视为一个路由器,它知道每个节点的地址,并可以帮助节点相互查找。(类似的类比是 NAT hole 中使用的集中式服务器)
3. Storage – 保存物理磁盘上实际文件数据的节点;
4. Client – 与所有其他节点通信以查看和修改文件系统:
-
请求 Mgmtd 发现其他节点
-
请求 Meta 服务器执行文件操作(打开、统计、关闭、符号链接)
-
与存储节点传输数据
现在让我们更详细地了解每个组件。
Mgmtd
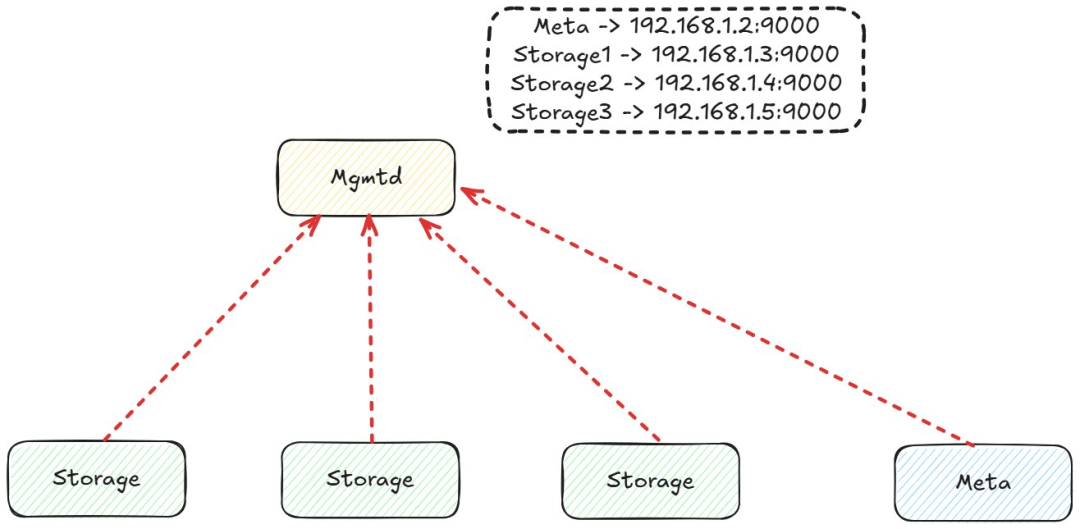
Mgmtd 注册
Mgmtd 跟踪集群中正在运行的节点。存储节点和元节点在启动时会注册,并定期发送心跳信号以确认它们仍然处于活动状态。这提供了系统的集中视图,可以立即识别哪些节点处于宕机状态。
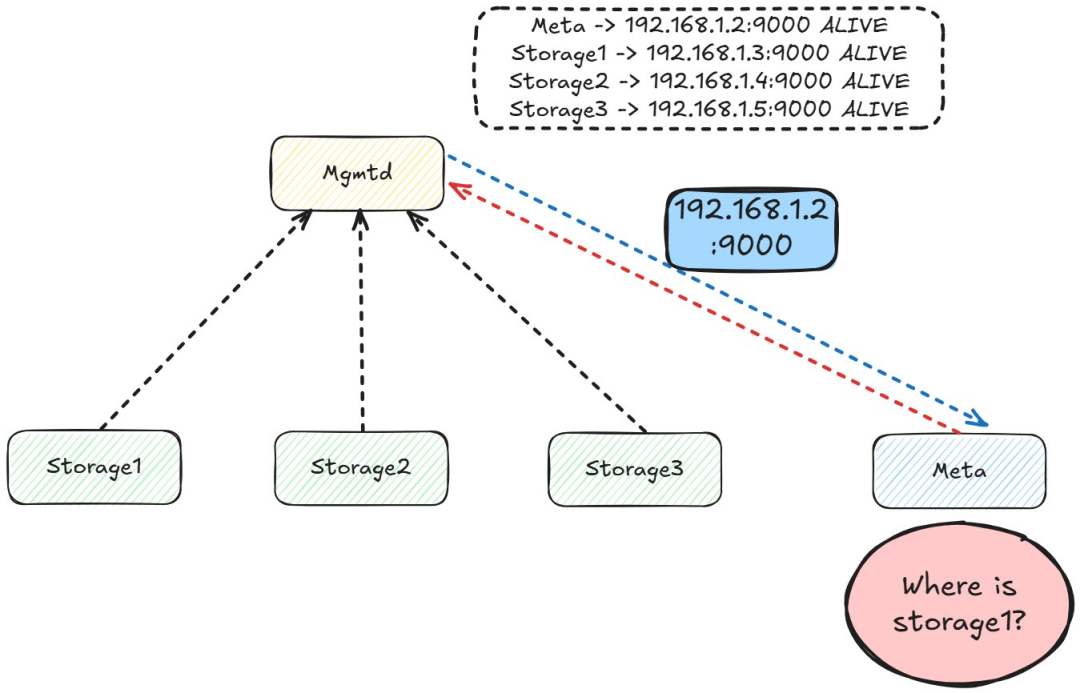
管理请求
节点无需与网络中其他所有节点保持连接。相反,它们可以通过查询管理节点来发现节点。虽然这会增加定位节点的额外往返次数,但由于节点发现并不静态的,因此可以降低复杂性。
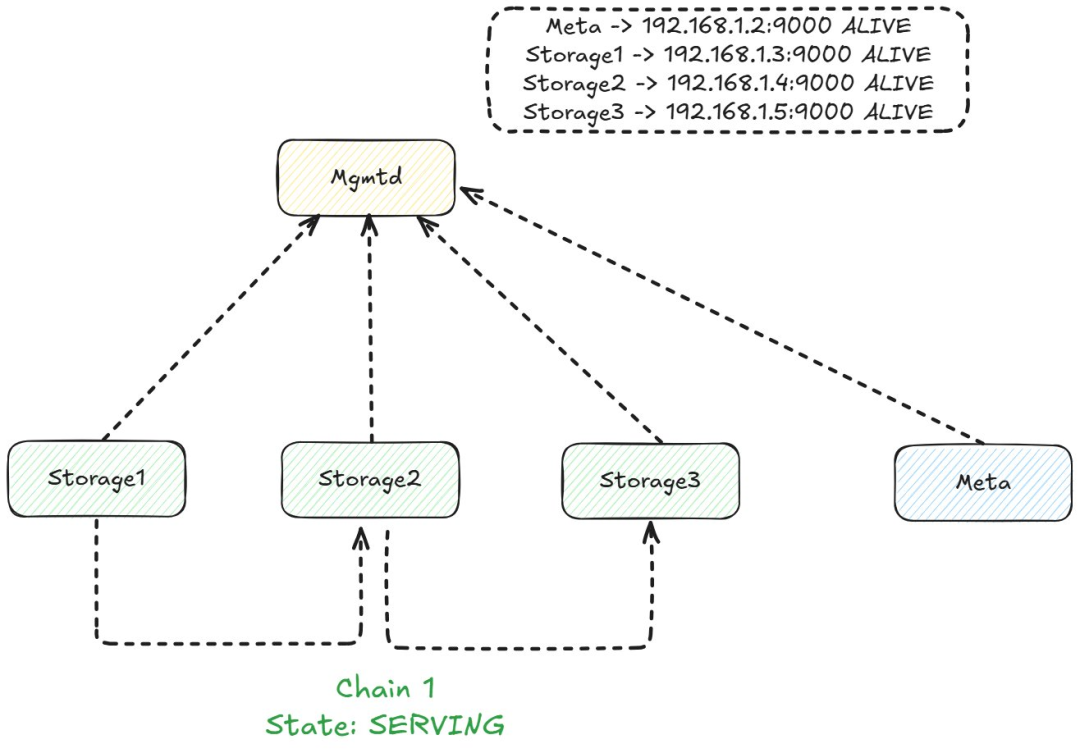
Mgmtd 链。
此外,Mgmtd 维护分布式算法中不同节点的配置。具体来说,复制链(CRAQ 是一种非常简洁的算法,通过将节点视为链来实现强一致性和容错性。)被建立,其节点作为配置存储在 mgmtd 中。
Meta
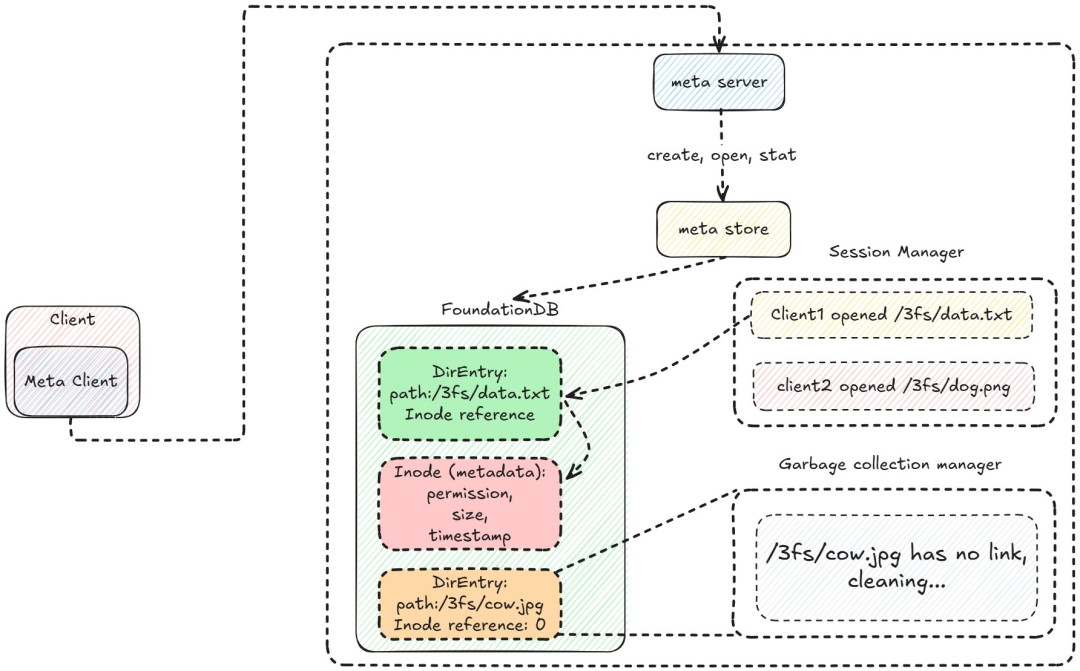
Meta 概览。
元节点比 mgmtd 稍微复杂一些。客户端通过 RPC 调用与其通信。元服务器在元存储上执行典型的文件系统操作(打开、创建、统计、取消链接)。文件元数据驻留在 inode 中,存储大小、权限、所有者和时间戳等属性。DirEntry 对象将路径映射到 inode,单个文件可以有多个 DirEntry(类似于符号链接)。inode 和 DirEntry 都存储在 FoundationDB 中。
有人可能想知道 founationdb 的键是什么样的?inode:「INOD」+ inode id,dir entry:「DENT」+ nodeid + path,使用 transaction 进行幂等操作。会话管理器跟踪打开的文件,并将文件会话存储在 FoundationDB 中。如果客户端断开连接但未关闭文件,会话管理器将启动文件同步。文件删除请求排队到垃圾收集器,垃圾收集器会在删除目录条目和 inode 之前从存储节点中删除数据。
Storage
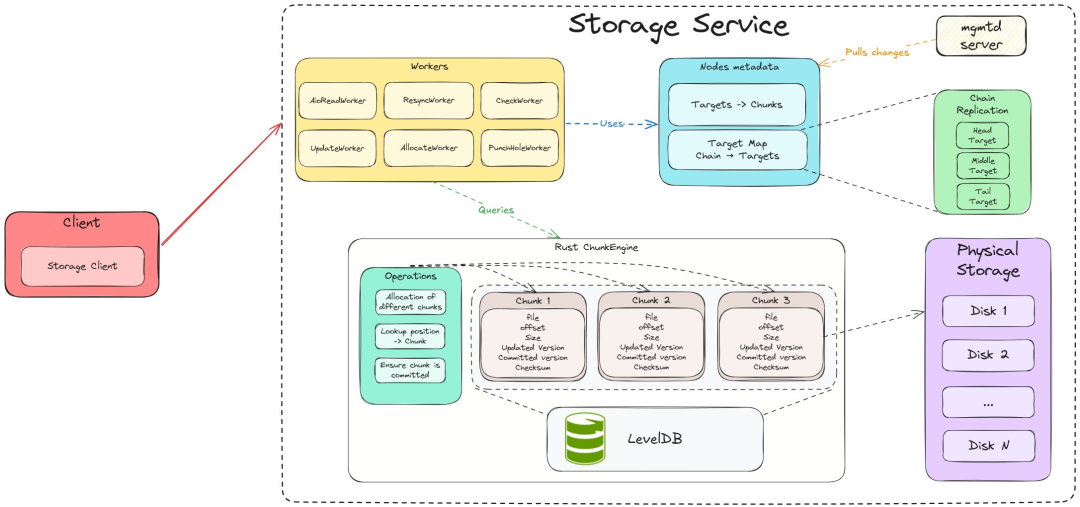
存储概览。
存储节点的主要功能是通过将数据分解成块来管理物理存储上的数据:
Rust 有一个名为 ChunkStore 的旧版块管理器,是用 C++ 编写的。我不太明白为什么是用 Rust,可能是因为它用起来很有趣,而且提供了更安全的保障,可以跟踪磁盘存储块。
-
Chunk 代表一块物理磁盘,并跟踪其元数据(ID、大小、磁盘偏移量、物理磁盘、校验和、版本等)。这是所有其他结构用来跟踪数据块的最原始数据结构。
-
Chunk 引擎不允许用户直接与 Chunk 交互,因为这会增加引擎使用的复杂性。引擎接口提供了一些操作,为用户提供了一种严格清晰的与引擎交互的方式(查找、分配、提交、元数据等)。
-
默认情况下,所有这些数据都存储在 LevelDB 中,前缀字节表示操作类型(查询元数据),并以 Chunk ID 作为键。
不同的 Worker 使用块引擎来维护物理存储
-
AllocateWorker 在块引擎中分配新的块
-
PunchHoleWorker 回收不再使用的块
-
AioReadWorker 处理对块的读取请求,并将读取请求放入 io_uring 队列,提交并等待完成
起初,我感到很惊讶。块引擎并不对实际的物理磁盘执行操作,它实际上只管理元数据。这样做的原因之一可能是为了让 ChunkEngine 实现保持精简,让它只负责管理元数据。
存储节点需要知道如何将写入操作转发到 CRAQ 链中的下一个目标。
目前,只需知道写入操作需要转发到其他节点即可。
-
目标由多个块组成(可以将其视为包含不同块的逻辑存储)。
-
一个链由多个目标组成(通常跨越多个节点)。
-
存储节点向 mgmtd 服务器查询其他节点的链,以及该链中写入操作需要转发到的相应目标(节点)。
CRAQ
CRAQ(Chain Replication with Apportioned Queries)是一种实现强一致性和线性一致性的协议。它是确保数据块容错的核心机制。这里将解释 CRAQ 的工作原理,并展示其在 3FS 中的实现。
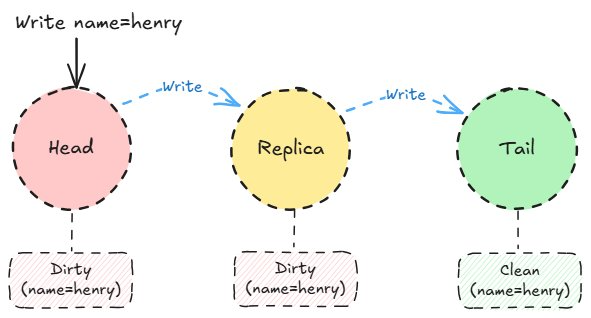
Craq 写入传播。
写入操作从头部开始。在我们的示例中,我们将 name=henry 写入系统。随着写入操作沿链向下移动,每个条目都会被标记为「脏」,并附带一个版本号。脏条目不可安全读取。一旦写入操作到达尾部,它就会被提交并标记为「干净」。
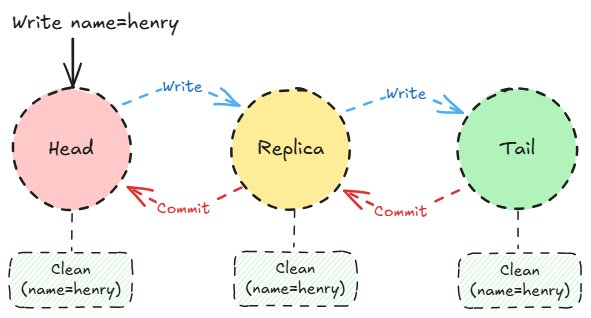
Craq 写入提交。
随着提交消息从尾部向头反向传播,写入操作将变得干净。每个节点提交该条目并将其标记为干净。
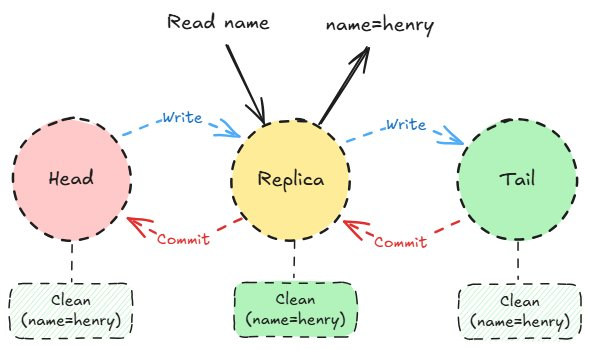
Craq clean read
对于读取来说,过程很简单:如果对象是干净的,则立即将其返回给客户端。
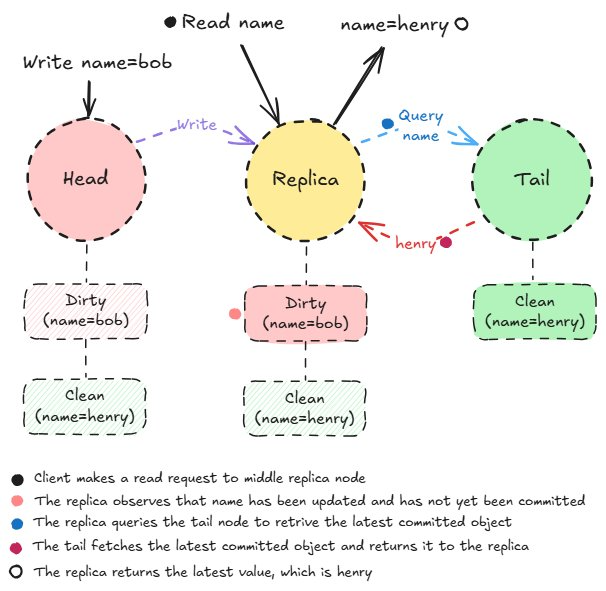
Craq dirty read
挑战发生在脏对象上。每个链都会跟踪脏版本和干净版本。由于尾部始终包含最新提交的数据,因此副本会查询尾部以获取最新提交的对象,从而确保强一致性。
CRAQ 性能
CRAQ 的读写性能因工作负载而异。写入吞吐量和延迟受链中最慢节点的限制,因为写入必须按顺序处理每个节点。例如,在 Zipfian 工作负载(其中频繁访问的数据占主导地位)中,读取性能会受到影响,因为对象可能很脏,从而迫使查询到尾部节点。这会造成瓶颈,因为尾部必须处理大多数读取请求。
如何在 3FS 中使用 CRAQ
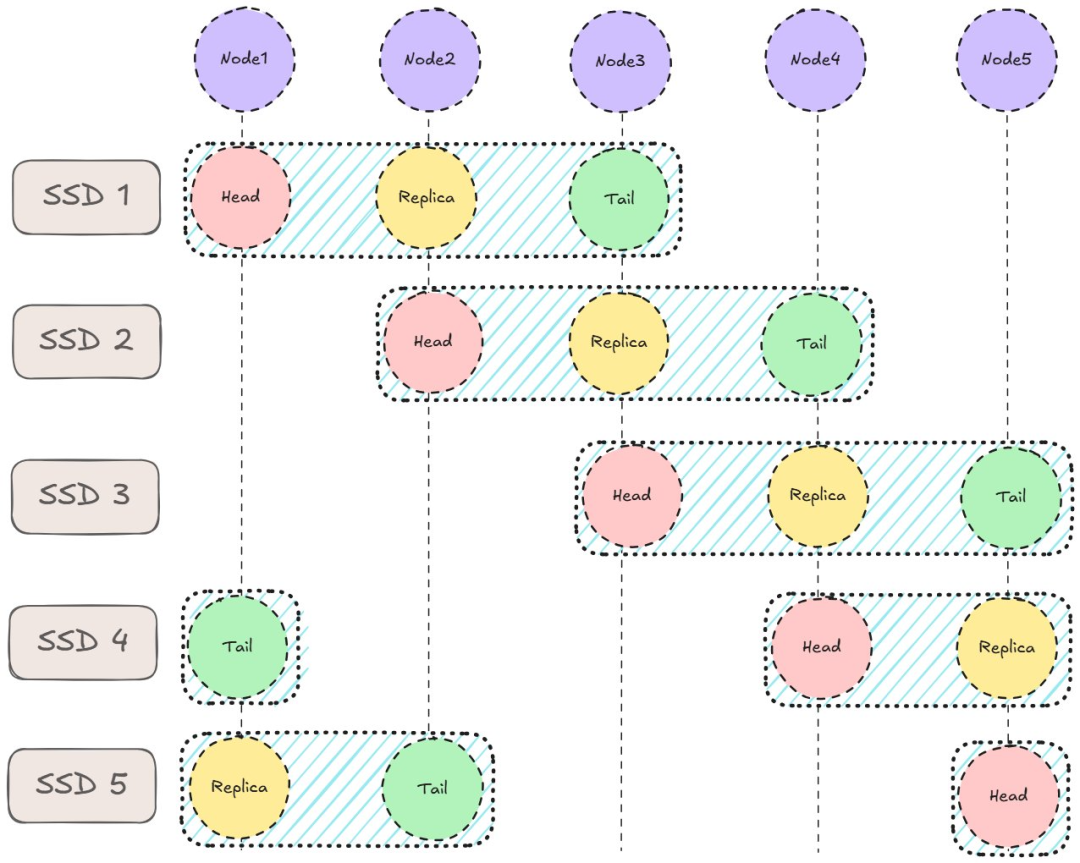
存储采用条带化,CRAQ 在其上运行。
在本例中,集群由 5 个节点组成,每个节点配备 5 个 SSD。存储目标复制到 3 个节点,旨在避免数据重叠,从而避免节点故障大幅影响整体吞吐量。
考虑一个极端场景,所有链都部署在节点 1、2、3 上。如果节点 1 发生故障,分布式系统将损失总吞吐量的 1/3,而不是上图所示的 1/5。3FS 设计说明中提供了一个示例,并进行了更深入的解释。CRAQ 在顶层运行,管理头、中、尾节点。
3FS 默认采用强一致性读取。写入操作从头到尾,再从头到尾,吞吐量受最慢节点的限制,延迟由所有链节点的总延迟决定。
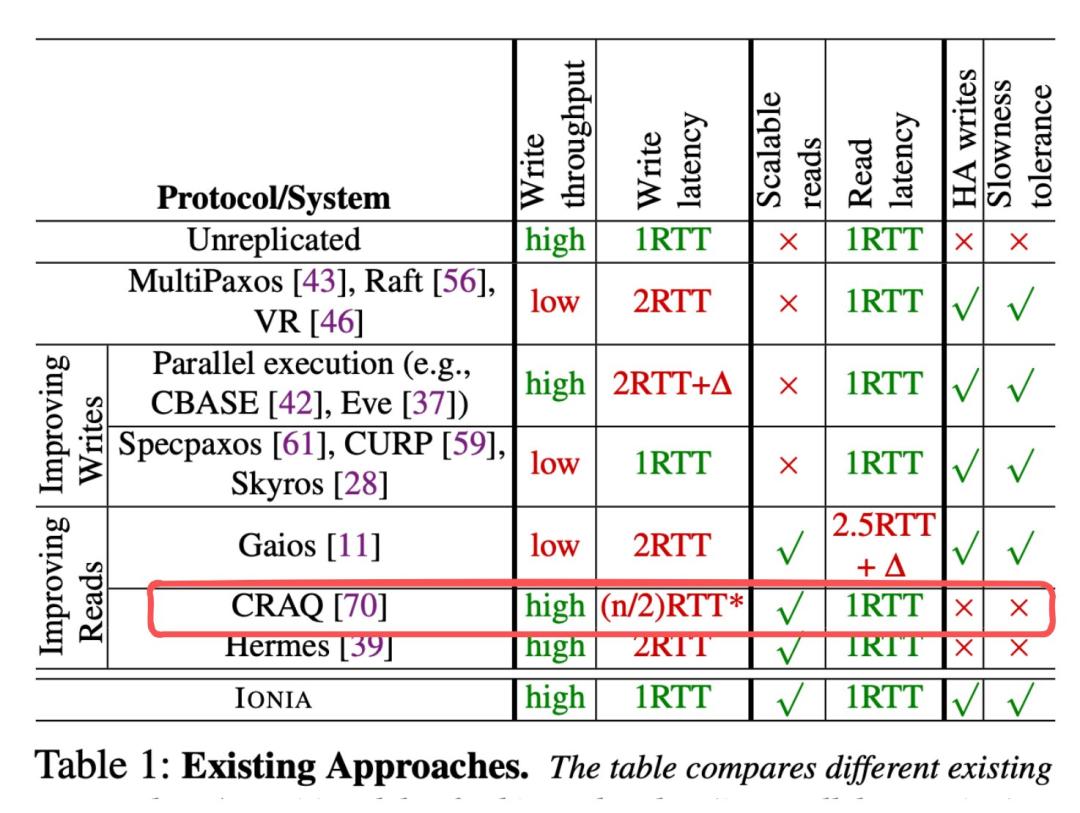
不同复制协议比较表。
如上表所示,在常见情况下,与其他协议和系统相比,CRAQ 以高写入延迟为代价,实现了可扩展的低延迟读取。
其他分布式文件系统
这时候有人可能会问了:这种架构与其他分布式文件系统有什么不同?从高层次来看,这些组件很常见,几乎每个分布式系统中都会出现客户端、元数据、存储和管理节点的概念。
区别在于其实际适用性和实际实现:
-
它擅长处理哪些工作负载
-
它的调优灵活性
-
部署简便性
-
吞吐量扩展能力
-
在服务等级目标 (SLO) 内保持延迟
-
可靠性
以及决定其可用性的更精细的技术细节:
-
存在哪些瓶颈
-
如何管理瓶颈
-
它的锁定方法(或不使用锁定方法)
-
采用的具体数据结构
-
软件设计所针对的硬件
-
使用哪种容错算法或纠删码
考虑到这一点,我想深入分析一下这个相对较新的开源分布式文件系统的性能。分布式文件系统的开发具有挑战性,目前的基准测试相当有限,我们也还没有将 3FS 与单节点系统和其他分布式文件系统的比较,因此很难评估它的性能。
还有一些问题是值得探讨的:
-
DeepSeek 的一些说法是否成立,尤其是关于 FUSE 瓶颈的说法?
-
我们能以某种方式复现他们的性能图吗?
-
在什么情况下性能会下降?
-
系统的瓶颈是什么(CPU/内存/磁盘/网络)?
-
这个文件系统在哪些类型的工作负载下表现优异?
-
与其他分布式文件系统相比如何?
-
它如何解决现有系统面临的问题?
-
我能对系统进行一些改进吗?
在本系列文章的其余部分中,作者将经历做出初步假设、测试它们以及从差异中学习的过程,以更深入地了解 3FS 的实际表现。
参考原文:
https://maknee.github.io/blog/2025/3FS-Performance-Journal-1/
©
(文:机器之心)