来自AI开源社区的技术智慧碰撞,激发了意想不到的创新火花。
SGLang团队在最新公布的一篇技术博客中,提供了一个开源、在96个H100 GPU上部署具有PD分解和大规模专家并行性DeepSeek模型的方法,有望将DeepSeek模型性价比和算力压榨拉到新水平。
SGLang是一款用于大语言模型和视觉语言模型的快速服务框架,目前在Github开源社区获得了14.1K星,技术影响力不断壮大。
该项目由开放研究组织LMSYS Org发起,得到了包括英伟达、AMD、谷歌、甲骨文、xAI、斯坦福大学、加州大学伯克利分校等诸多大厂和高校的赞助支持。
据悉,此次优化改进实现了与DeepSeek官方报告的吞吐量相当的水平,与使用相同资源的原生张量并行相比,优化策略将模型输出吞吐量提高达5倍,通过在本地部署实现,其成本为每100万个输出token 0.20美元,约为官方DeepSeek Chat API成本的五分之一。
此举赢得了英伟达官方发帖祝贺,从算力角度看,SGLang对DeepSeek-R1最新的推理优化使得H100的性能在短短4个月内提升了26倍。
虽然这并不是最新一代AI模型,但考虑到DeepSeek模型的广泛应用和渗透,不少开发者认为这仍算是一个重大里程碑事件,目前SGLang团队把所有实验和代码均完全开源,以供社区访问和进一步开发。
DeepSeek以开源路径实现堪比OpenAI顶尖封闭模型的性能而备受开发者赞誉,然而,由于其参数规模庞大,且采用了多头潜在注意力(MLA)和混合专家(MoE)的独特架构,要实现大规模的高效服务部署并不容易。
在这篇最新博客中,SGLang团队详细阐述了如何使DeepSeek的推理系统性能与SGLang相匹配,进而实现全新的性价比进阶。
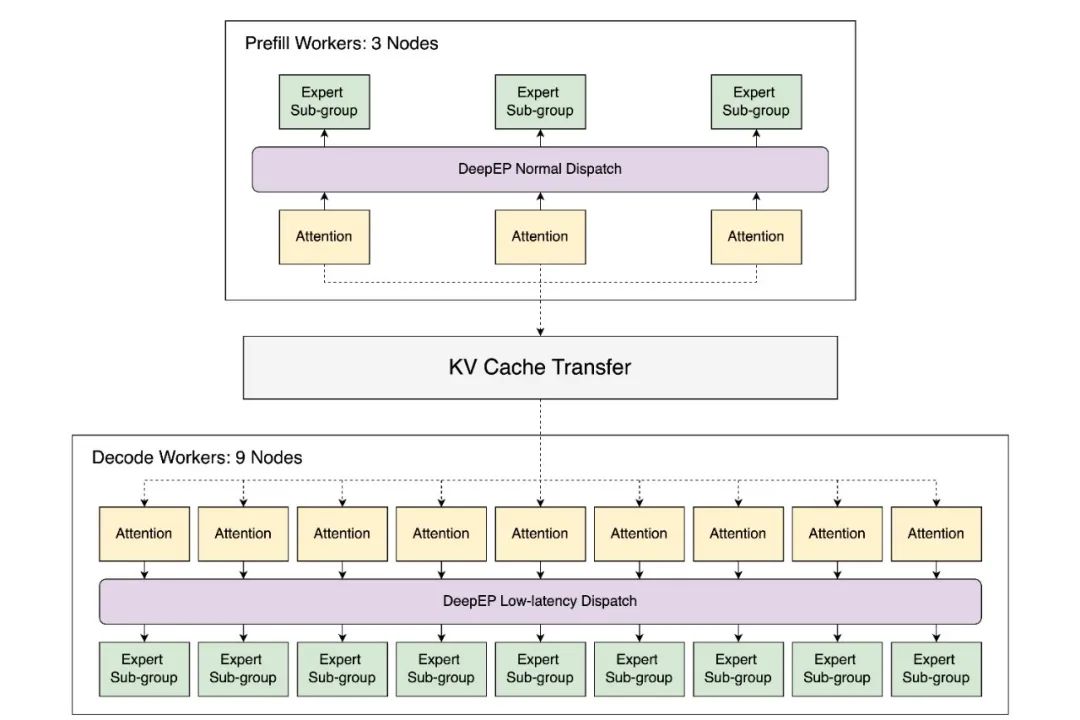
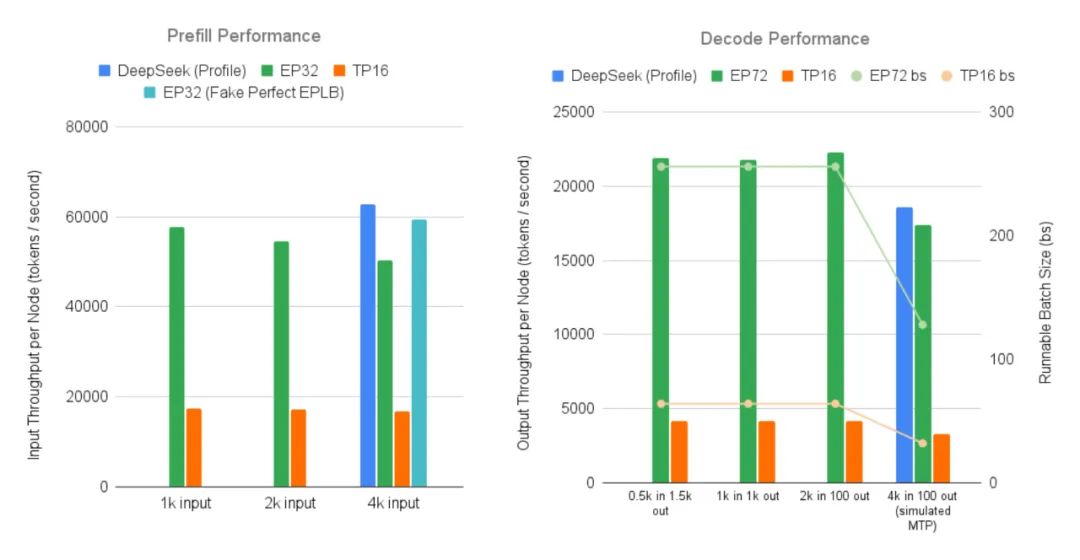
研究人员在Atlas Cloud的12个节点上复制了DeepSeek的完整推理系统,每个节点配备8块H100 GPU,采用预填充解码分解和大规模专家并行(EP)技术,对于2000个token的输入序列,每个节点的速度达到每秒52.3k个输入token和每秒22.3k个输出token。
高效的并行性对于管理DeepSeek架构的计算复杂度和内存需求非常。
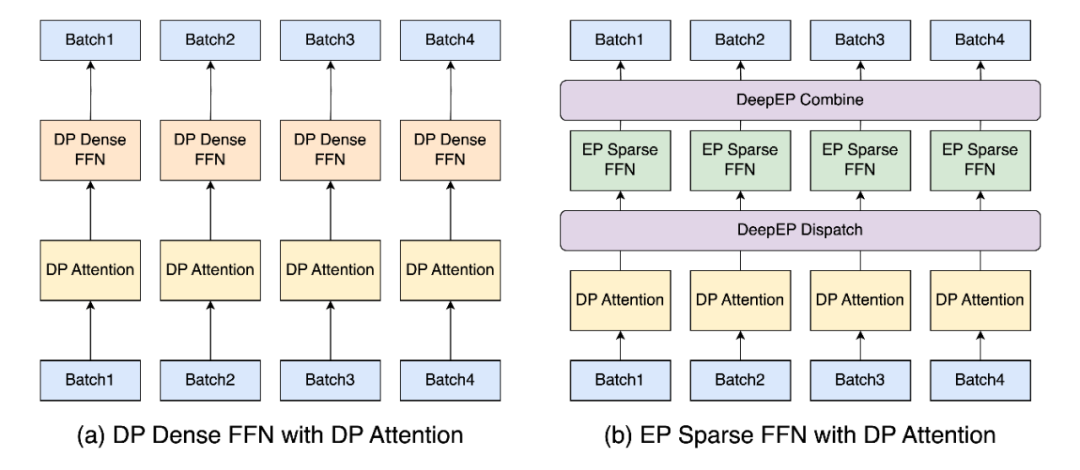
SGLang优化关键组件的方法体现在:注意力层、密集前馈网络(FFN)、稀疏FFN以及语言模型(LM)头等方面,每个组件都利用定制的并行策略来增强可扩展性、内存效率和性能。
LLM推理通常包含两个不同的阶段:预填充和解码。预填充阶段是计算密集型,需要处理整个输入序列;而解码阶段是内存密集型,需要管理用于生成token的键值(KV)缓存。
这两个阶段传统方法下通常由一个统一的引擎处理,但预填充和解码批次的混合调度会导致效率低下,为了应对这些挑战,研究人员在SGLang中引入了预填充和解码(PD)分解功能。
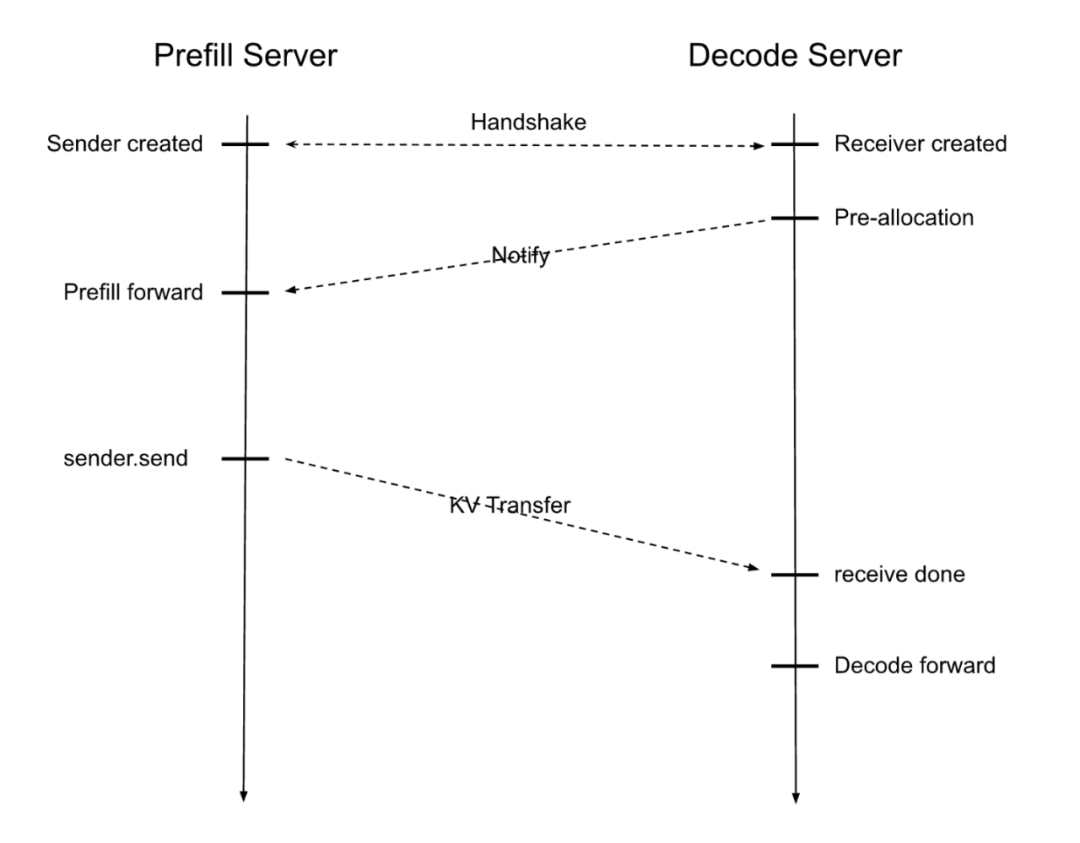
PD分解设计在预填充服务器和解码服务器之间交错执行,从而可以针对每个阶段进行定制优化。收到输入请求后,模型工作流程如下:
1、预填充服务器和解码服务器通过配对,分别建立本地发送方和接收方。
2、解码服务器预先分配KV缓存,向预填充服务器发出信号,开始模型前向传递并计算KV缓存。
3、一旦计算完成,数据就会传输到解码服务器,由其处理迭代令牌生成。
这种方法确保了每个阶段都在最佳条件下运行,从而最大限度地提高GPU资源利用率。
SGLang现在支持DeepSeek开发的DeepEP、DeepGEMM和EPLB的全部功能。
DeepEP是由DeepSeek团队实现的通信库,旨在简化MoE模型中的EP流程,解决了如何高效地将token路由到跨多个GPU的特定专家的难题。
在SGLang中,DeepEP集成提供了自动模式,可根据工作负载在两种调度模式之间动态选择,这种集成通过将调度模式与每个阶段的特定需求相结合,优化了资源利用率并提升了整体性能。
SGLang还集成了DeepSeek团队开发的另一个高效库DeepGEMM,用于在张量并行下进行MoE计算,将DeepGEMM与DeepEP的调度模式进行了无缝集成。
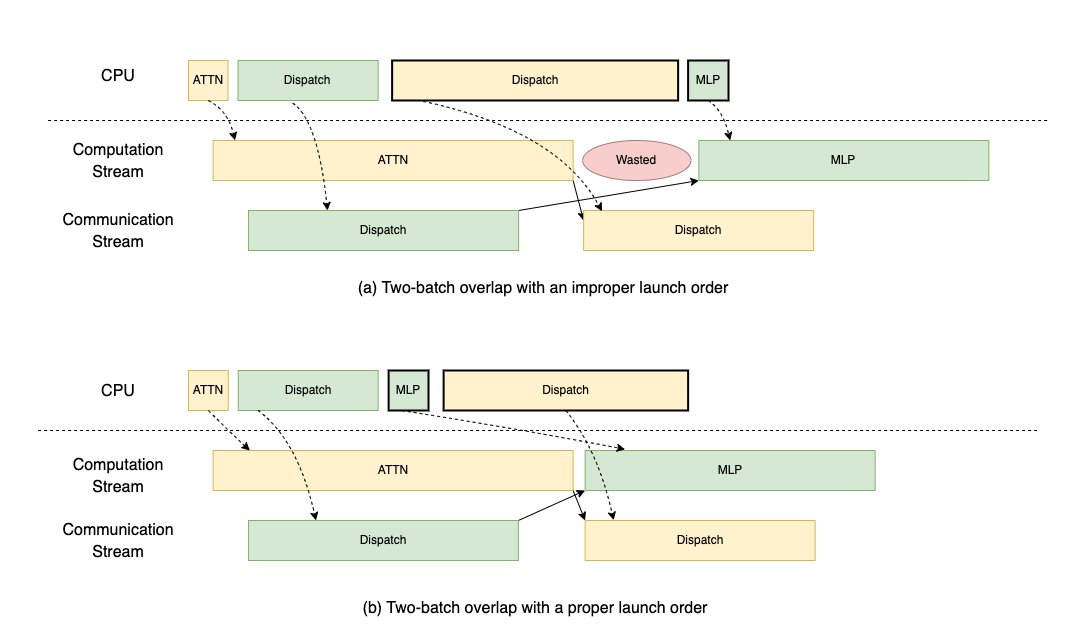
在多节点环境中,有限的通信带宽会显著增加整体延迟。为了应对这一挑战,SGLang团队遵循DeepSeek的系统设计,实现了双批次重叠(TBO),将单个批次拆分为两个微批次,允许计算和通信重叠,同时通过将有效批次大小减半来降低峰值内存使用量。
此外,在MoE模型中,EP通常会导致GPU之间的工作负载分配不均,这种不平衡迫使系统等待最慢的GPU计算或通信,从而浪费计算周期,并因专家激活而增加内存占用,随着GPU数量的增加,不平衡问题会变得更加严重。
为了解决这个问题,DeepSeek开发了专家并行负载均衡器 (EPLB),但即使有了EPLB,一些不平衡也难以避免,因此SGLang分三个阶段实施了专家重新平衡,以确保效率和最小干扰:
1、系统加载阶段:权重可以选择从磁盘预加载到主内存以实现更快的重新平衡,或者使用内存映射(mmap)保存在磁盘上以减少内存使用量。
2、重新平衡准备阶段:所需权重在后台异步传输到设备内存,利用免费的DMA硬件引擎,而不会中断正在进行的GPU操作。
3、重新平衡执行阶段:设备到设备的复制更新权重,此步骤可以通过物理内存重新绑定技术进一步优化。
分阶段的方法可确保重新平衡既高效又无中断,从而在更新期间保持系统性能。
研究人员在一个由12个节点组成的集群上使用DeepSeek-V3评估了不同配置的SGLang端到端性能,凸显了技术优化带来的吞吐量提升。
为了适应不同的工作负载需求,他们分别评估了预填充(P)和解码(D)阶段,并假设非测试阶段拥有无限资源,以隔离并最大化测试节点的负载——这与DeepSeek的设置类似。
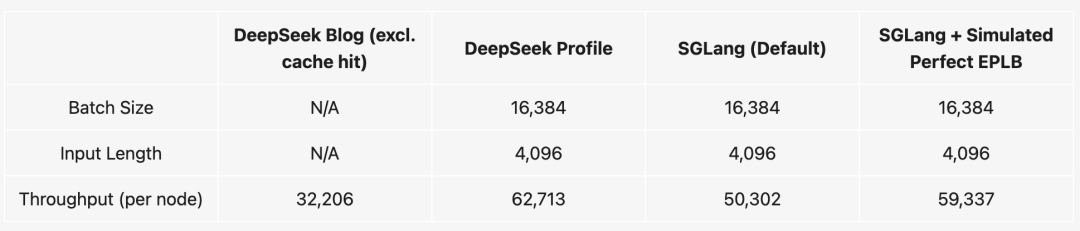
结果显示,预填充阶段,性能比TP16基线提升了3.3倍,吞吐量与DeepSeek官方数据相差在5.6%以内;解码阶段比TP16基准性能提升了5.2倍,仅比DeepSeek的官方数据低6.6%。
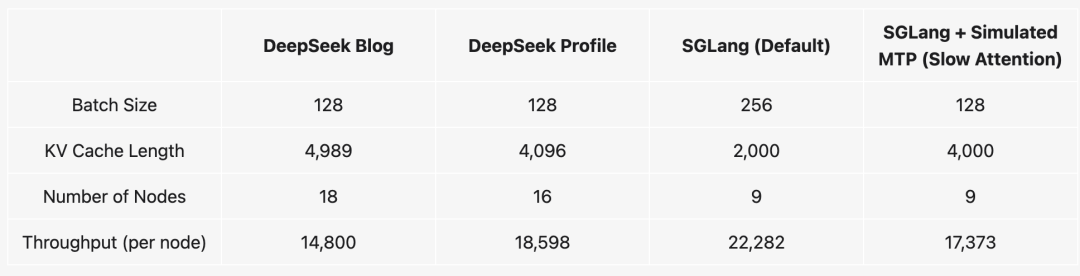
他们还将SGLang的性能与DeepSeek的推理系统进行比较,默认专家不平衡的SGLang比DeepSeek的配置文件慢20%,但模拟的完美EPLB情况将差距缩小至6%。
使用DeepSeek一半的节点模拟MTP的SGLang仅比DeepSeek的配置文件慢一点,在更高的批次大小设置(256个序列,2000输入长度)下,SGLang实现了每节点每秒22282个令牌,展现出强大的可扩展性。
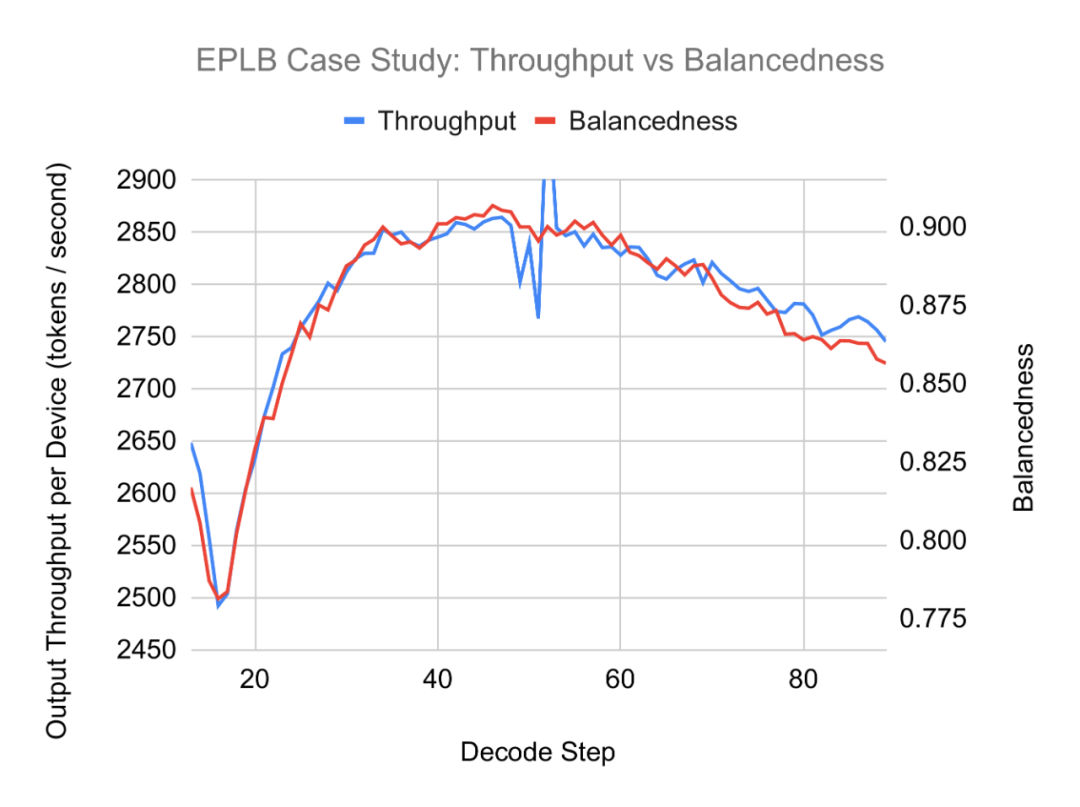
评估结果还显示出专家平衡性和吞吐量之间存在很强的相关性,强调了保持高平衡性以实现最佳性能的重要性。
还有两点值得关注的观察是:
1、专家使用不平衡:大多数专家很少被使用,而一小部分专家却被大量使用,这凸显了MoE模型固有的不平衡性。
2、预填充与解码的差异:虽然预填充和解码分布有相似之处,但也存在显著差异。支持使用PD分解为每个阶段分配不同的专家,从而优化性能。
SGLang还提供了一套工具集,用于分析和模拟MoE模型中专家工作负载的分配。
在技术报告最后,SGLang团队指出未来还有不少技术方向值得持续改进,期待其他技术团队复制和扩展这项工作,例如针对实时用例进一步优化,灵活的张量并行 (TP) 大小等,由于本次实验使用了96个GPU,因此只能生成较短的序列,其他团队可以扩展GPU资源以支持更长的序列。
下一步,SGLang团队表示会扩展对英伟达下一代Blackwell架构的兼容性,以进一步加持DeepSeek等开源模型突破高效AI部署的界限。
(文:头部科技)