
我们缺失了LLM学习的一个重要范式!

前特斯拉AI总监、OpenAI创始团队成员Andrej Karpathy 抛出了一个重磅观点:LLM正缺少一种关键的学习范式,他称之为「系统提示学习」(system prompt learning)。

这次Andrej 所讨论的,不再是某个具体的技术细节,而是对整个AI学习机制的重新思考!
三大学习范式对比
Karpathy指出,目前LLM主要依赖两种学习范式:
-
预训练(Pretraining):用于获取知识。
-
微调(Finetuning,包括监督学习/强化学习):用于培养习惯性行为。
这两种范式都涉及参数变化,但Karpathy认为人类的学习更像是系统提示的变化。

他解释道:「你遇到一个问题,找出解决方案,然后以相当明确的方式『记住』这个方法,以备下次使用。」
“这更像是给自己做笔记,而不是调整神经元连接。”
从Claude的系统提示说起
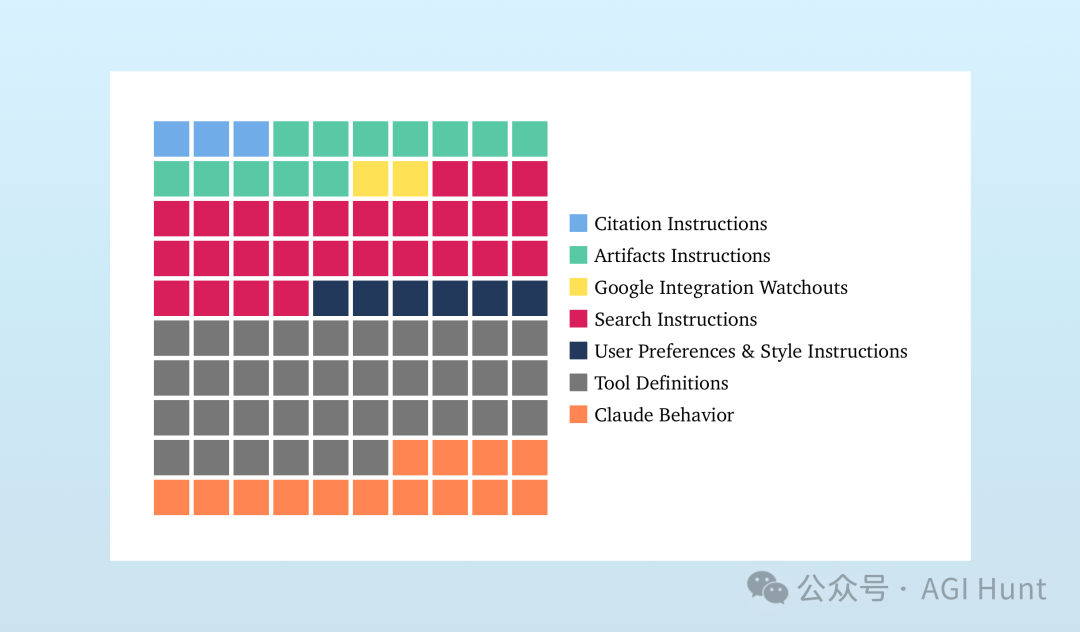
Karpathy这番思考来源于他阅读了Claude的系统提示(system prompt),这个提示长达17,000字!

它不仅规定了AI的基本行为风格和偏好,还包含了大量通用的问题解决策略。
例如,Claude的系统提示中有这样一段:

「如果Claude被要求计数单词、字母和字符,它会在回答之前一步一步地思考。它会明确地给每个单词、字母或字符分配一个数字。它只有在执行完这个明确的计数步骤后才回答问题。」
这是为了帮助Claude解决「草莓中有几个’r’」这类问题。
Karpathy认为,这种问题解决知识不应该通过强化学习直接烙印到权重中,也不应该由人类工程师手写系统提示。

它应该通过「系统提示学习」自动获得。
系统提示学习:LLM的自我进化
什么是系统提示学习?
它类似于强化学习的设置,但学习算法不同(编辑而非梯度下降)。
在这种范式下,LLM的大部分系统提示可以通过系统提示学习自动编写,就像LLM为自己写一本关于如何解决问题的书。
Kevin Nelson(@BootstrAppdAI) 表示认同:
「我们称之为思维过程框架。我们在Bootstrapped A.I.构建的动态潜空间节点图、自播种永久多跳、奖励系统和代理子过程已经为此做好准备。」
一旦这种方法可行,它将成为一种全新而强大的学习范式,尽管还有许多细节需要解决:
-
编辑机制如何工作?
-
是否应该学习编辑系统本身?
-
如何逐渐将知识从明确的系统文本转移到习惯性权重中(就像人类似乎会做的那样)?
深入了解Claude的系统提示
Claude的系统提示让我们看到了AI系统设计的复杂性。根据dbreunig.com的分析,这个长达16,739字(110KB)的提示比OpenAI的o4-mini系统提示(2,218字,15.1KB)长了近8倍!
链接在此:
https://www.dbreunig.com/2025/05/07/claude-s-system-prompt-chatbots-are-more-than-just-models.html
Claude的系统提示主要包含以下内容:
-
工具定义:来自MCP服务器的信息,详细描述了14种不同工具的使用方法和时机。
-
工具使用指令:包括引用指南、制品指令、搜索指令等,所有这些都详细说明了如何在聊天机器人交互中使用这些工具。
-
行为指导:规定了Claude应该如何行为、回应用户请求,以及它应该和不应该做什么。
系统提示中还包含许多「热修复」,看起来是为了解决特定问题而添加的针对性指导,例如:
「如果Claude被要求写诗,Claude会避免使用陈词滥调的意象、隐喻或可预测的押韻模式。」
网友热议
这一概念在AI研究社区引起了热烈讨论,众多专家纷纷发表见解:
DΞSH(@whereislamb0) 完全赞同Karpathy的观点:
「你把这个称为系统提示学习——我认为这是个完美的名字。它抓住了核心思想:与其将新事物’塞进大脑’,不如添加有助于更明智地行动的策略。这就像构建一组名为’如果该怎么办……’的笔记并将它们放在手边。」
他还指出了这种方法的几个优势:
-
需要的数据要少得多
-
支持清晰、透明的学习
-
即使没有外部输入也能工作
-
最重要的是,它可以跨模型传输,无需复制所有权重
Typing Loudly(@typingloudly) 指出:
「需要为LLM建立一个图式理论。或者这实际上是LLM之上的架构元素。LLM应该被视为认知架构的组成部分,而不是最终产品。」
Oded Ben Dov(@odedbendov) 则表示:
「也许这有点像大脑1-大脑2那样的事情。有趣的是,并非所有人都有内在对话!」
Ethai Reubinoff(@EthaiReubinoff) 提出了一个可能的实现方式:
「为什么我们不能使用RL训练系统提示LLM,让系统提示LLM将系统提示写入静态(学生)LLM以尝试解决可验证的问题,然后我们可以训练系统提示LLM导致系统提示成功的原因或类似的事情。」
Luke Jackson(@m31uk3) 展现了对这个话题的极大热情:
「几周来,我一直对这个话题着迷!!用户旅程需要包括对比性Q/A。这就是人类在学习/探索新事物时所做的。我们在”思考”模型中看到了这一点,但是,我敢打赌这种方法会改进所有非零镜头推理。」
Sardor(@randen_ai) 提出了一个实用性问题:
「你认为系统提示的RAG(检索增强生成)在这里可能有用吗?例如,LLM查询向量数据库,找出过去对话中效果最好的系统提示。」
The Canaanite(@mysticaltech) 提出了技术实现方案:
「GraphRAG内存,想想SurrealDB。你获得课程和完整的上下文,它会从初始种子和随着时间的推移吸取的经验教训自动生成最终的系统提示。」
还有研究人员将这一概念与现有技术联系起来。
dmitriy(@DmitriyLeybel) 指出这听起来类似于「reflexion」(一种已有的技术),并分享了相关论文链接。
Daniel Miessler(@DanielMiessler) 认为这可以通过两种主要机制实现:
「深度上下文关于你关心的事物的当前状态,如个人或公司;以及该事物的期望状态(和/或当前问题)的详细上下文。随着上下文大小的增加和模型变得更智能(看到模式和类比),它将更好地确定如何转变。所以不会是一次性的、基于系统提示的学习,而是一种持续的机制,不断将当前问题输入AI。」
挑战与前景
虽然系统提示学习概念令人兴奋,但实践中仍面临诸多挑战。
如Pre Priyadarshane(@Pregeeth)警告的:
「我认为不仅仅是系统提示能在LLM学习中带来重大差异。也许需要一种完全不同类型的记忆。也许是一种类似人类系统的过程,让LLM从经验和与人类的互动中学习。」
他还担忧这种学习方式可能导致「类似人类的认知偏见」。
Ryan Yang(@yangyc666)也提出了务实的观点:
「有趣的角度。系统提示作为”第三支柱”?在实践中,它们充当动态上下文层——引导行为而不改变参数。但如果没有迭代测试,就会很脆弱。我看到团队过度关注这一点,而忽视了首先要注意数据管道卫生。关键是:将提示视为模块化组件,而非灵丹妙药。」
thomas(@thothwill)分享了一个令人印象深刻的亲身经历:
「昨晚我实际上也有了同样的认识,在粗略地手动做了一些事情后,看到了异常改进的结果。前后对比明显:从之前的”我无法执行xyz abc”到后来在一个非推理模型上一次就得到了正确答案,而且是在需要工具但没有直接相关工具的任务上。」
未来的LLM 学习方式
系统提示学习可能彻底改变LLM的学习方式。
随着AI模型变得更智能,我们可能不再需要那么多「技巧」来与它们沟通。
Cyrus(@cyrusnewday)认为这种学习可能有两条路径:
「1. 应用开发者通过”爬山”系统提示来更好地捕获开发者意图;2. 应用用户体验,传达期望规范。感觉像是在思维轨迹上进行”反思→学习”。」
eric(@Sports_in_Space)则强调了这种方法对商业应用的价值:
「当然,这种启发式学习对LLM的定制商业用途也会非常有帮助,比如’弄清楚什么提示能产生信息最密集的数据摘要’或’定制提示以提高LLM对用户各种上传内容的理解’。」
系统提示学习不仅是一种技术改进,更是对AI如何「思考」和「学习」的根本反思。
它可能让AI更接近人类的学习方式,不仅能记住知识和培养习惯,还能像人类一样从经验中「悟出」解决问题的通用策略。
如DΞSH所说:「它可以真正改变我们对学习本身的看法。」
随着该方向的发展,我们可能见证AI从「被训练」到真正「学习」的转变,变得更像一个会成长的伙伴,而不仅仅只是一个静态的工具。
(文:AGI Hunt)