

DEER团队 投稿
量子位 | 公众号 QbitAI
长思维链让大模型具备了推理能力,但如果过度思考,就有可能成为负担。
华为联合中科院信工所提出了一种新的模式,让大模型提前终止思考来避免这一问题。
利用这种方法,无需额外训练,就可以让大模型的精度和效率同时提升。

这种方式名为DEER,也就是动态提前退出推理(Dynamic Early Exit in Reasoning)的简称。
其核心在于找到推理信息质量下降之前的临界点,并在临界点及时让大模型中断推理。
结果在多个推理基准中,DEER在DeepSeek系列推理LLM上始终有效,将思维链生成长度平均减少31%到43%,同时将准确率提高1.7%到5.7%。
截至目前,DEER已在QwQ、Qwen3、Nemotron等更多推理模型和11个评测集上被验证持续有效。
停止推理的临界点,需要动态规划
直观上,随着思维链中的推理路径数量的增加,生成结论时可参考的信息也会更多。
如果能够识别出推理信息变得刚好足够的临界点(称为珍珠推理,Pearl Reasoning),并迫使模型在此点停止进一步思考并直接输出结论,就可以同时实现准确率和效率。
这项研究的关键,就是在生成长思维链过程中找到这样的珍珠。
为了验证这一动机,作者在每个推理路径的转换点强制模型从思考切换到直接生成答案。如果得到的答案是正确的,则验证了这种珍珠推理的存在。
如下图所示,大约75%的样本确实包含这样的珍珠(即提前退出依然可以生成正确答案),甚至有36.7%的样本只需不到一半的原始推理路径就能得到正确答案。

因此,如何从长思维链中找到Pearl Reasoning是实现高效推理的一个极具潜力和价值的课题。
为此,作者在先导实验中详细分析了推理模型存在的过度思考问题,并探索了静态早期退出对模型性能的影响,所有实验都是在DeepSeek-R1-Ditil-Qwen-14B上进行的。
作者首先让模型在测试集上执行完整的推理(包括前后think标签之间的思维链和结论),然后保留完整的思维链并根据思路转换点(如“wait”等词前后存在思路转换)将其划分为思维块。
对于这些样本,作者保留了不同比例(20%-90%)的思维块,并在每个截断处附加一个思维结束标记分隔符,以强制终止思维链过程并生成最终结论。
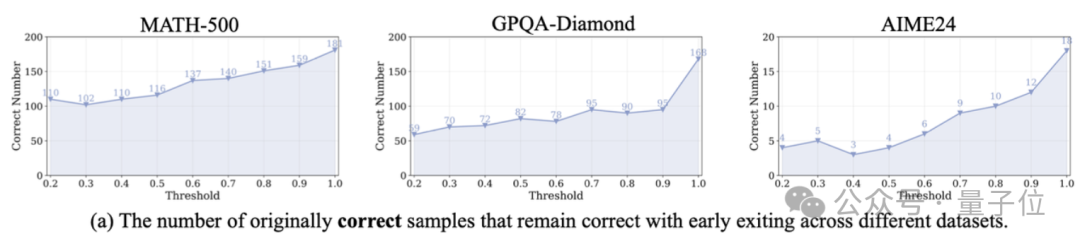
定量结果表明,在仅使用20%的推理步骤就提前退出的静态设定下,对于MATH-500,有60.8%的正确回答样本依然能保持正确;
对于较难的GPQA,仍然有35.1%样本可以保持正确。
下图说明了在不同的位置提前退出可以纠正的错误答案的不同比例。
对于MATH数据集,当以40%的推理步骤退出时达到最高的纠错率;而对于GPQA数据集,当以50%的推理步骤退出时达到最佳纠错率。
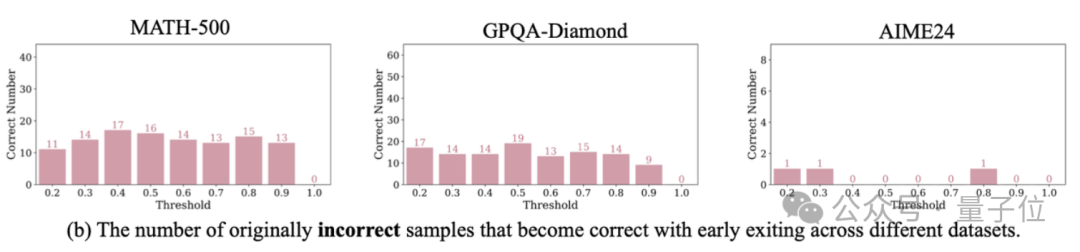
似乎每个问题的最佳早期退出点都不尽相同,并且与问题本身的固有难度密切相关。
因此,依赖基于固定启发式的静态提前退出策略是次优的,作者以此为动机设计了动态提前退出机制,通过寻找珍珠推理进一步纠错提高准确性,同时减少生成的长度。
那么,DEER具体是如何工作的呢?
三步判断退出推理时机
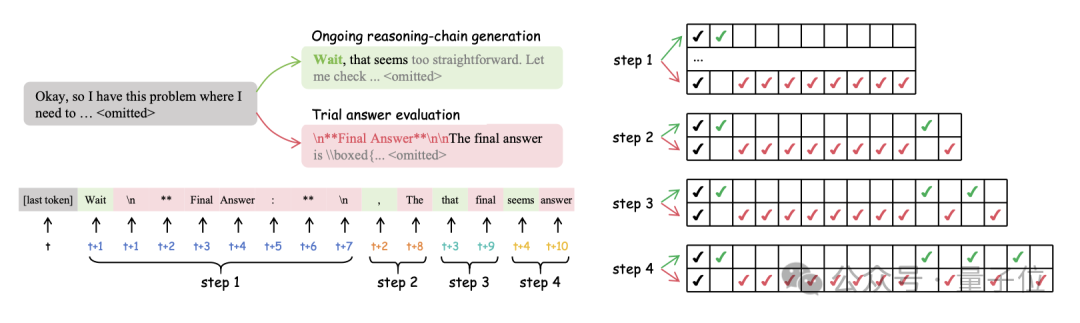
DEER将模型在推理中切换思维链的关键时刻视为提前退出的时机,并促使大模型在这些时刻停止思考并生成尝试性答案。
每个试验答案的置信度,是推理中提前退出的决策参考。
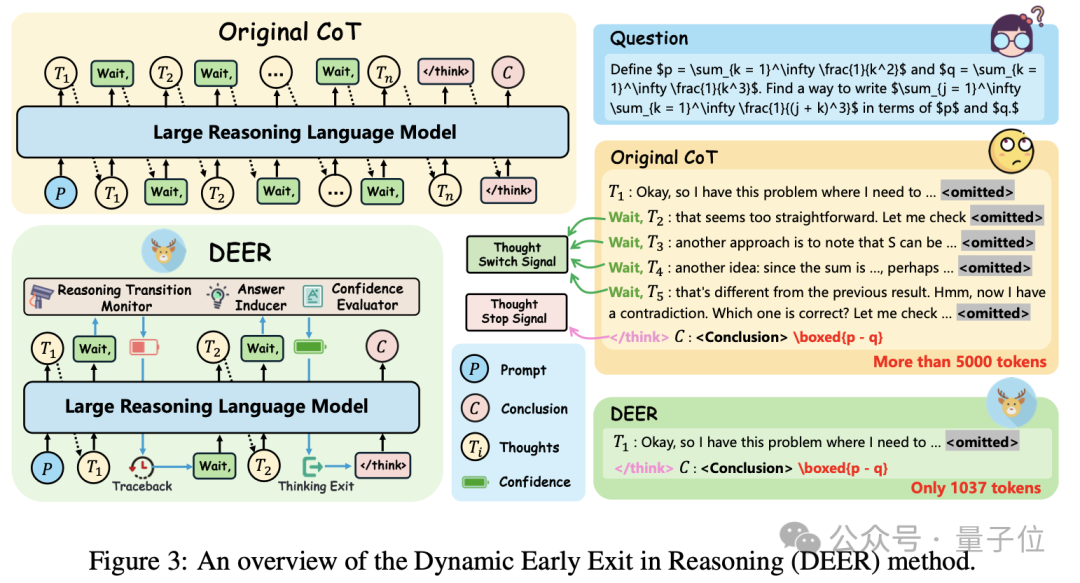
具体来说,DEER方法包含三个动作——推理转换监控(Reasoning Transition Monitor)、试验性答案诱导(Trial Answer Inducer)和置信度评价(Confidence Evaluation)。
推理转换监控是受budget force技术的启发,将诸如“wait”“alternatively”这样的单词识别为思路转换的临界点并监控其出现。
当思路转换点出现时,将触发答案诱导的动作——作者将“wait”替换为类似于“Final Answer:”的标记,以诱导模型立即生成验证性答案。
这将用于第三个动作,也就是置信度评价——
-
如果置信度足够高,则将模型设置为停止进一步思考,并基于已经生成的思维链直接生成结论; -
否则,撤销答案诱导的动作,沿原路径继续推理。
下图展示了DEER对验证性答案的置信度确实能够反映出已生成的思维链是否足够支撑大模型生成最终答案的信息量。
可以观察到,当模型的推理过程不完整或有缺陷时,试验答案往往表现出明显较低的置信度;相反,当推理全面且逻辑合理时,模型生成的答案具有更高的置信度。

直觉上,DEER中的答案诱导和置信度评价的计算在推理过程中引入了额外的延迟,特别是对于测试答案仍然很长的代码生成任务,这降低了通过缩短思维链序列而获得的效率增益。
为了解决这个问题,作者提出了分支并行加速(branch-parallel acceleration)策略,以进一步解决这些效率限制:
-
多个分支线性化为单个序列,并使用专门的Causal Attention Mask并行生成; -
通过基于置信度的剪枝实现动态KV缓存管理。该策略允许Trail Answer Inducer和Confidence Evaluation和正在进行的推理链生成之间的时间重叠,从而优化整体推理效率。
另外,关于端到端时延的更多讨论将在即将发布的版本中加入。
让推理模型更快更强
为了验证DEER的表现,作者在6个挑战性的推理benchmark上进行了测评,其中包含3个数学推理任务(MATH-500、AMC 2023、AIME 2024)、一个科学推理任务(GPQA Diamond)、两个代码生成任务(HumanEval、BigCodeBench)。
评测指标选用了准确率和生成长度两个维度,分别衡量精度和效率。实验选用了不同规模的DeepSeek-R1-Distill-Qwen系列模型(1.5B, 7B, 14B, 32B)。
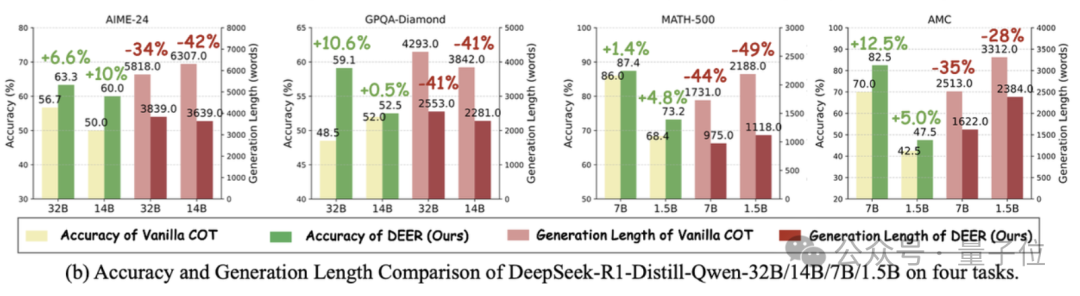
实验结果表明,DEER在所有规模的模型和评测集上都展现出了惊人的效果。
数值上,DEER相比于常规的Long CoT方法准确率平均提升了1.7到5.7个点,同时生成长度缩短了31%到43%。
在小规模的模型上,DEER对于MATH-500和AMC 2023两个难度稍低的benchmark提升更显著。
在大规模的模型上,DEER对于AIME 2024和GPQA两个更具挑战性的benchmark提升更显著。
尤其是当模型的推理能力与问题难度匹配时,作者的方法更加有效。

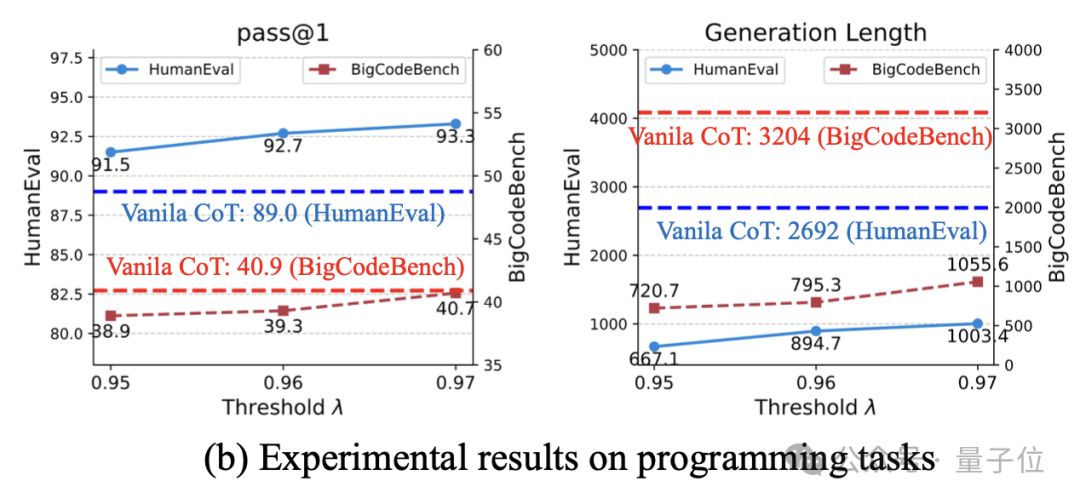
在HumanEval和BigCodeBench两个programming测试集上,作者的方法实现了平均减少64.9%的生成长度,而pass@1提高了2.1个点,并对0.95附近的阈值表现鲁棒,不会有显著波动。
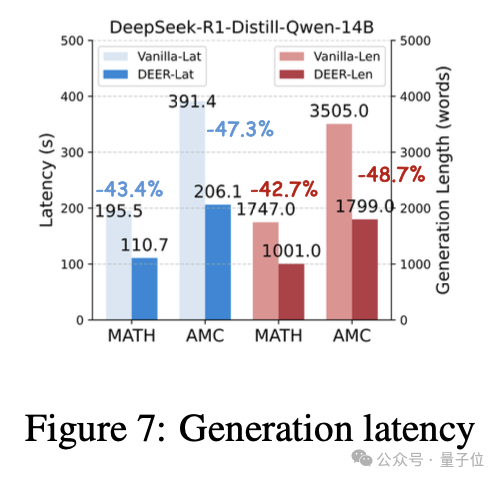
为了进一步验证DEER对于端到端推理效率的提升,作者基于huggingface transformers在MATH和AMC两个数据集上测试了平均每个样本的推理时延。
结果表明,在未使用作者提出的分支并行解码加速的情况下,DEER就已经减少了43.4%到47.3%的推理时延。
而采用了分支并行解码后,推理时延的下降比例和序列长度的下降比例呈现超线性的关系。
作者还通过样例分析进一步证明了DEER的有效性。
原始的推理模型在解决问题时倾向于切换思路探索多种解题方法,然而很可能问题的最优解决路径只有一条,在后续的思路中模型会因为犯错而得不到正确答案。
为了验证两个不同结果哪一个正确,模型会进行无休止的自我检查,最终未能给出答案。
但在DEER的工作模式下,这一问题得到了有效避免。

论文地址:
https://arxiv.org/abs/2504.15895
项目链接:
https://github.com/iie-ycx/DEER
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!
— 完 —
学术投稿请于工作日发邮件到:
ai@qbitai.com
标题注明【投稿】,告诉我们:
你是谁,从哪来,投稿内容
附上论文/项目主页链接,以及联系方式哦
我们会(尽量)及时回复你

🌟 点亮星标 🌟
(文:量子位)