
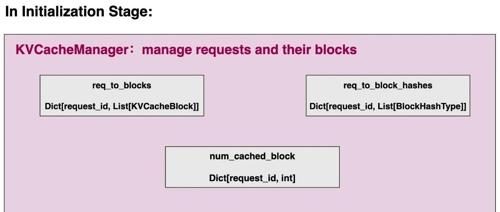
推理效率

微软开源新版Phi-4:推理效率暴涨10倍,笔记本可运行

专注AIGC领域的专业社区分享了微软开源的Phi-4家族新版本Phi-4-mini-flash-reasoning,该版本参数小且推理效率高,特别适用于边缘设备。文章还介绍了创新架构SambaY及其实现原理,并展示了其在长文本生成、高级数学推理和长上下文检索方面的性能提升。



一作解读!从idea视角,聊聊Qwen推出的新Scaling Law——Parallel Scaling

MLNLP社区介绍了一个名为ParScale的新方法来扩展大语言模型的计算量,该方法可以在保持参数不变的情况下显著提升推理效率,并且适用于各种场景。通过将输入变换形式和输出聚合规则变为可学习的并增大并行计算数量,该技术展示了在推理和预训练阶段的有效性。

推测性思维链SCoT:小模型“模仿”大模型,最高提速2.9倍,准确率几乎不降
论文提出SCoT(推测性思维链),通过小型模型快速生成多个解题草稿,大型模型审核并选择最优解或重新编写。这种协作式推理方法能显著提升速度和准确率,同时降低成本、增加灵活性,并且代码开源便于应用。
