
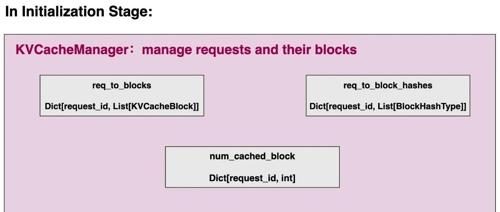
在上一篇关于vllm v1 scheduler的讲解中,我们讲述了调度器的工作流程,下图是vllm官方blog提供的一个简明流程示意图:
配合上篇文章的讲解,我们知道:
-
在vllm v0(版本是0.4)中,单次调度步骤里要么全是prefill阶段的请求,要么全是decode阶段的请求。
-
在vllm v1中,不再区分prefill和decode,而是从token的粒度对所有的请求一视同仁。具体来说,
token_budget(由参数--max-num-batched-tokens决定,用户可以自行配置)决定了单次调度步骤中最多可以处理的token数量。这样会使得: -
单次调度中可能混合着prefill和decode请求
-
对于prefill请求,受到token_budget的影响,它在某次被选中调度时可能传入的不是完整的prompt(例如上图中请求R3,它在step0这个调度阶段就只传递了2个token做prefill)
-
通过这种更通用的调度方式,可以同时满足chunked prefill、prefix caching和speculative decoding的场景。
我们再来回顾一下v1 scheduler中的running和waiting队列:
-
waiting队列中装有2种类型的请求:【新来的请求】和【从running队列中抢占的请求】。其中,对于后者,根据FCFS原则,一般会被加在waiting队列的最前端。这样当device上有充足block空间的时候,会优先调度这些之前被抢占的请求。
-
running队列中的请求类型可以粗糙理解成【即将被送去做推理,或者至少已经做过1次推理计算的请求】。在vllm v0中,running队列中的请求都处于decode阶段。而在vllm v1中,running队列里也可以有正在做prefill的请求。例如上图中的R3,它在step0这步调度后,就被从waiting加入了running。但是在step1中它还是会继续做decode。
在上篇文章中,我们对上述的这些过程都有更细致的描述和图例,建议大家在阅读本文前,先细看上篇文章。
在本文中,我们会展开讲解“当调度器从waiting/running中取出一个请求时,如何判断当前device上有充足的block空间留给这条请求做推理”,而这个问题会涉及到KVCacheManager和Prefix Caching,这两者就是本文的重点。
一、Prefix Caching
1.1 什么是Prefix Caching
假设block_size = 4。
先来一条请求req1, 它的prompt = ABCDEFGHI。
那么它需要3个blocks装载kv cache:
ABCD | EFGH | I
后来一条请求req2, 它的prompt = ABCDEFGHJ。
那么它需要3个blocks装载kv cache:
ABCD | EFGH | J
对于req2,它可以复用req1的前2个blocks,也就是ABCD | EFGH,以此达到节省kv cache显存的目的。
总结来说,prefix caching的目的就是从full blocks的角度找到最长一致前缀。我们针对这个定义做一些详细展开。
(1)问题1:什么叫从full blocks的角度找到最长一致前缀?
假设对于req1:
ABCD | EFGH
假设对于req2:
ABCD | EFG
那么从字符串的角度来看,req2和req1的最长一致前缀是ABCD | EFG。那这是否意味着req2可以直接复用req1的前2个blocks呢?答案是否定的。
我们假设req2直接复用了req1的前2个blocks做prefill,这时它产出了第一个token,假设其为J。显然J != H,所以此时我们要给req2分配一个新block,接着取消复用关系,最后再把EFGJ的kv cache装进新块中。这种频繁变更和分配新块的方式显然是低效的,且在block_size不大(默认为16)的情况下,其实计算余数的几个token的kv cache也不会花太多时间。所以性价比更高的方式,是从full blocks的角度去找到最长一致前缀。
(2)问题2:为什么可复用的一定是前缀,而不是中间某个相同的部分?
假设对于req1:
ABCD | EFGH
假设对于req2:
DCAB | EFGH
那么req2是否可以复用req1的EFGHblock呢(毕竟这些token的内容和相对位置都是完全一样的)?答案是否定的。
首先,一个block的槽位内,存储的是一个模型所有layers在某个位置上的kv cache,也就是要考虑到这个kv cache是多层的。
现在,假设我们来到模型的第2层,这一层中E位置的kv是怎么计算的呢:
-
第1层的E和前置tokens们做attn及其余操作后,得到第2层E位置的hidden_state -
第2层E位置的hidden_state再经过一系列计算得到kv值
所以对于req1和req2来说,第2层E位置的hidden_state是受到前置tokens的影响的,如果前置tokens不一致,则意味着第2层E位置的hidden_state不一致,进而不可复用kv值。对于后面的layers也是同理。这也是我们为什么要考虑前缀,而不是某一部分一致的原因。
1.2 block的hash值
我们已经知道了prefix caching的基本思想,现在我们要考虑对于一个请求,如何快速找到它可以复用的blocks。一个朴素的想法是:如果每个block都有一个唯一标识(hash值),同时我可以根据请求的本文内容计算出它需要的每个block的hash值,两者一对比,不就可以快速找到能复用的block了吗?我们来展开说明这一点。
在vllm v1中,一个block的hash值由3个要素决定:
-
parent_block_hash:父block的hash值 -
cur_block_token_ids:该block中维护的token_ids -
extra_keys:对于多模态或者lora等,会有一个额外的用于计算hash值的要素,后文会细说。
只有full blocks才有计算hash值的必要,这点非常重要,原因参见1.1
相关代码为:
# https://github.com/vllm-project/vllm/blob/refs/tags/v0.8.2/vllm/v1/core/kv_cache_utils.py#L407
# 一个block的hash被定义成一个python class:BlockHashType,其中维护着下面3个重要属性
BlockHashType(
# 这是真正的hash值
hash((parent_block_hash, curr_block_token_ids_tuple, extra_keys)),
# 这是该block中维护token_ids
curr_block_token_ids_tuple,
# 这是多模态、lora等场景会用到的,用于计算hash值的额外要素
extra_keys
)
我们先忽略extra_keys,然后举个例子看block hash如何计算:
-
假设block_size = 4, req1 = ABCDEFGHIJKLM -
那么req1需要4个blocks: ABCD | EFGH | IJKL | M -
block_hash0:hash(None, ABCD) -
block_hash1:hash(block_hash0, EFGH) -
block_hash2:hash(block_hash1, IJKL) -
block3没有满,不需要计算hash值
通过引入parent_block_hash,实现了1.1中我们考虑“前缀”的目的。
现在,我们再以多模态场景为例,看看extra_keys中装的是什么内容:
# 假设多模态请求如下:
{
"prompt": "描述这张图片:[IMG]",
"images": [{"data": base64_image, "type": "jpeg"}]
}
我们知道,多模态处理中,一般会把[IMG]转成若干个placeholder token id,这些placeholder在后续做prefill的时候才会被真正的image embedding所替换。在这种情况下,即使用户把上面请求中的[IMG]替换成不同的图片,最终这些请求的prompt token id也是完全一致的。这显然不是我们要的效果。所以,我们需要对图片本身也做hash,用于区分不同的图片。在多模态场景中,extra_key就装着这样的image_hash。更多的细节,请大家自行阅读代码。
二、KVCacheManager
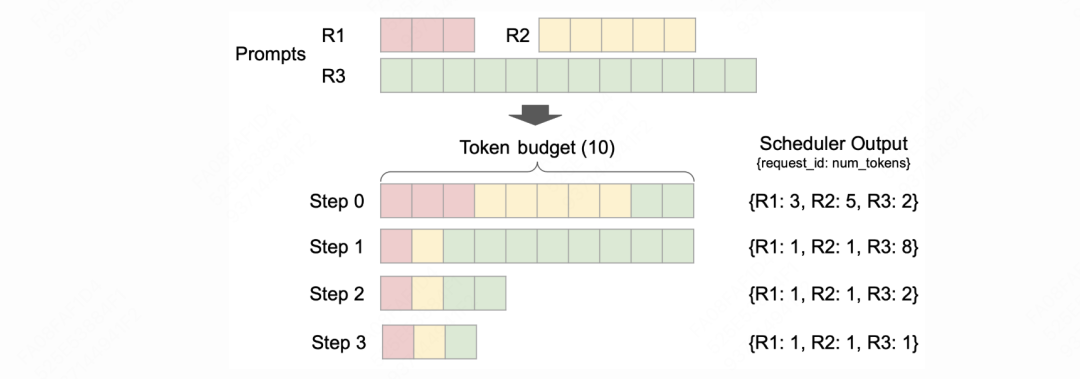
上图展示的是初始化阶段,也即没处理过任何请求时KVCacheManager的情况,我们来做展开讲解。
2.1 KVCacheBlock
图中每个绿色块即为一个KVCacheBlock实例,我们假设一块卡上的物理块一共有N个,那么这里就有N个KVCacheBlock实例。但是这些实例中没有真正存储kv cache值,我们在“kv cache初始化”一文中讲解过,ModelRunner下的self.kv_caches才是真正存储kv cache的地方,它的形式是List[torch.tensor],列表长度=模型layer数量,每个tensor的尺寸为[num_blocks, block_size, num_kv_heads, head_size]。所以,这些绿色的实例只是代表着物理块,而没有实际存储数据。不难理解,初始化时这些block的hash值都是None。
2.2 FreeKVCacheBlockQueue
一块卡上所有的空闲块都会被存放在free_block_queue中(FreeKVCacheBlockQueue实例),它的本质是一个双向链表,head和tail指针分别指向队列中第一个和最后一个block。如图所示,在初始化阶段,所有的blocks都没有被使用过,所以它们都在free_block_queue中。
(1)free block的定义
毫无疑问,空闲块一定满足ref_cnt=0,即没有任何请求正在使用它,但是这里又细分成2种类型:
-
没有存储任何kv cache值的、真正的空闲块 -
存储着kv cache值的、等待被驱逐的空闲块
第1种类型好理解,我们重点看第2种类型:当一个block的ref_cnt=0时,我们不着急把它当中的数据清理掉。因为没准后来的请求通过prefix caching可以命中这个block中的数据,进而直接复用它。所以我们会暂时把它append在队列的末尾。不过我们也不能无限期让它呆在队列中,如果一直没有请求命中它,且又到了不得不用它的时候,我们就会将其取出做清空,也就是我们说的驱逐(evicted)。
(2)为什么要使用双向链表
使用双向链表的好处是方便我们更高效使用LRU策略(Least Recently Use)来执行驱逐,结合(1)中的解释:
-
当一个请求结束推理时,我们要释放它的block资源 -
当相关block的ref_cnt=0时,我们把这些block append在free_block_queue的队尾 -
越靠近head的block,在时间上越早进入free_block_queue -
每次当我们需要分配新block时,我们就从链表的head处依次进行取块,使得整体遵从LRU策略 -
由于是双向链表,所有的增删操作都是O(1)级别的,更加高效。
最后,当我们在队尾执行append block这个操作时,我们需要按照逆序进行append,例如:
-
设block_size = 4,设请求 ABCD | EFGH | IJ已经做完了推理,此时这3个block被释放,且满足ref_cnt=0 -
我们将按照 block2 -> block1 -> block0的顺序(也就是IJ | EFGH | ABCD)把这3个blocks append在队尾 -
这样做的好处是:尽可能保留一个文本的前缀,以此让后来的请求有更大的概率命中prefix caching。
我们会在后文中,通过更具体的例子,帮助大家更好理解(1)(2)过程。
2.3 cached_block_hash_to_block
本质上是一个嵌套字典:
-
形式如 Dict[BlockHashType, Dict[block_id, KVCacheBlock] -
用于表示在这块卡上,某个hash值下对应的KVCacheBlock。BlockHashType的定义参见1.2。由于只有满块才会被计算hash值,所以这里的KVCacheBlock一定都是满块
从这个字典形式中,你可能会发现:同一个hash值下可能对应着多个KVCacheBlock。这也意味着对于2个请求,即使它们的前缀都是ABCD | EFGH,但依然可能无法复用彼此的KV Cache。我们会在后文的例子中更具体来看这个现象发生的原因,以及为什么要这么设计。
2.4 BlockPool
2.1 + 2.2 + 2.3 共同组成了BlockPool实例,也就是一张卡上的block池,它负责维护这张卡上所有的物理块。
2.5 KVCacheManager
KVCacheManager主要负责管理“请求和它们的blocks”,更具体来说它负责维护如下要素:
-
BlockPool:维护这张卡上所有的物理块,参见2.4 -
req_to_blocks:Dict[req_id: List[KVCacheBlock]],一个请求下所有的物理块 -
req_to_block_hashes:Dict[req_id, List[BlockHashType]],一个请求的所有物理块的hash值。由于只有满块才可以被计算hash值,因此相同请求下,可能存在 len(List[BlockHashType]) < len(List[KVCacheBlock])的情况 -
num_cached_block:Dict[req_id, int],一个请求下所有满块的数量。
三、block的分配与释放
3.1 整体思路
在vllm v0中,针对prefill和decode阶段的请求,有不同的block分配策略,详情可以参见这里。
在vllm v1中,正如本文开篇所说,虽然实际执行推理计算的时候还会区分prefill和decode,但是在调度的环节已经不再区分这两者了,取而代之的是在token_budget的约束下从token的粒度进行调度。这样做的好处之一就是可以使得prefill/decode阶段的请求共享一个通用的block分配策略。我们先来看这个通用策略。
对于一条请求,KVCacheManager.allocate_slots()函数将计算当前这张卡上是否有充足的block空间分配给这条请求,代码入口如下:
https://github.com/vllm-project/vllm/blob/refs/tags/v0.8.2/vllm/v1/core/kv_cache_manager.py#L141
在单次调度中,一条请求(不管是处在prefill还是decode阶段)一共需要的blocks排布如下:

我们不考虑< pre-allocated >,只考虑其余类型的blocks:
-
< computed >:本次调度前,就已经分配给该请求的blocks -
< new computed >:本次调度时,该请求在prefix caching下新命中的blocks。对于该请求来说,< computed >和< new computed >都是现成的blocks,前者已经是它的,后者它可以复用。所以这些blocks都不需要从free_block_queue队列中再去取。 -
< new >:本次调度时,需要给该请求新分配的blocks,这些blocks需要从free_block_queue队列中取。
这三者共同构成了这个请求当前一共所需要的blocks
在这三者中,所有的满块被称为< full >,未满的块被称为<new full>(这是因为未满的块一定是出现在新分配的块中,否则就没有为请求分配新块的必要了)。我们会对<new full>中的blocks执行一系列更新操作,例如计算hash值、更新一个请求下和满块相关的数据(参见2.5),更新BlockPool中和满块相关的数据(参见2.3)等。
我们来举些例子更好理解上面的过程。在下面的例子中我们都假设block_size = 4
(1) waiting队列中的请求
在waiting队列中的请求,不管是新请求,还是从抢占状态中恢复的请求,它们都不会有< computed >,因为它们从来没有被计算过(从running队列中被抢占的请求,在加入waiting队列前就清空了< computed >相关的blocks)。
假设从waiting队列中取出一条新请求req1,prompt = ABCDEFGHIJ
(1) 假设req1 prompt中全部的tokens都被此次调度选中,
那么req1总共需要的blocks为:ABCD | EFGH | IJ
(2) 假设ABCD | EFGH 这2块blocks命中了prefix caching,即可以复用已有的blocks
(3) 那么对于req1有:
<computed>: 0。waiting队列中所有的请求都是如此
<new computed>: 2, ABCD | EFGH
<new>: 1, IJ
<full>: 2, ABCD | EFGH
<new full>: 0
(4) 由于<new>代表着本次调度该请求需要新分配的块,所以我们只需要去free_block_queue中检测
是否有充足的块数进行分配即可,更多的细节这里不再详细展开,读者可以自己阅读代码。
(2) running队列中的请求
本文开篇提过,在vllm v1中,running队列中不再只存放处于decode阶段的请求。当调度粒度改成token后,running队列中依然可能出现已经进入但没有做完prefill阶段的请求(例如开篇图例中提到的R3)。对于decode阶段的请求,我们这里不再举例,留给读者自己分析。我们着重看后者。
假设从waiting队列中取出一条新请求req1,prompt = ABCDEFGHIJ
--------------------------- 第一次调度 ------------------------------------------
(1) 依然假设在调度req1前,该卡上已经存储了可以复用的blocks: ABCD | EFGH
(2) 对req1进行第一次调度,假设只有ABCDEF被选中调度。那么req1一共需要的blocks为 ABCD | EF
(3) ABCD命中了prefix caching,可以复用,针对EF需要分配一个新块
(4) 第一次调度结束后,waiting队列中的这条请求会被存放到running队列中
--------------------------- 第二次调度 ------------------------------------------
(1)对此时已经位于running队列中的req1进行调度,假设余下的tokens GHIJ 全部被选中
那么req1一共需要blocks为 ABCD | EFGH | IJ
(2) 毋庸质疑,第一个block肯定可以直接用,那么现在问题来了:
第二个block现在变成 EFGH,可以直接复用已有的吗?
答案是否定的。在vllm v0策略中,如果遇到这种情况,会释放该请求当前的EFGH块,同时复用已有的EFGH块。但在vllm v1中,分配块时采取的是append only的操作,也就是说,它只在这条请求第一次被调度的时候会考虑prefix caching,会做复用。而在之后的调度中即使真的命中了新块,也不会复用。这也是为什么在本文2.3中我们提到,对于BlockPool下维护的cached_block: Dict[BlockHashType, Dict[block_id, KVCacheBlock],相同hash值下可能会出现多个blocks的原因。你也可以理解成,进入running队列的请求就不会再有计算prefix caching这一步了,也就是它们的<new computed>都是0。我想这样做的原因,一来是用空间换时间,避免频繁分配新块产生的额外开销。而来一般在decoding阶段,output token的输出是不确定的,命中prefix caching的概率本就比较小,所以不需要为此再写更复杂的策略。我读的代码版本是0.8.2,但在0.8.4之前,我看v1还是采取这样的策略,再新的代码版本我就没有follow了,大家可以自行去阅读。
3.2 运作流程图例
在有了以上这些了解之后,我们现在来通过更具体的图例,把整个流程串起来。
在下面的流程图中:
-
橘色块:即2.5中的req_to_blocks,Dict[req_id: List[KVCacheBlock]],一个请求下所有的物理块 -
黄色块:即2.3中的cache_block_hash_to_block,形式如Dict[BlockHashType, Dict[block_id, KVCacheBlock],表示在这张卡上,某个hash值下的block -
蓝色块:即2.2中的free_queue_block,是一个双向链表,用于存储这张卡上空闲可用的blocks。 假设block_size = 4,blocks总数 = 10
(1)step0:请求req1 = ABCD | EFGH | IJKL | MNO,所有prompt tokens都被调度。
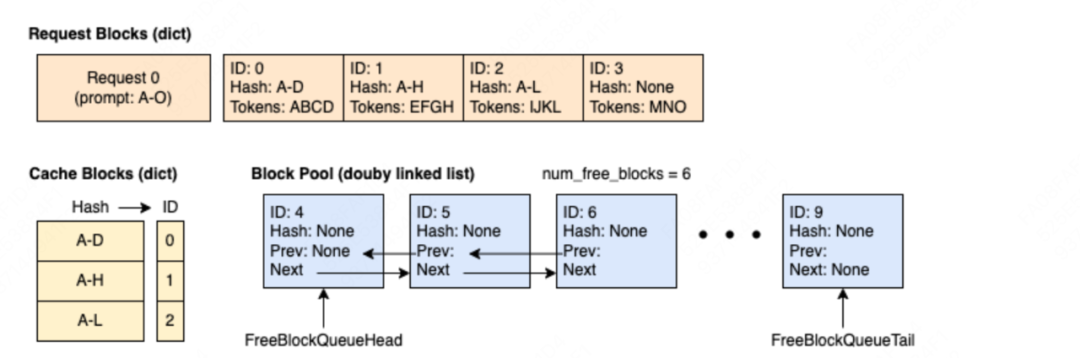
(2)step3:该请求经过2次推理过程(1次prefill + 1次decode),达到下面这个状态
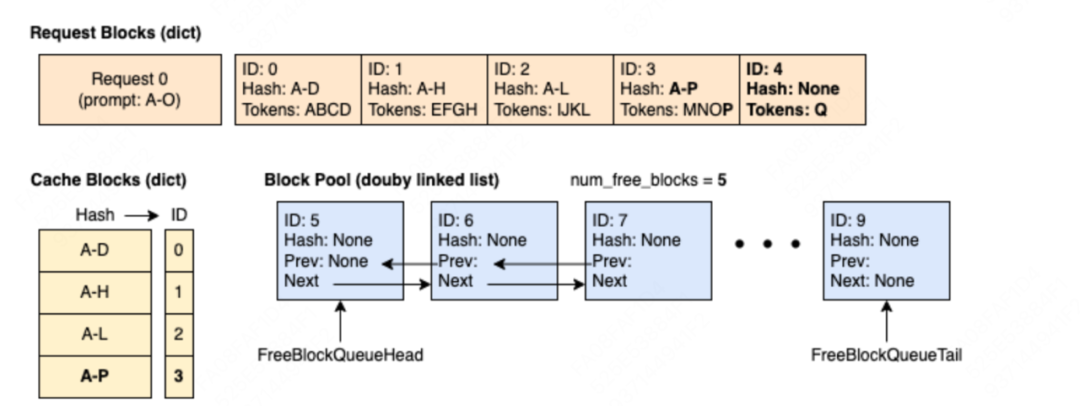
(3)step4:新来请求req1 = ABCD | EFGH | IJkl | mn,它的全部tokens被调度,但是它前2个blocks命中了req0的prefix caching
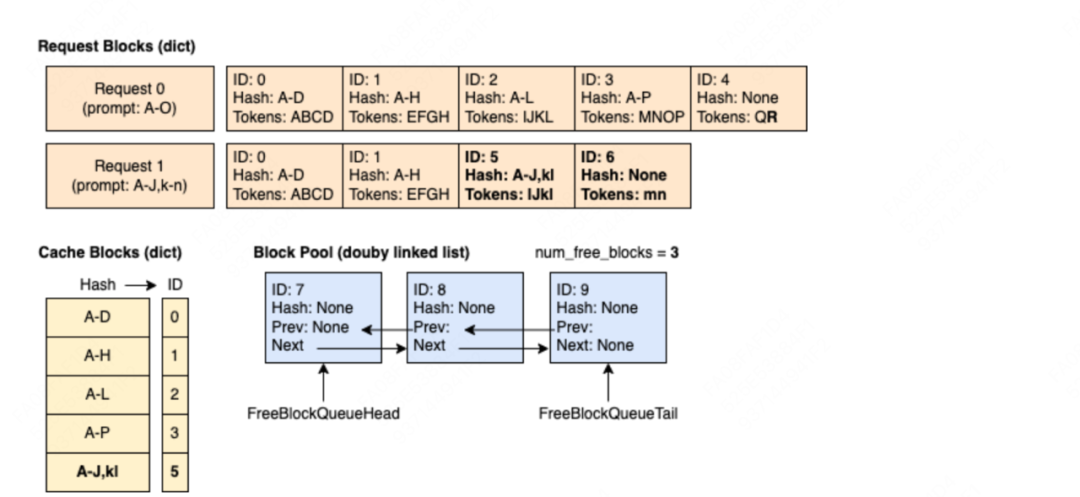
(5)step5:req0推理完毕,需要释放相关的block资源,block0和block1因为被req1引用,所以ref_cnt > 0,block2~4完全没有被任何请求引用,它们的ref_cnt=0,因此需要被放入free_block_queue中,注意这里的放入顺序是逆序的,目的是为了增加未来请求的prefix caching命中率(参见2.2(2)节)。

(6)step5: req1推理完毕,同样需要释放掉相关资源。(原图有误,用红笔做了修正)
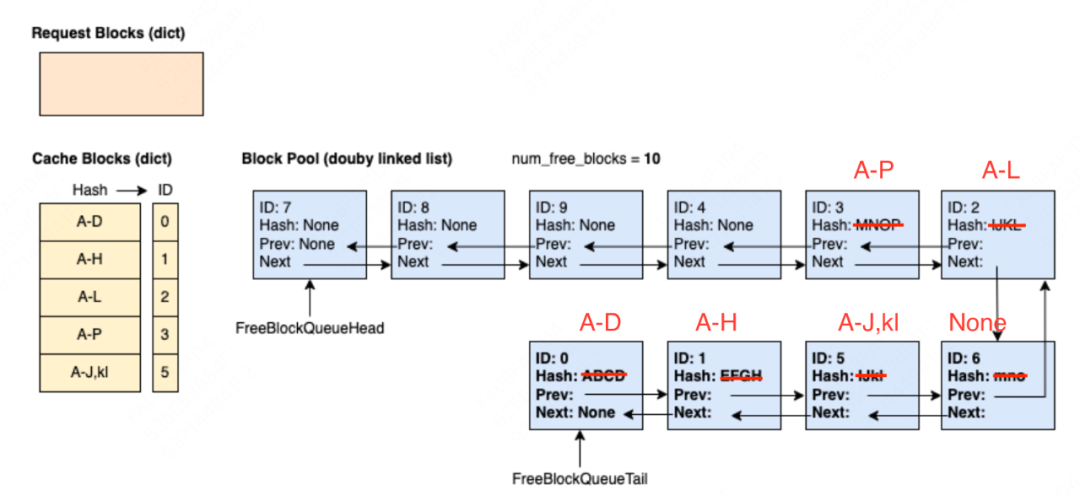
(7)step6:新来请求req2 = ABCD | EFGH | IJKL | 0-3 | 4-7 | 8-11 | 12-15 | 16,其中前3个block可以在free_block_queue中命中prefix caching(这个例子可以帮助我们更好体会不立刻驱逐block、以及逆序append block的好处),其余的block则以此从队列head处开始取。其中id=3的block被LRU策略正式驱逐,所以我们也要在黄色块中干掉它,疑似是blockpool上再也不维护它了。
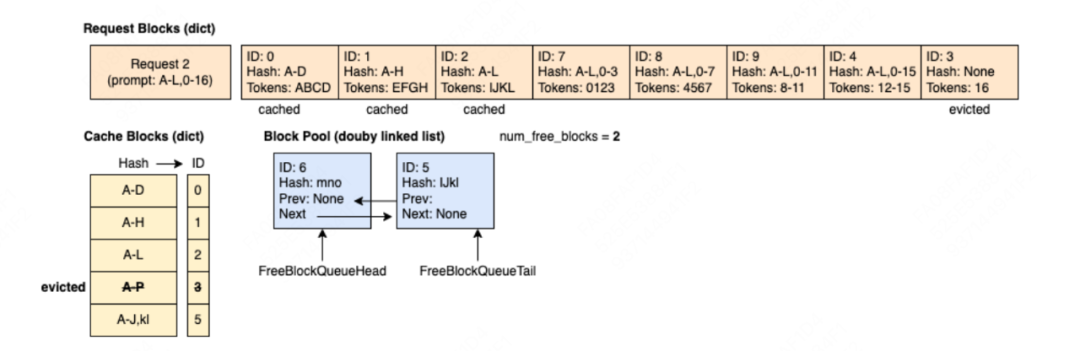
以上图例来自:https://docs.vllm.ai/en/stable/design/v1/prefix_caching.html
好,关于KVCacheManager和Prefix Caching的内容就介绍到这里。为了使得整个阅读过程更加清晰和不枯燥,本文尽量避开了所有直接解释代码的操作,尽量把代码转换成图例或者示例。更多的细节,留给读者去代码中探索吧!
(文:GiantPandaCV)