


近日上海 AI Lab 联合华南理工大学、香港科技大学(广州)、南京大学和香港中文大学发布了他们的一项研究成果:Liger(狮虎兽),即 Linearizing LLMs to gated recurrent structures,这是一个能够高效地将预训练大语言模型架构转换为带有门控循环结构的线性模型的线性化技术。
目前本研究工作已被 ICML 2025 接收,代码模型已全部开源。

论文标题:
Liger: Linearizing Large Language Models to Gated Recurrent Structures
论文链接:
https://arxiv.org/abs/2503.01496
代码链接:
https://github.com/OpenSparseLLMs/Linearization
模型链接:
https://huggingface.co/collections/linear-moe-hub/liger-67d904bffd7f9b77ade7747d
大语言模型(Llama、Mistral等)在各种序列建模任务上取得了很好的表现,特别是基于 Transformer 架构的大语言模型已经被广泛验证了其序列建模任务的有效性,然而这种架构也面临着它的固有缺陷:
1. 注意力机制关于序列长度二次方的计算复杂度,每次为了生成下一个词都需要回顾历史序列数据进行注意力计算,导致 Transformer 架构模型在长序列场景下效率低下;
2. KV-Cache 机制需要保存历史序列数据用于后续计算,导致显存压力随着序列长度增长而升高。
传统 Transformer 架构模型的效率瓶颈愈发凸显,如何在不牺牲性能的前提下实现高效推理,成为学术界与工业界共同关注的焦点。
在这一背景下,基于线性序列建模方法的模型架构崭露头角,因为线性循环模型在架构上具有明显优势:
1. 线性注意力机制关于序列长度的线性计算复杂度,每次生成下一个词仅需要访问固定大小的 memory/state,计算效率高;
2. 无需 KV-Cache,推理生成阶段的显存占用恒定,无论生成序列有多长,显存占用一直维持恒定不变。
得益于其高效性质能够完美解决 Transformer 架构的固有缺陷,线性循环架构模型展现出了作为 LLM 基础架构的优势。
然而验证一种新兴的模型架构的有效性并不容易,这是因为训练一个参数量非常大的模型动辄需要上千乃至上万亿的高质量数据量,并且算力需求极其高昂,需要在大规模显卡集群上对随机初始化的大模型进行从头预训练。
因此从头训练此类线性循环模型成本高昂,并且通常难以匹配现有 Transformer LLM 的性能,使得绝大多数研究人员望而却步,难以实际投入如此高成本训出一个效果可能并不怎样的线性 LLM。
现在既然我们已经有了预训练好的 Transformer 大模型(Llama、Mistral 等),将现有模型架构进行调整为线性循环模型架构并在此基础上进一步训练或许是成本更低的方案,我们称之为模型架构线性化。
然而现在的线性模型为了拟合 Transformer 架构的 Softmax Attention 效果,需要在原有线性注意力上增加各种模块,包括 Feature Mapping、门控机制等,能够一定程度上提升原有线性模型的表现。
然而现有线性化方法仍未探究如何更好地将 Transformer 线性化为门控循环结构的线性模型,并且在线性化场景下这些额外模块需要初始化进行训练,这增加了架构复杂性和差异性,额外增加了线性化成本。
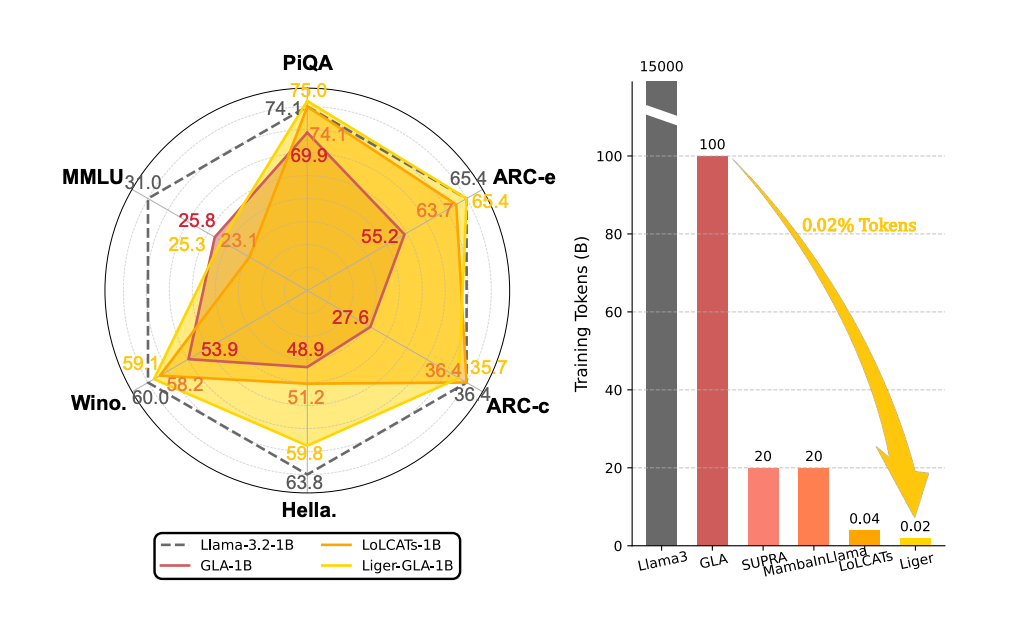
在此背景下,Liger 应运而生,这是一个极其高效、简洁且通用的线性化技术,仅需要极少量的微调成本即可将预训练的 Transformer LLM 线性化为门控循环结构,成功恢复原模型 93% 以上的性能,同时实现高效线性计算复杂度的序列建模。

方法描述
Liger 的核心目标是通过简洁且低成本的训练进行模型结构转换,将预训练 LLM 的权重直接迁移至门控循环架构中,避免从头预训练的高昂成本。

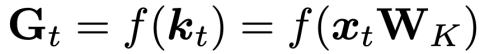
具体通过池化(Pooling)的无参操作,直接从键投影矩阵中提取门控信息,从而无需新增可训练参数。由于线性循环模型去除了 Softmax 操作,这可能导致 QK 的乘积未进行归一化数值膨胀而无法拟合原始输出的分布,因此线性循环模型通常需要引入可学习的 Feature Mapping 函数以拟合 Softmax Attention。
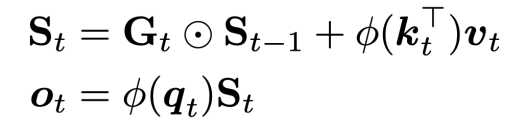
具体实现中,我们将 Feature Mapping 简化为 Softmax 函数分别作用在 Q 和 K 上,提供 QK 乘积数值归一化的稳定性,确保与原始 LLM 注意力机制的兼容,同时无需引入任何可训练参数,通过完全复用 LLM 权重减少了模型架构复杂度和差异性,而无需多阶段训练,从而进一步减少线性化成本并提高模型表现。
Liger 方法能够兼容各种带有门控机制的线性循环模型架构,十分灵活高效。

轻量微调:LoRA 助力线性结构适应
在进行模型结构转换后,Liger 采用低秩适应(LoRA)技术对模型进行微调以适应线性循环模型架构。
Liger 线性化仅仅是改变了注意力层 QKV 的运算顺序,通过右乘核技巧达到线性高效计算,因此仅需要采用 LoRA 对注意力层的 QKV 投影矩阵进行低秩分解训练,而无需对整个模型进行全参数微调,训练目标采用自回归的下一词元预测(Next Token Prediction),损失函数为交叉熵损失(Cross-Entropy Loss):
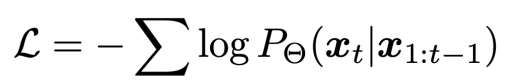
LoRA 轻量微调使得 Liger 线性化过程中能够充分保留 LLM 预训练知识,降低线性化成本并快速恢复大部分性能。
混合机制:Liger Attention
为了进一步提升线性化表现,本文提出了 Liger Attention 混合注意力机制,通过结合窗口注意力机制(Sliding Window Attention,SWA)与门控循环建模(Gated Recurrent Modeling,GRM)达成层内线性序列建模方法与注意力机制的混合,同时保留线性计算复杂度的高效性。
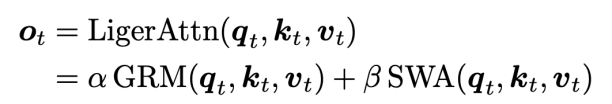
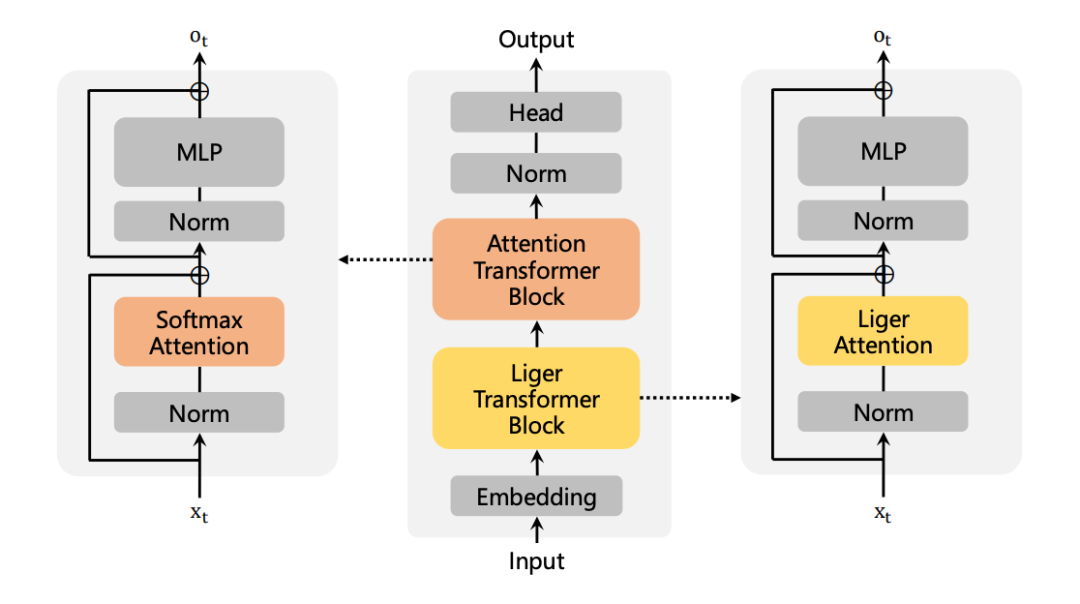
Liger 也能够用于层间混合架构的高效线性化,每 7 层门控循环模块后插入1层标准注意力模块,既能捕捉长程依赖,又通过局部注意力增强关键信息的处理,进一步提升了模型适应性。

实验分析
作者通过实验对比了 Liger 与现有的各种模型架构线性化方法,结果表明 Liger 在训练成本都小于其它方法的前提下,仅需要 20M 训练词元的成本就能够恢复预训练 Transfomrer 大模型 93% 以上的性能,在各种语言建模任务均接近或超过现有的 SOTA 线性化方法,非常接近 Llama、Mistral 等 Transformer 架构的 LLM 表现。

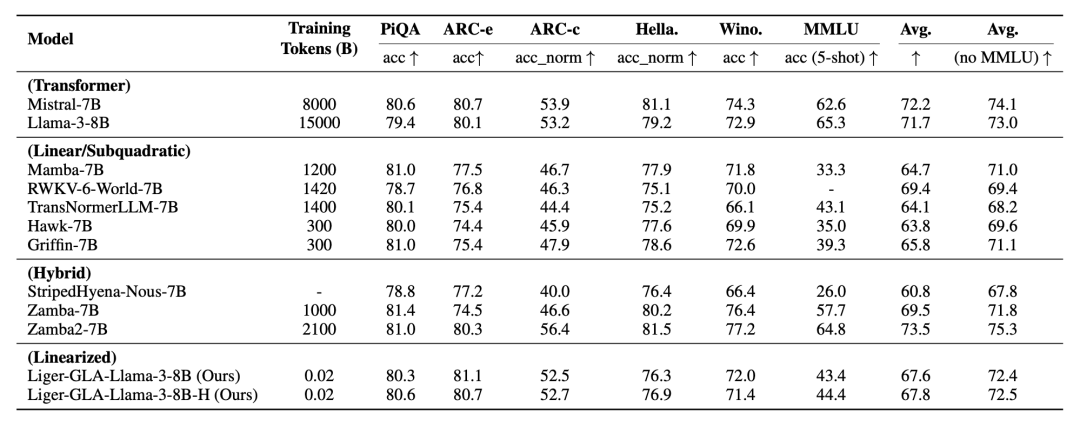
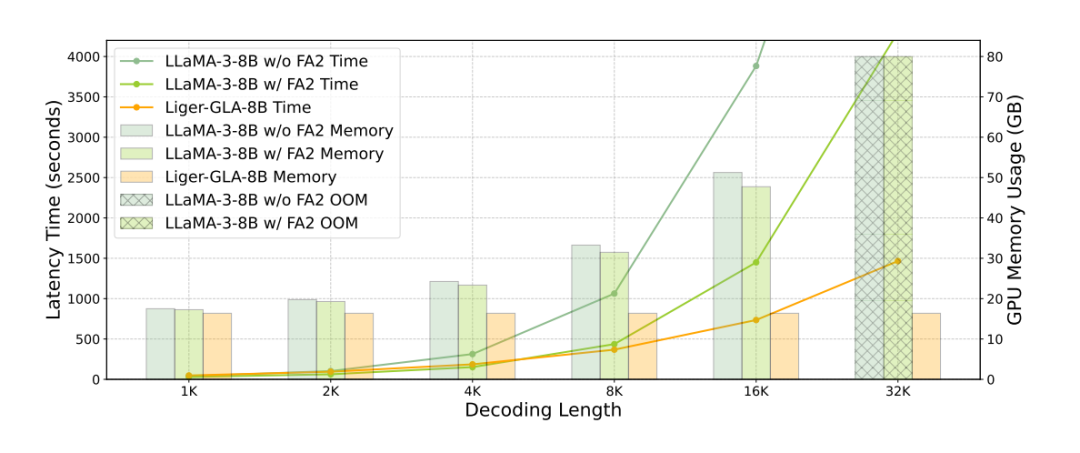
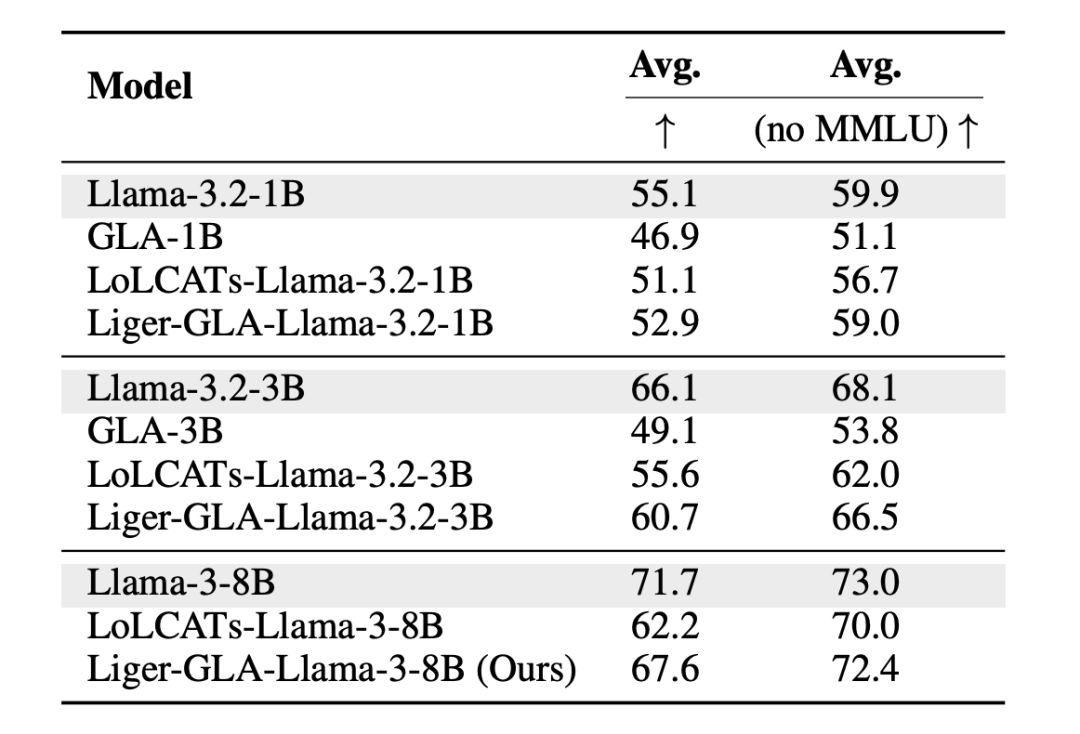

具体技术细节与更多结果分析请参考原论文。
总而言之,Liger 是一个极其高效、简洁且通用的线性化技术,仅需要极少量的微调成本即可将预训练的 Transformer-based LLM 线性化为门控循环结构。
不仅在序列建模任务上媲美甚至超越原有 Transformer-based 的大语言模型,同时能够享受线性模型架构的高效性,为更高效地部署具有线性时间推理和恒定内存占用的大规模 LLM 提供了一条有希望的途径。
(文:PaperWeekly)