

在大模型微调的实践中,如何构建和选择微调数据集,是决定微调效果最关键的因素之一。目前,社区已经积累了大量优秀的微调框架和开放数据集。在很多通用场景中,开发者只需按需组合不同的框架与数据集,就能完成基础微调。

但随着模型功能越来越复杂,如支持 Function Calling、具备推理能力甚至是混合推理能力(Reasoning + Tool Use),常规数据集的适配能力也逐渐变得捉襟见肘。
例如,若想围绕 Qwen模型强化其 Function Calling 能力,同时保持其复杂推理结构不被破坏,此时很多公开数据集就难以胜任。又如,当你希望模型聚焦某个特定领域的专业知识,或者精准调用一组特定 API 工具时,也必须构造自定义微调数据集。
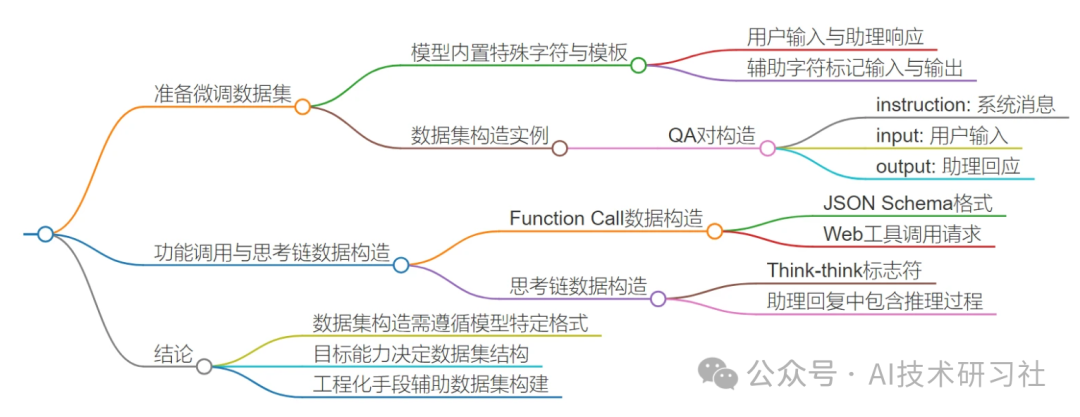
Qwen 系列模型使用 ChatML 格式,并通过控制 token 来实现对生成流程的细致控制。
其关键机制如下:
-
控制 token:在文本序列中插入的特殊符号,用于标记段落、文档边界、对话结构、工具调用等。例如:
-
<|endoftext|>:表示文档结束; -
<tool_call>和</tool_call>:包裹工具调用内容; -
<|im_start|>和<|im_end|>:用于定义对话轮次。 -
统一词表体系(Qwen2.5 起):
-
所有子模型(包括多模态模型)使用统一词汇表;
-
共计 22 个控制 token,词表总规模达 151,665。
-
对话模板结构:
Qwen 使用 ChatML 格式表示对话,格式如下:
<|im_start|>{{role}} {{content}}<|im_end|>-
user:用户输入角色; -
assistant:模型生成角色; -
system:元信息角色(如设定模型身份或风格),默认值为:
示例对话片段:

<|im_start|>system You are Qwen, created by Alibaba Cloud. You are a helpful assistant.<|im_end|><|im_start|>user hello<|im_end|><|im_start|>assistant Hello! How can I assist you today? ...<|im_end|>

通常,大家看到的对话微调数据格式如下,适用于结构化对话训练:
[{"instruction": "用户问题","input": "输入上下文,可为空","output": "期望模型输出"}]

适用于 ChatML 模型微调,精确控制每轮角色与内容:
<|im_start|>system You are Qwen...<|im_end|><|im_start|>user 请解释大语言模型<|im_end|><|im_start|>assistant 好的,我来用儿童的方式解释...<|im_end|><|endoftext|>
指令 + Function Calling 数据格式:
<|im_start|>user 查询今天上海天气<|im_end|><|im_start|>assistant <tool_call>{"name": "getWeather", "arguments": {"location": "Shanghai"}}</tool_call><|im_end|>
通用模型能力越强,对数据格式的要求越高。若希望打造具备复杂任务处理能力的模型,“数据工程”远比模型选择本身更重要。
建议开发者根据目标任务特性:
-
选择标准数据集进行预热训练;
-
然后使用小规模、高质量的自定义数据集进行精调;
-
特别是在 Function Calling 与多轮推理任务中,务必使用 ChatML 格式精准标注角色与意图。
更多信息参考下面的思维导图:

(文:AI技术研习社)