

在日常工作中,我们经常需要从各种文档中提取结构化信息,如发票、护照、合同等。然而,传统的OCR技术在处理复杂文档时常常面临准确率低、格式混乱等问题。
为了解决这些痛点,NanoNets 团队开发了一个开源的本地化工具:Docext,旨在解决传统OCR技术的局限性。
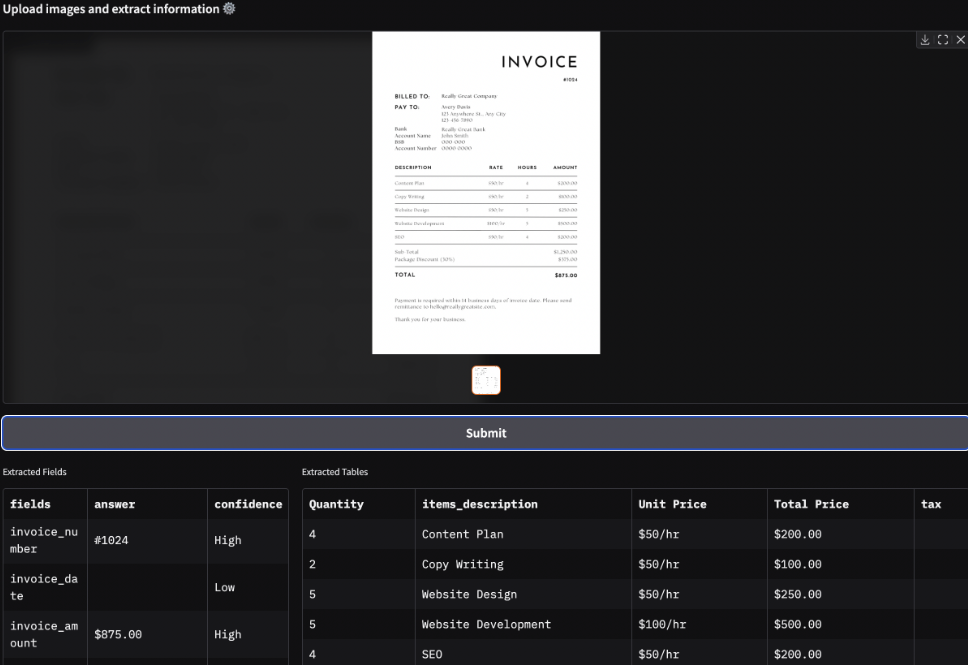
它利用视觉语言模型(VLM)实现无需 OCR 的结构化信息提取,支持发票、护照等敏感文档。它通过本地部署(Linux/MacOS)保障数据隐私,提供自定义字段、表格提取、支持多页文档和REST API集成。
最重要的是开源、免费、灵活性高,你可以在本地无需 OCR、精准提取文档中的字段和表格信息,全面提升处理效率和数据安全性!
主要功能
-
• 字段和表格提取:支持从文档中提取关键字段信息和表格数据,保持原始结构。 -
• 自定义和预建模板:可根据需要定义自定义字段,或使用内置的常见文档类型模板,如发票、护照等。 -
• 多页文档支持:能够处理多页文档,无需分页处理。 -
• 置信度评分支持:为所有提取的信息提供置信度评分,方便评估数据可靠性。 -
• REST API 支持:提供 RESTful API 接口,可轻松集成到你已有的系统或应用。 -
• 完全本地部署:支持在 Linux 和 macOS 系统上本地部署,确保数据安全和隐私。
快速使用
Docext 可直接作为 Python 的第三方库进行安装使用,使用 pip 命令即可快速安装。
如果你的本地Python环境都有的情况下,一条命令即可完成:
pip install docext下面是官方建议安装步骤与方式:
# 没有安装uv工具,需要先安装uv
curl -LsSf https://astral.sh/uv/install.sh | sh
# 创建虚拟环境并激活
uv venv --python=3.11
source .venv/bin/activate
# 安装docext
uv pip install docext
# 或者通过克隆项目进行安装
git clone https://github.com/nanonets/docext.git
cd docext
uv pip install -e .安装完成后,其实 docext 也包含了一个基于 Gradio 的网页界面,可用于轻松处理文档。
具体启动命令如下:
# 以默认配置启动Web界面
python -m docext.app.app
# 以自定义配置启动Web界面
python -m docext.app.app --model_name "hosted_vllm/Qwen/Qwen2.5-VL-7B-Instruct-AWQ" --max_img_size 1024界面可以通过访问 http://localhost:7860 使用。(用户名及密钥默认admin)
同时,docext 还提供了一个 REST API,用于程序化访问文档提取功能。
启动 API 服务器:
# 增加并发限制以并行处理更多请求,默认值为1
python -m docext.app.app --concurrency_limit 10使用API从文档中提取信息:
import pandas as pd
import concurrent.futures
from gradio_client import Client, handle_file
def dataframe_to_custom_dict(df: pd.DataFrame) -> dict:
return {
"headers": df.columns.tolist(),
"data": df.values.tolist(),
"metadata": None # Modify if metadata is needed
}
def dict_to_dataframe(d: dict) -> pd.DataFrame:
return pd.DataFrame(d["data"], columns=d["headers"])
def get_extracted_fields_and_tables(
client_url: str,
username: str,
password: str,
model_name: str,
fields_and_tables: dict,
file_inputs: list[dict]
):
client = Client(client_url, auth=(username, password))
result = client.predict(
file_inputs=file_inputs,
model_name=model_name,
fields_and_tables=fields_and_tables,
api_name="/extract_information"
)
fields_results, tables_results = result
fields_df = dict_to_dataframe(fields_results)
tables_df = dict_to_dataframe(tables_results)
return fields_df, tables_df
fields_and_tables = dataframe_to_custom_dict(pd.DataFrame([
{"name": "invoice_number", "type": "field", "description": "Invoice number"},
{"name": "item_description", "type": "table", "description": "Item/Product description"}
# add more fields and table columns as needed
]))
file_inputs = [
{
# "image": handle_file("https://your_image_url/invoice.jpg") # incase the image is hosted on the internet
"image": handle_file("assets/invoice_test.jpeg") # incase the image is hosted on the local machine
}
]
## send single request
### client url can be the local host or the public url like `https://6986bdd23daef6f7eb.gradio.live/`
fields_df, tables_df = get_extracted_fields_and_tables(
"http://localhost:7860", "admin", "admin", "hosted_vllm/Qwen/Qwen2.5-VL-7B-Instruct-AWQ", fields_and_tables, file_inputs
)
print("========Fields:=========")
print(fields_df)
print("========Tables:=========")
print(tables_df)
## send multiple requests in parallel
# Define a wrapper function for parallel execution
def run_request():
return get_extracted_fields_and_tables(
"http://localhost:7860", "admin", "admin", "hosted_vllm/Qwen/Qwen2.5-VL-7B-Instruct-AWQ", fields_and_tables, file_inputs
)
# Use ThreadPoolExecutor to send 10 requests in parallel
with concurrent.futures.ThreadPoolExecutor(max_workers=10) as executor:
future_results = [executor.submit(run_request) for _ in range(10)]
for future in concurrent.futures.as_completed(future_results):
fields_df, tables_df = future.result()
print("========Fields:=========")
print(fields_df)
print("========Tables:=========")
print(tables_df)详细使用文档请参考:https://pypi.org/project/docext/
适用场景
-
• 发票管理系统:批量提取发票编号、抬头、金额、开票时间等字段,替代 OCR -
• 护照/证件信息录入:提取姓名、证件号、国籍、有效期等敏感字段,全程本地处理更安全 -
• 工资条或报销单:表格字段结构化提取,输出 CSV / JSON -
• 企业表单解析:支持定制模板批量提取常见企业文件内容 -
• 隐私合规处理:完全本地部署,确保客户信息不出设备
写在最后
Docext 是一款基于视觉语言模型(VLM)的文档结构化信息提取工具。
与传统 OCR 工具不同,它不做字符识别,而是通过 “看懂文档”+“理解结构” 的方式,直接提取你关心的字段、表格、段落等内容,准确率更高、结构更稳定、部署更灵活。
而且目前许多OCR工具需要将文档上传到云端进行处理,这在处理敏感信息时可能带来数据隐私和安全性的问题。而其本地化部署的特性也为处理敏感信息提供了更高的安全性。
特别适合企业自动化和隐私敏感场景。
如果您正在寻找一款无需 OCR 即可从各类文档中提取结构化信息的本地化开源工具,Docext 是一个值得关注的项目。
GitHub 开源地址:https://github.com/NanoNets/docext

● 一款改变你视频下载体验的神器:MediaGo
● 字节把 Coze 核心开源了!可视化工作流引擎 FlowGram 上线,AI 赋能可视化流程!
● 英伟达开源语音识别模型!0.6B 参数登顶 ASR 榜单,1 秒转录 60 分钟音频!
● 开发者的文档收割机来了!这个开源工具让你一小时干完一周的活!
● PDF文档解剖术!OCR神器+1,这个开源工具把复杂排版秒变结构化数据!

(文:开源星探)