


近日,据外媒消息,WizardLM 团队核心成员 Can Xu 已经离开微软,加入了腾讯混元(Hunyuan)事业部。
Can Xu此前也在 X 发帖表示,“我和WizardLM 团队离开微软加入了腾讯混元(I and WizardLM team has left Microsoft and joined Tencent Hunyuan!)”。但此贴目前已被删除,Can Xu 解释称此前信息有误,是他个人离开了微软,而非整个团队。
据知情人士向 AI 前线独家透露,WizardLM 团队的主力成员大部分已经离开微软。
有趣的是,AI 前线留意到,Can Xu 宣布离开的时间点比较微妙,因为正值微软被曝出将在全球范围内裁员 3%,也就是大约 6000 多人会受到影响,外界猜测Can Xu的离开或与微软裁员有关。
但据知情人士透露,WizardLM 团队核心人物 Can Xu 和 Qingfeng Sun 早已离开微软,只是近日才将消息公布出来,他们的离开与微软裁员无关。
知情人士还透露,团队也会采用远程办公的方式协同工作,每个人独立负责各自部分的研发。
WizardLM 团队成立于 2023 年年初,专注于高级大语言模型的开发。
在 HuggingFace 上显示,WizardLM 团队目前共有 6 位主要成员,包括 Qingfeng Sun、Can Xu、Ziyang Luo 等。
Qingfeng Sun 曾任微软人工智能研究科学家,2020 年毕业于北京大学,获硕士学位。他与 Can Xu 等人共同创立了 WizardLM 项目,该项目贡献了先进的 LLM WizardLM、WizardCoder 和 WizardMath,他还创建了被广泛采用的方法 Evol-Instruct、RLEIF 和 Arena-Learning。
Can Xu 曾任微软人工智能高级研究科学家,为微软小冰、必应、WizardLM 和 Phi-3 等项目贡献了核心技术。他毕业于四川大学计算机专业,获学士学位;后又在北京大学计算机技术专业毕业获硕士学位(导师:俞劲松)。他的研究兴趣包括大型语言模型、对话系统和信息检索。
Can Xu 领导了 WizardLM 系列模型的研发:WizardLM 1&2、WizardCoder、WizardMath,在 NeurIPS、ACL、ICLR、EMNLP、AAAI 等顶级国际会议上发表论文 40 多篇,在 Google Scholar 上被引用超过 3300 次。
2023 年 4 月,北京大学与微软 WizardLM 研究团队与合作,提出了 Evol-Instruct,这是一种利用大语言模型生成大量不同复杂程度指令数据的新颖方法。在人工评估中,该团队最终生成的 WizardLM 模型生成的指令被评为优于人工创建的指令数据集。
那当时参与这个项目的还有谁?还有姜大昕等人。
尤其值得一提的是姜大昕,他于 2007 年加入微软亚洲研究院任首席研究员,后来又曾任微软全球副总裁、微软亚洲互联网工程研究院(STCA)副院长和首席科学家。2023 年,他在上海创立了阶跃星辰智能科技有限公司,任法定代表人、CEO。

基于 Evol-Instruct,2023 年 5 月 26 日,微软和北京大学的研究团队发布了 WizardLM 大语言模型,这个大语言模型能够根据复杂指令生成文本。它使用了一个名为 Evol-Instruct 的算法来生成和改写指令数据,从而提高了指令的复杂度和多样性。当时 WizardLM 共有三个版本:7B、13B 和 30B。
WizardLM 的核心算法是指一种称为 Evol-Instruct 的指令进化论。与手动创建、收集、筛选高质量指令数据的巨大耗费不同,Evol-Instruct 是一种使用大语言模型而非人类创建大量不同复杂度级别的指令数据的高效途径。
Evol-Instruct 的指令进化论 Evol-Instruct 算法从一个简单的初始指令开始, 然后随机选择深度进化或广度进化,前者将简单指令升级为更复杂的指令,而后者则在相关话题下创建新指令(以增加多样性)。以上两种进化操作是通过若干特定的 Prompt 提示大语言模型来实现。
研究人员采用指令过滤器来筛选出失败的指令,这被称为淘汰进化。论文中,给出了 4 个重要的实验现象:
-
人类评估结果证明,由 Evol-Instruct 进化生成的机器指令质量整体优于人类指令(ShareGPT)。
-
高难度指令的处理能力:人类评估者认为此时 WizardLM 的响应比 ChatGPT 更受欢迎。
-
代码生成与补全能力:在 HumanEval 评估中,WizardLM-30B 同时击败了 code-cushman-001 与目前最强代码开源模型 StarCoder 。这证明了 Llama 系列预训练模型的代码能力并不差,在高效的对齐算法加持下,依然可以获得优异的表现。
-
WizardLM-13B 同时在 AlpacaEval 与 Evol-Instruct 测试集的 GPT-4 评估中,获得了高度一致的 ChatGPT 能力占比(前者为 87% ChatGPT,后者为 89% ChatGPT)。
当时 WizardLM-30B,在 Evol-Instruct 测试集上取得了 97.8% 的 ChatGPT 分数占比。

曾经 WizardLM 模型有多强呢?
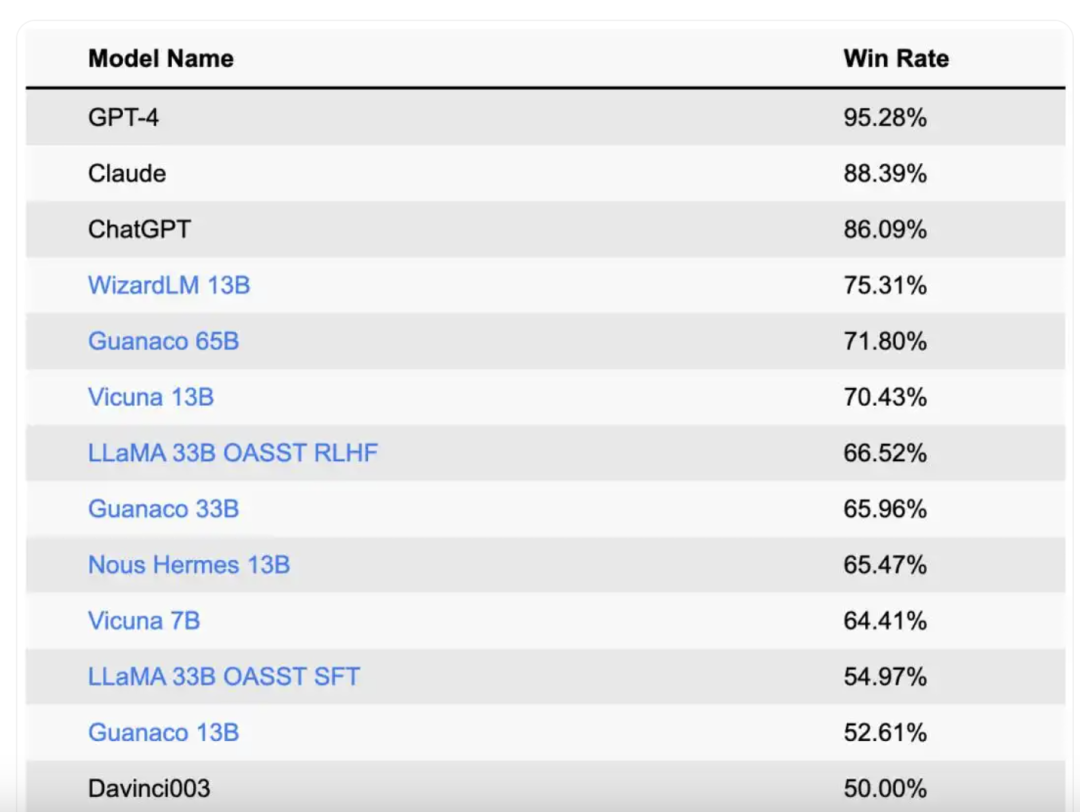
在 2023 年 UC 伯克利主导的「LLM 排位赛」中,WizardLM 甚至“杀入”全球大语言模型榜单的全球前四,前三位分别是 GPT-4、Claude 和 ChatGPT,WizardLM 也是华人团队开源模型第一名。
WizardLM 研究团队的主要目标是增强 AI 模型理解和生成类似人类文本的能力,从而改进聊天机器人、翻译服务和代码生成工具等应用。
2024 年 4 月,WizardLM-2 系列模型问世,旨在在性能和效率方面与现有模型相媲美。 这些模型旨在处理复杂的任务,包括多语言翻译、推理和基于代理的交互。
WizardLM-2 系列包含多个型号,主要是:
-
WizardLM-2 8x22B:专为处理高度复杂任务而设计的先进模型,据团队称,这款模型具有与领先的专有模型相媲美的竞争性能。
-
WizardLM-2 70B:专注于顶级推理能力,更适合用于需要深入理解和分析的任务场景中
-
WizardLM-2 7B:旨在以更快的处理时间提供高性能,适用于速度至关重要的应用。
这些模型使用 MT-Bench 和人类偏好评估等基准进行评估,其性能接近最先进的专有模型。
值得一提的是,这三款模型同样都是开源的,WizardLM-2 8x22B 和 WizardLM-2 7B 遵循的许可证为 Apache2.0。WizardLM-2 70B 遵循的许可证为 Llama-2-Community。

尽管取得了成就,WizardLM 团队仍面临挑战,尤其是在模型部署方面。
微软在公开发布了 WizardLM-2 模型后一天,就撤回了该系列模型,微软称这些模型就因缺乏全面的“毒性测试”。“毒性测试”是确保 AI 输出不会产生有害或偏见内容的标准程序。
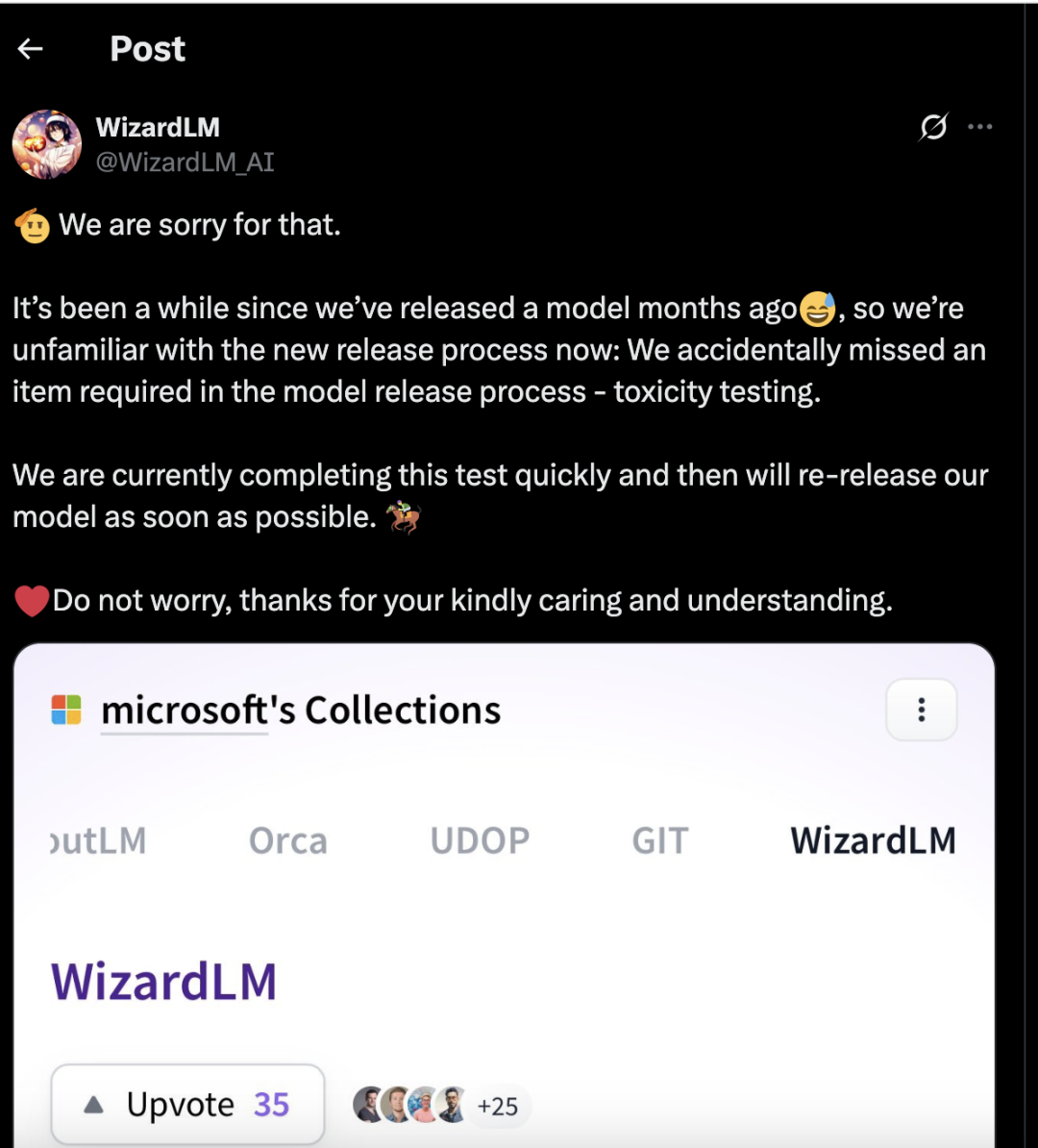
WizardLM 团队随后在 X 上的一篇帖子中写道,“我们不小心遗漏了模型发布流程中的一项必要环节——毒性测试。目前我们正在快速完成这项测试,并将尽快重新发布我们的模型。”
可此番删除来得有点晚,已经有用户迅速重新上传了原版 WizardLM-2 模型以及经过微调的定制化版本。
与此同时,Hugging Face 公司 CEO Clément Delangue 则发表一篇文章表示,微软此举不仅彻底移除了其他 WizardLM 模型,还破坏了多个开源项目,损害到 Hugging Face 社区的利益。

Delangue 当时写道,“WizardLM 模型的月均下载量超过十万次。我们对由此带来的不便深表歉意,且正在努力与作者团队及微软取得联系,以期为社区成员找到好的解决办法。”
上个月,腾讯宣布对混元 AI 模型的研发架构进行重大重组,聚焦“算力、算法、数据”三大核心要素,并计划进一步加大该领域的研发投入。此次调整旨在优化人工智能技术的研发效率,强化大模型领域的竞争力。
作为重组的关键举措,腾讯新成立两大技术部门:大型语言模型团队和多模态模型团队。前者专注于自然语言处理技术的突破,推动对话、文本生成等 AI 能力的提升;后者则致力于整合文本、图像、视频等多种数据类型,打造更智能的跨模态 AI 系统。
同时,腾讯加强了底层数据基础设施的建设,专门设立大模型数据管理部门,以优化数据采集、清洗和标注流程,为大模型训练提供高质量数据支持。
此外,公司还成立了机器学习平台部门,目标是为 AI 模型的训练、部署和运营提供一体化平台,提升研发效率并降低技术落地门槛。
腾讯在 AI 领域的野心已经非常明显。
腾讯在 AI 领域正加大投资,计划今年投入 900 亿元人民币(约合 124.9 亿美元)用于资本支出,其中大部分将用于推动其 AI 业务的发展。腾讯声称 AI 为其 2025 年第一季度 8% 的增长做出了贡献。
据知情人士称,目前 WizardLM 项目在微软内部已经“不存在了。”
网上有人肯定了 WizardLM 团队取得的成就,认为小型 WizardLM 7B 是最好的模型之一。
“WizardLM 7B 是我最早尝试的型号之一,可能是 GGML 时代的第一个。它永远在我心中占据着特殊的位置,我希望他们能在新公司的庇护下继续开发它。”
特别提示:这里的 GGML 指的是一个用于在本地设备(如 CPU 或低功耗硬件)上高效运行大型语言模型的量化文件格式和推理框架。
在 Reddit 上,有用户认为这对于微软来说是一大损失:
“我记得他们发布的某个版本没有经过某种安全测试,微软在经历了 AI 失败之后,他们非常重视这个问题。即使是这样,我认为微软失去一支可能在未来大放异彩的团队是很可惜的。”
(文:AI前线)