出品丨AI 科技大本营(ID:rgznai100)
自从 GPT-3 横空出世,生成式 AI 彻底点燃了全球科技圈:
尽管 LLMs 如 GPT-4、Claude 等展现了惊人的能力,但闭源模型的闭源特性让研究者难以深入理解其运作机制,同时开源模型的开放程度有限:
-
绝大多数顶尖模型闭源,仅限 API 调用
-
商业化受限,API 费用高昂,且随时可能涨价
-
-
对于开源模型,往往只公开模型权重,而关键的训练代码、数据集和配置却被隐藏,这严重阻碍了学术研究和商业化应用
Moxin-7B:从预训练到强化学习,全面透明的 AI 革新
Moxin-7B 的诞生,正是为了解决这一问题! 它由来自东北大学、哈佛、康奈尔等机构的研究团队联合开发,完全遵循“开源科学”原则,公开了从数据清洗到强化学习的全流程细节,从预训练到 DeepSeek 同款强化学习,成为目前透明度最高的开源 LLM 之一。
-
Moxin-7B-Base 权重、预训练数据与代码
-
Moxin-7B-Instruct 权重、SFT 与 DPO 的训练数据与代码
-
Moxin-7B-Reasoning 权重、GRPO 的训练数据与代码
-
完整公开:包括预训练代码、超参数配置、数据处理脚本、SFT/RLHF 训练框架,权重等等。
-
预训练数据:基于高质量语料库 SlimPajama(627B tokens)和 DCLM-BASELINE,经过严格去重和过滤。
指令微调数据:使用 Tulu 3 和 Infinity Instruct,涵盖数学、代码、科学文献等多领域任务。
强化学习数据:采用 OpenThoughts 和 OpenR1-Math-220k,通过 DeepSeek R1 生成的高质量数学推理数据。
-
训练成本仅 16 万美元(对比:GPT-3 训练成本约 460 万美元)。
-
零样本任务:在 ARC-C(AI2推理挑战)上达到 58.64%,超越 LLaMA 3.1-8B(53.67%)和 Qwen2-7B(50.09%)。
数学推理:经过 RL 微调后,在 MATH-500 上准确率 68%,超越 70B 参数的Llama-3-Instruct 模型(64.6%)。
长上下文支持:通过滑动窗口注意力(SWA)和分组查询注意力(GQA),高效处理 32K 长文本。
-
模型架构:基于 Mistral-7B 改进,深度扩展至 36 层,采用预层归一化和混合精度训练,提升稳定性。
-
指令微调(SFT):使用 Tulu 3 框架,在 939K 指令数据上训练,增强多任务能力。
偏好优化(DPO):通过 LLM-as-a-judge 标注的偏好数据,让模型输出更符合人类价值观。
采用 GRPO 算法(类似 DeepSeek R1),仅用 7B 参数即可实现高效推理。
训练框架 DeepScaleR 和 AReal 均开源,支持社区复现。
1. 基础架构:在 Mistral-7B 上全面增强
-
36层 Transformer(比原版 Mistral-7B 的32层更深)
-
-
GQA(Grouped Query Attention)+ SWA(Sliding Window Attention),支持32K上下文处理,且推理速度更快、内存占用更低
-
混合精度训练(FP16)+ 激活检查点(Activation Checkpointing),显著减少训练显存开销
-
采用“滚动缓存机制”,在超长文本推理时,将注意力存储限制在固定窗口,既保持推理质量,又避免显存爆炸
-
文本数据:SlimPajama + DCLM-Baseline
基于 MinHash-LSH 技术做跨域去重,相似度阈值控制在 0.8 以内
清洗后仅保留约 627B Token(RedPajama 原版的 49% 大小),但信息密度更高
进一步近似去重,避免重复训练,移除 40% 以上重复或近重复代码片段
助力模型在编码理解、代码生成任务上有优异表现,提升推理能力
1.混合并行(Data Parallelism + Model Parallelism)
预训练结束后,Moxin 团队采用双路线后期优化:
基于Tülu 3和Infinity Instruct数据集,采用多源指令数据(如CoCoNot, OpenMathInstruct, Evol-CodeAlpaca等)
使用 DPO(Direct Preference Optimization)进一步对齐人类偏好
使用高质量链式推理数据(OpenThoughts、OpenR1-Math等)进行微调
引入 GRPO 强化学习,提升复杂推理/数学答题能力
采用开源训练框架 DeepScaleR,支持社区复现
结果:Moxin Reasoning 模型,在数学推理能力上表现卓越
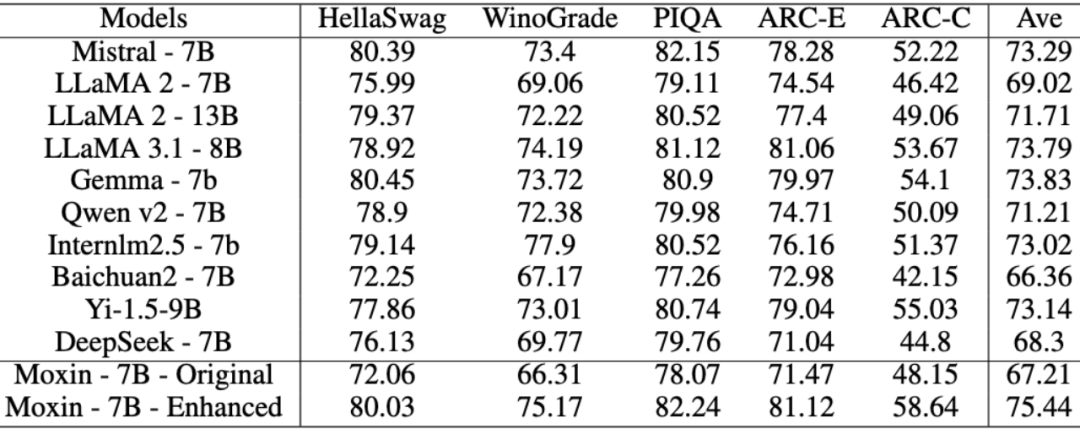
表中 Moxin-7B-Enhanced 即为 Moxin-7B-Base 模型,可以观察到,相比于其他 Base 模型如 Qwen2-7B、Llama3.1-8B 等,Moxin-7B-Base 表现出强劲性能。
表中 Moxin-7B-Enhanced 即为 Moxin-7B-Base 模型,可以观察到,相比于其他 Base 模型如 Qwen2-7B、Llama3.1-8B 等,Moxin-7B-Base 表现出强劲性能。
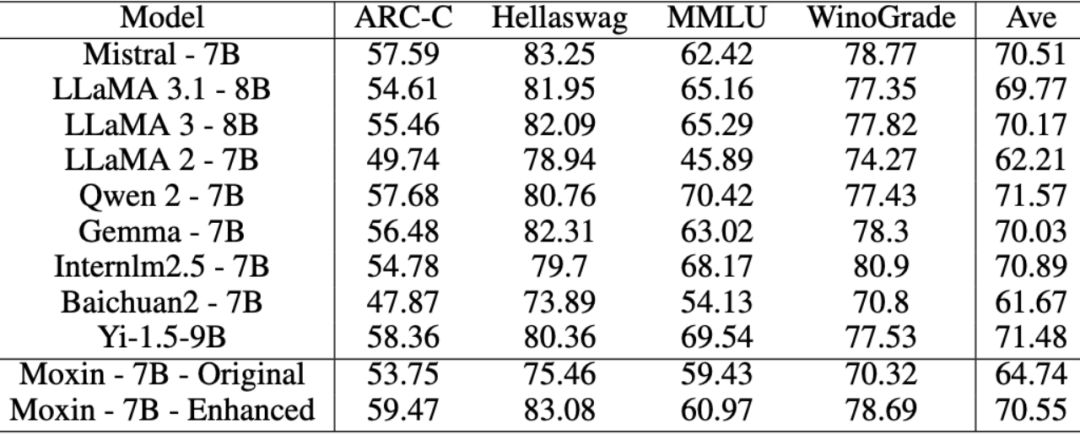
表中Moxin-7B-DPO即为Moxin-7B-Instrcut模型,可以观察到,相比于其他Instruct模型如Qwen2.5-7B-Instruct,Moxin-7B-Instruct表现亮眼。
相比于其他baselines如Qwen2.7-Math-7B-Base,Moxin-7B-Reasoning表现突出,体现出强化学习对7B规模的小模型也有效果。
Moxin-7B 证明了一点:高性能 LLM 不必是黑箱。它的全透明策略不仅降低了研究门槛,还为中小企业提供了可控的AI解决方案。Moxin-7B 的开源贡献:
-
Moxin-7B-Base 权重、预训练数据与代码
-
Moxin-7B-Instruct 权重、SFT 与 DPO 的训练数据与代码
-
Moxin-7B-Reasoning 权重、GRPO 的训练数据与代码
-
GitHub:github.com/moxin-org/Moxin-LLM
-
HuggingFace:huggingface.co/moxin-org
(文:AI科技大本营)