

西风 发自 凹非寺
量子位 | 公众号 QbitAI
刚刚,鹅厂把文生图卷出了新高度——
发布混元图像2.0模型(Hunyuan Image 2.0),首次实现毫秒级响应,边说边画,实时生成!

用户一边描述,它紧跟着绘制,整个过程那叫一个丝滑。不用等待,专治各种没有耐心。

有些画面描述起来太费劲?
别急,还有实时绘画板玩法。
用户可以手绘想要的元素,然后辅以文字说明,在另一半画板上它立刻就帮你按照草图绘制出来:

昨天腾讯混元团队发布了一小段预告视频,吊足了大伙儿的胃口。
今天终于正式发布了,真实使用效果到底如何?

量子位已抢先拿到测试资格,一起来看看到底怎么个事儿~
一手实测实时文生图
实测之前,先来看官方给出的一些小tips:
-
模型主打真实感、去AI味,真实场景生图效果会更好 -
模型是英文数据训练为主,有一些中文不能识别的概念,用英文输入会更好 -
优先推荐16:9生图,效果更佳
实时文生图
打开腾讯混元官网我们就直奔实时文生图,然后随便输入了一句话。
果真是一边打字生图直接跟着一起变换,顺畅~

而且当它把“小女孩”这一主体的模样定下来之后,我们再接着描述对画面做补充,它角色一致性保持得也不错。
各种风格都能驾驭:

虽然官方表示真实场景生图效果会更好,但我们尝试了一下动漫风、编织风等,效果也都不错:
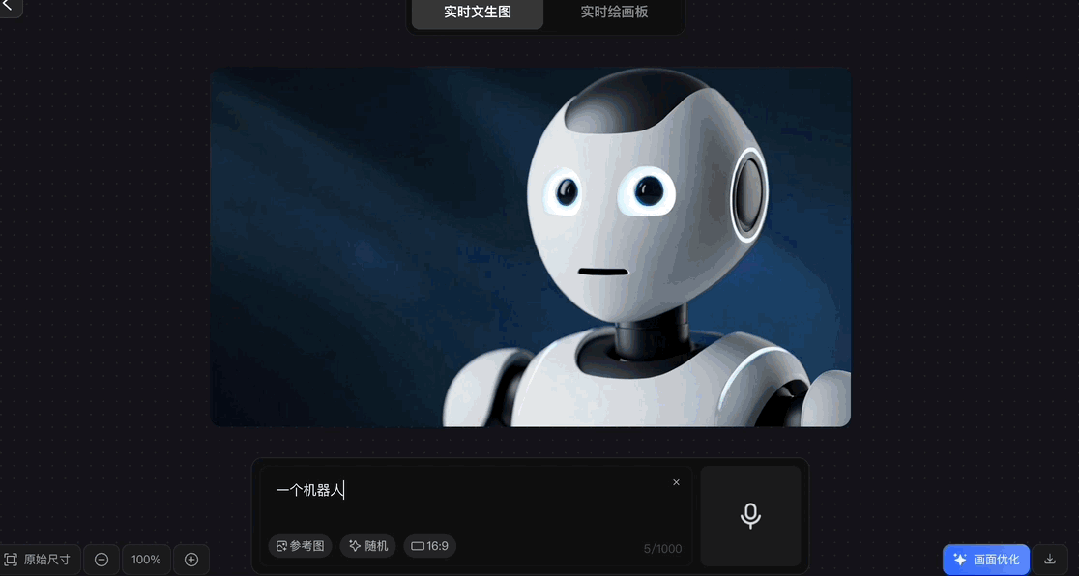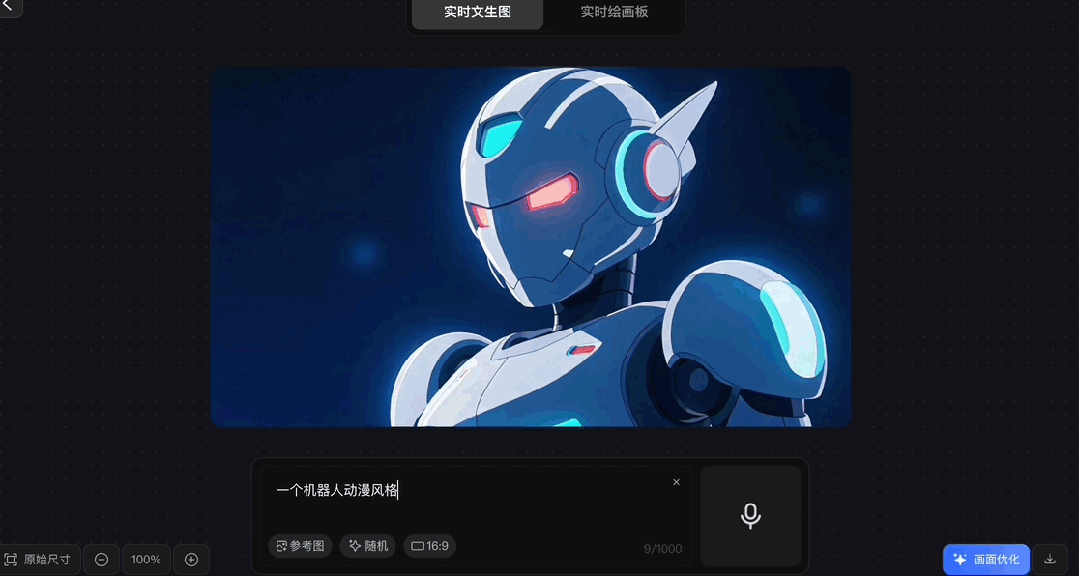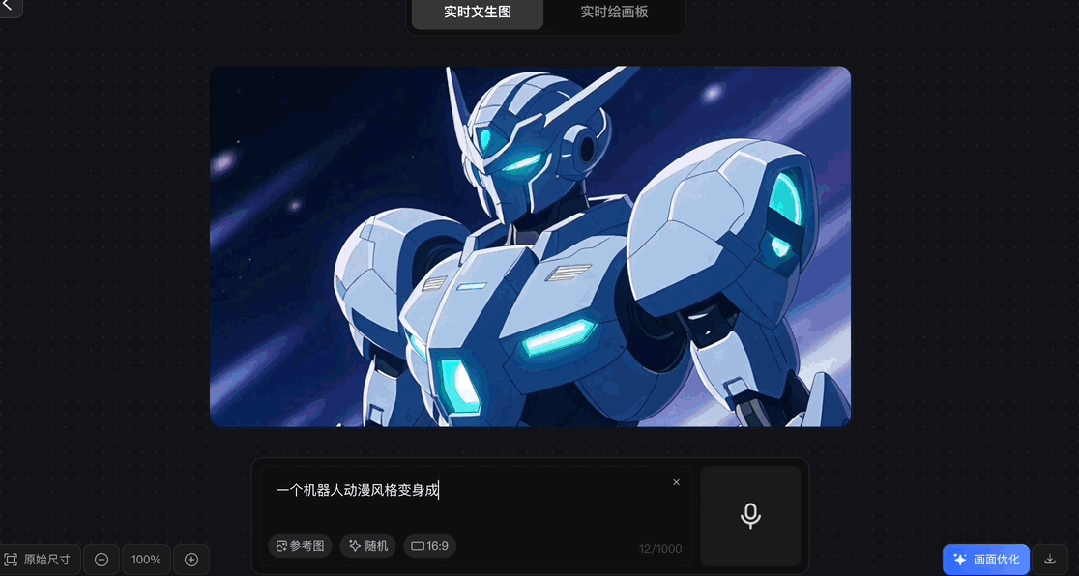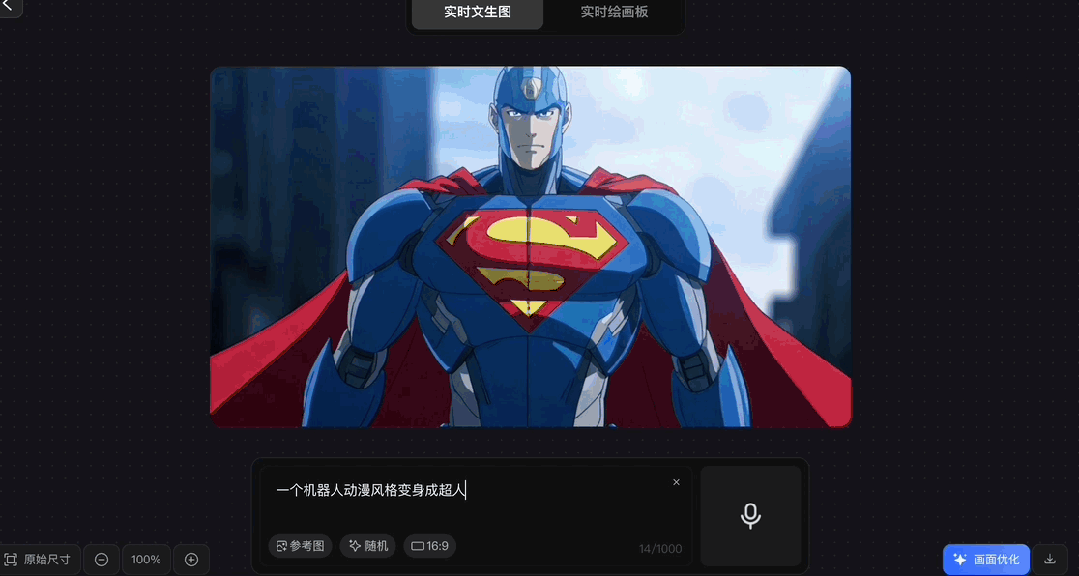
除了手打Prompt,解放双手实时语音输入也行,支持中英文,你一边说着它一边生成。
另外还支持上传参考图,可选择提取参考图的主体或轮廓特征,参考图片的约束强度也能调整:

设置好参考图后再输入指令,Hunyuan Image 2.0就会将参考特征和文本指令相结合生成图像。
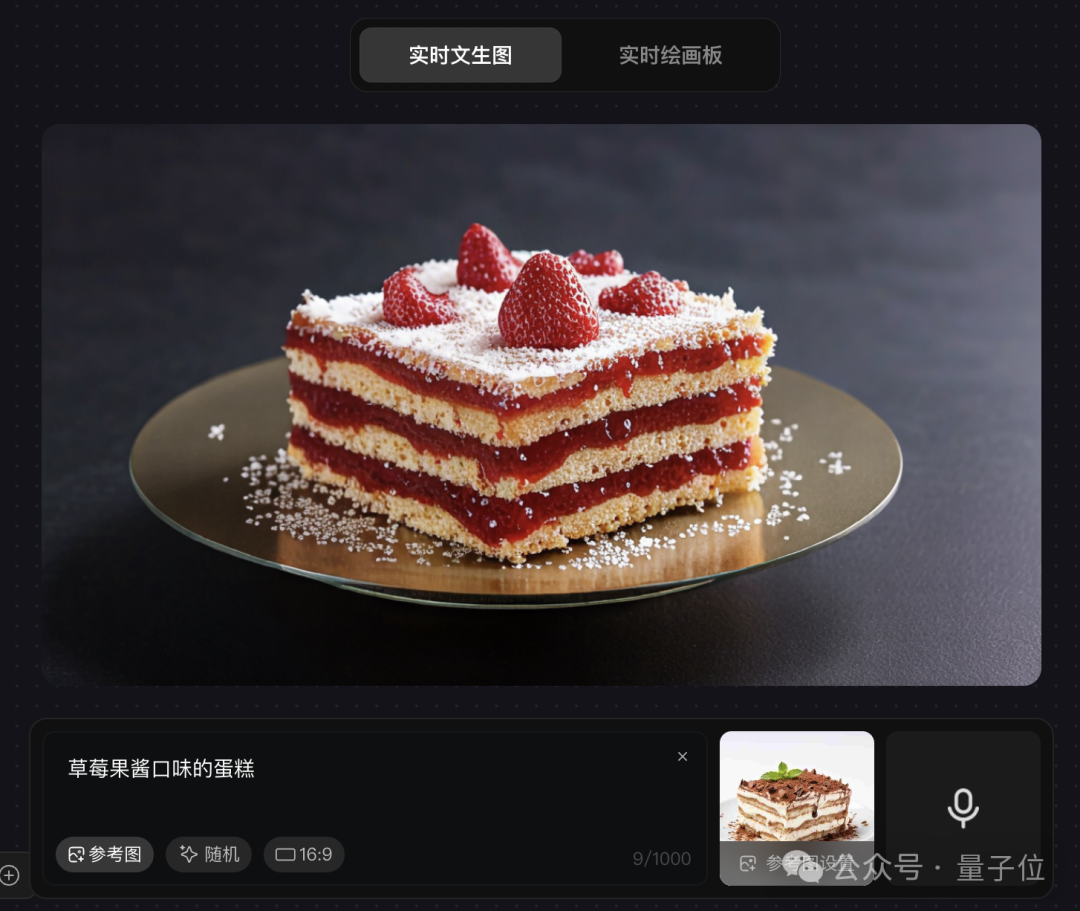
比如上传一块蛋糕的照片:

参考轮廓,秒秒钟就能把巧克力味改成草莓味的,形状和摆放都和参考图保持一致。
用法还有很多,再比如上传一张简笔画,然后一键上色:

如果最后绘图还是不满意,还能点击右下角“画面优化”,它可以帮你自动优化画面构图、景深层次、光影效果。

实时绘画板
实时绘画板玩法感觉更适合有一定设计能力的童鞋。
像咱这种手残党画风be like:

拿出小时候我爸教我的画鹤本领:
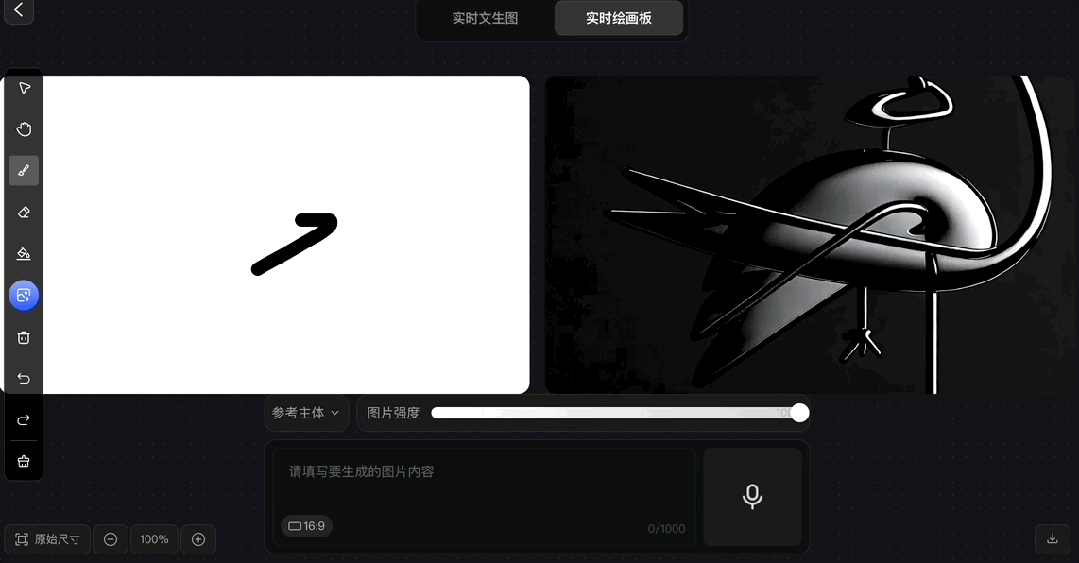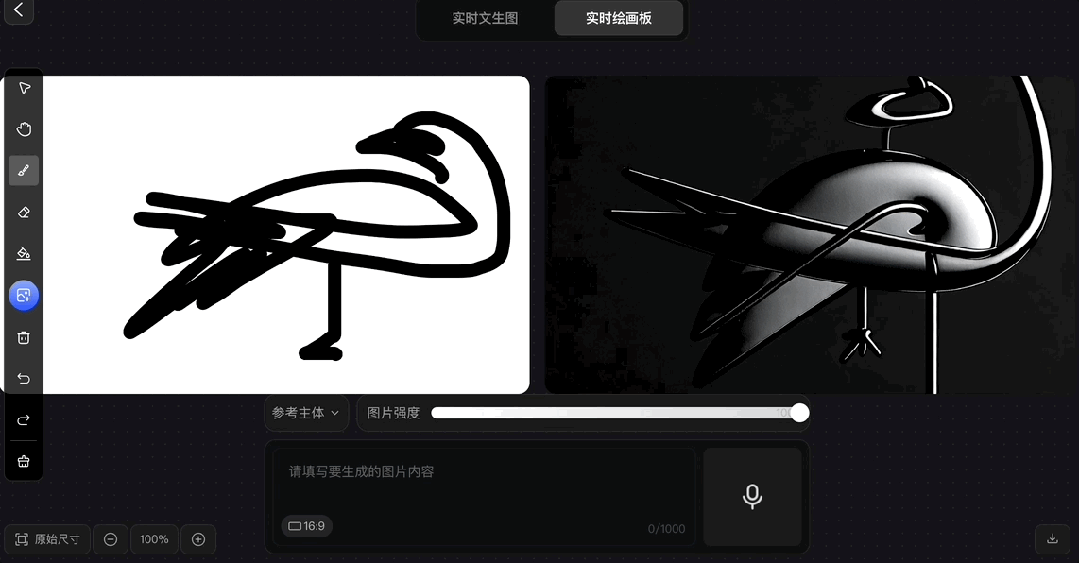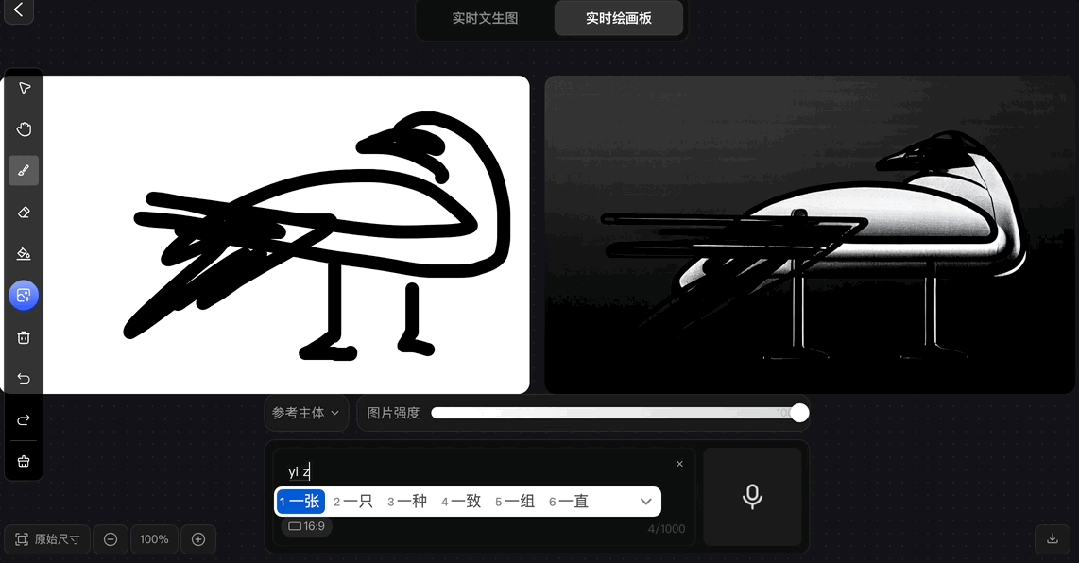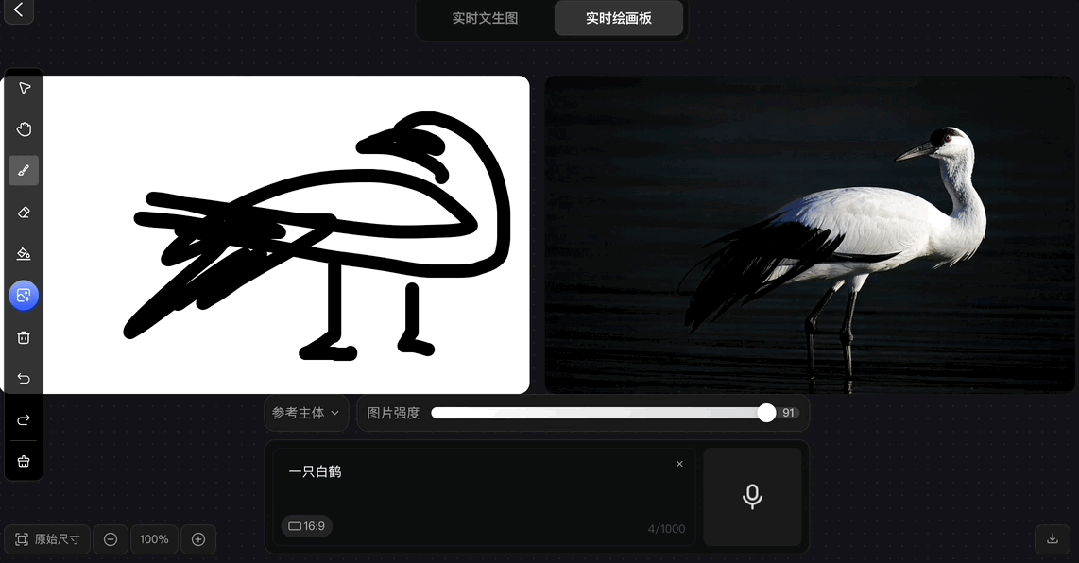
画出个大概即可,其余的交给Hunyuan Image 2.0~
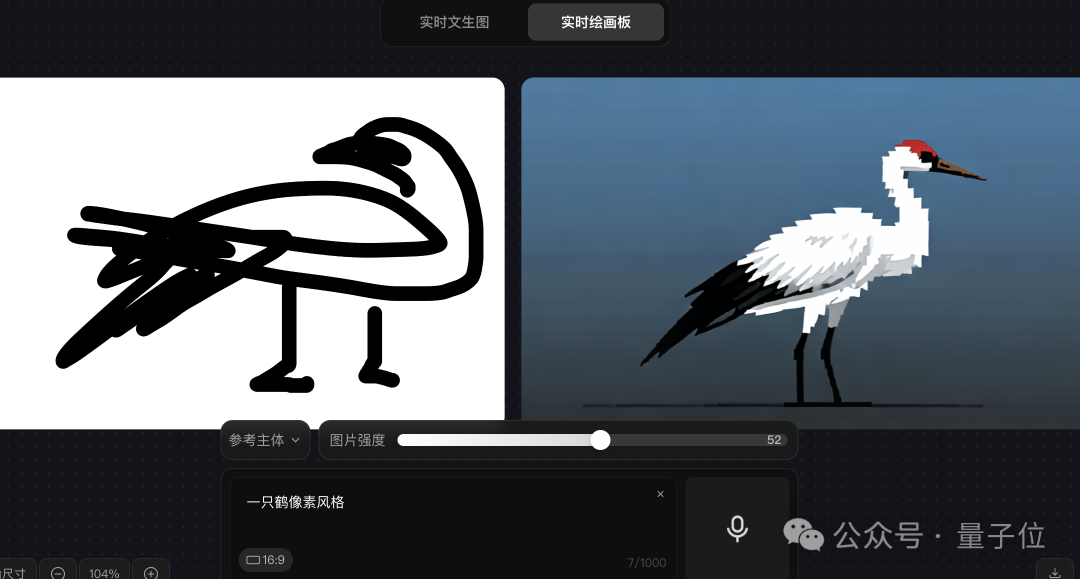
同样可以拖动设置图片强度,越强与左侧手绘的模样就越像。

效果看完,技术方面HunyuanImage2.0有何亮点?
经过全尺度多维度强化学习后训练
从目前资料来看,HunyuanImage2.0有以下几个亮点。
1、具有更大的模型尺寸
相比HunyuanDiT,HunyuanImage2.0将参数提升了一个数量级,更大的模型参数保证了模型的性能上限。
2、更高压缩倍率的图像编解码器
腾讯混元团队自研了超高压缩倍率的图像编解码器,大幅降低了图像的编码序列长度,从而加快生图速度。
为了在提高编码器信息压缩率的同时减少信息丢失和保证画面质量,他们对信息瓶颈层进行针对性优化并强化了对抗训练以提高细节生成能力,降低了生图时耗。
3、适配多模态大语言模型作为文本编码器
适配了多模态大语言模型(MLLM)作为文本编码器,使得文生图模型的语义遵从能力大幅提升。
相较于CLIP、T5等传统架构中的文本编码器的浅层语义解析,MLLM通过海量跨模态预训练和更大参数量的模型架构形成的深度表征能力, 可以更好的对文本进行解构编码。
通过适配训练后,HunyuanImage2.0能有更好的语义匹配能力,在语义能力测试的客观指标上(GenEval)远高于同类竞品。
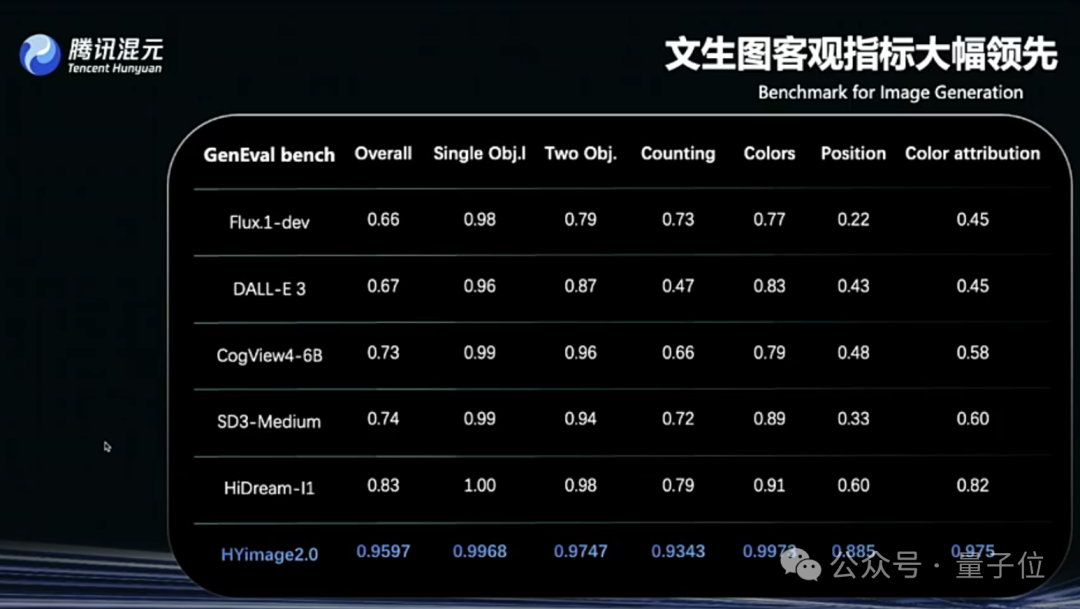
4、强化学习后训练
HunyuanImage2.0基于慢思考的reward model,通过通用后训练与美学后训练,有效提升图片生成的真实感,更符合现实需求。
5、自研对抗蒸馏方案
在后训练模型的基础上,基于隐空间一致性模型,通过训练将去噪轨迹上的任意点直接映射到轨迹生成样本,实现少步高质量生成。
更多细节,腾讯混元团队表示可关注后续技术报告的发布。
One more Thing
据说,发布会上,腾讯混元将剧透即将发布的原生多模态图像生成大模型信息,可以期待一下。
新模型在多轮图像生成、实时交互体验等方面有突出表现。
官网地址:https://hunyuan.tencent.com/
— 完 —
📪 量子位AI主题策划正在征集中!欢迎参与专题365行AI落地方案,一千零一个AI应用,或与我们分享你在寻找的AI产品,或发现的AI新动向。
💬 也欢迎你加入量子位每日AI交流群,一起来畅聊AI吧~

一键关注 👇 点亮星标
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!
(文:量子位)