

大模型推理引擎江湖再起波澜!

HuggingFace的「文本生成推理引擎」(TGI)v3版本突然杀出重围,一次性把性能提升到了离谱的程度:不仅能处理3倍的token数量,在长文本上更是比vLLM快了13倍!
最骚的是,你甚至不需要任何配置就能获得这样的性能!

TGI v3到底有多厉害?
让我们看看它创下的这些惊人记录:
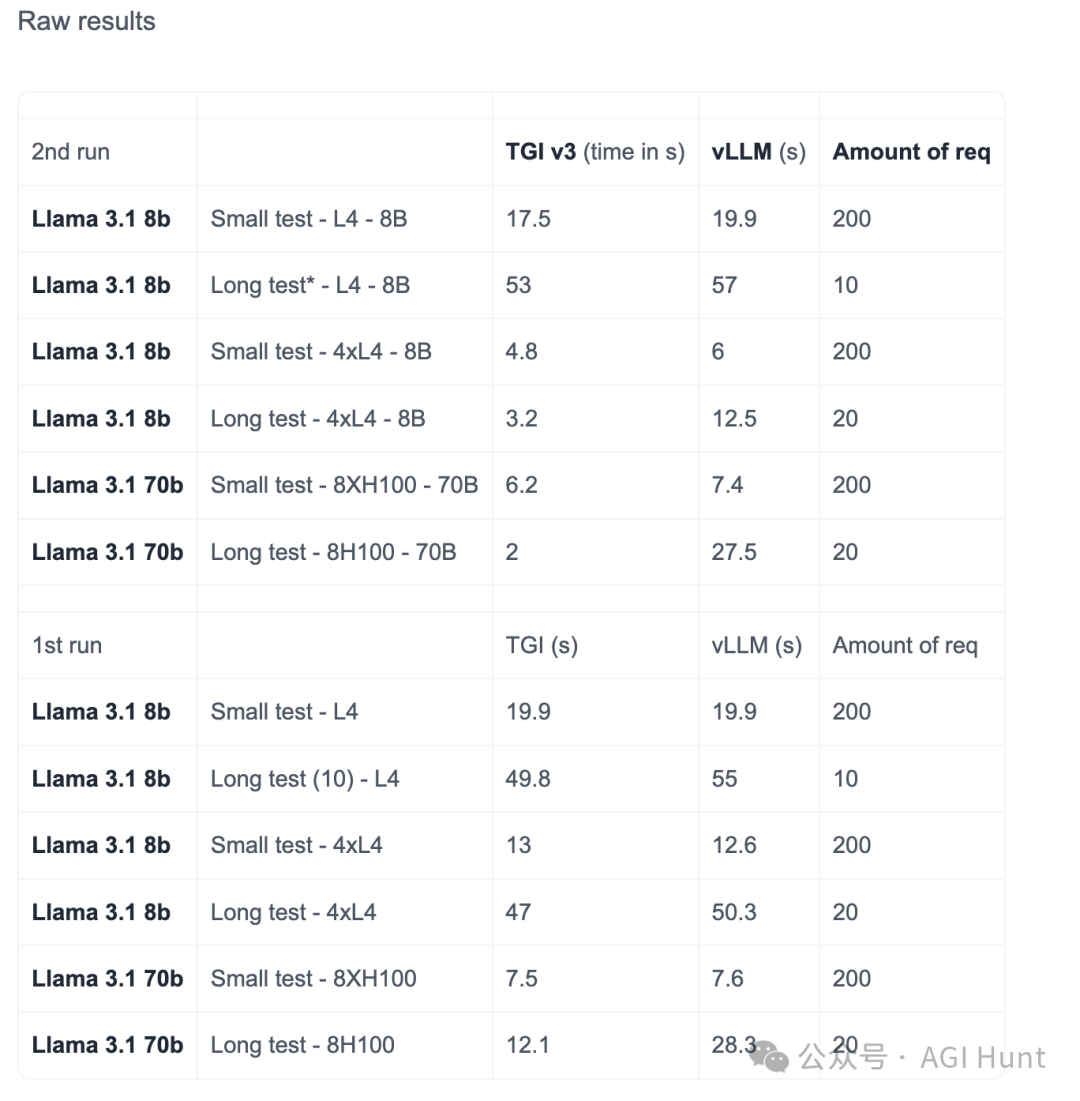
在单个L4(24GB)显卡上,TGI v3可以处理30k个token的llama 3.1-8B模型输入,而vLLM只能勉强处理10k个。这意味着你可以用更少的显存处理更长的文本!
不仅如此,在处理超长文本(200k+ tokens)时,vLLM需要花费27.5秒才能完成的任务,TGI 只需要2秒就能搞定!
这种「降维打击」是怎么做到的?
HuggingFace团队使用了一系列黑科技:
-
他们优化了前缀缓存结构,让查询匹配的开销只有6微秒
-
开发了新的「闪电推理」和「闪电解码」内核
-
改进了内存管理,大幅降低了显存占用
-
让系统能够自动评估硬件和模型,选择最佳配置
这些优化不是简单的堆砌,而是深思熟虑的结果。
比如logits计算这个大户,在处理100k+ tokens时会占用25.6GB显存,比llama 3.1-8b整个模型(16GB)还大!
TGI团队想出了一个妙招:既然大部分用户不需要每个token的logits,那就默认不计算它们。需要的用户可以通过flag手动开启,但会牺牲一些token处理能力。
对此,ML工程师Maziyar PANAHI表示:「他们早就告诉我该离开TGI了,但我说等3.0版本再说。现在看来我的等待没有白费!」
这次的升级不仅让TGI在性能上实现了质的飞跃,更重要的是它把「零配置」的理念推向了极致。
HuggingFace团队最后说到:「把所有flag都删了吧,你很可能会得到最好的性能。」
在生产环境中,他们已经完全不需要任何配置标志了。系统会自动评估硬件和模型,选择最佳参数。
简单,粗暴,有效。
这就是TGI v3。
(文:AGI Hunt)