


现在大家都用强化学习(RL)来训练大语言模型(LLM)做比较复杂的推理任务,比如数学题。其中,像 PPO 这样的算法虽然主流,但它需要额外的网络(critic network),搞得比较复杂和麻烦。
同时,像 GRPO 这样的算法在实践中效果很好(比如训练 DeepSeek-R1),但大家其实不太清楚它到底为什么有效,是不是真的比更简单的方法好很多。
另一方面,有一些非常简单的方法,比如 RAFT(拒绝采样),就是只用模型答对了的样本进行微调,似乎效果也不错。这就让研究者们好奇了:
1. 这些复杂的 RL 算法(比如 PPO、GRPO)相比于简单的 SFT 类方法(比如 RAFT),优势到底在哪里?真的有必要搞那么复杂吗?
2. GRPO 之所以效果好,是因为它算法本身的设计(比如奖励归一化),还是因为它在使用样本上的某些策略(比如如何处理答错的样本)?
3. 对于 LLM 这种输出是文字序列、环境相对确定的场景,是不是可以用更简洁、更适合的 RL 算法?
所以,这篇文章的出发点就是,重新审视和比较几种有代表性的 RL 方法(特别是 GRPO 和极简的 RAFT、以及基础的 Reinforce),弄清楚它们成功的关键因素,尤其是负样本(模型答错的例子)到底该怎么用,以及能不能找到一种既简单又有效的 RL 训练方法。

论文标题:
A Minimalist Approach to LLM Reasoning: from Rejection Sampling to Reinforce
论文地址:
https://arxiv.org/abs/2504.11343
GitHub地址:
https://github.com/rlhflow/minimal-rl
这篇文章主要有以下几个发现和贡献:
验证了极简方法的有效性:研究者们发现,RAFT 这个非常简单的拒绝采样方法(只用回答正确的样本训练),效果竟然和当前流行的 GRPO 方法差不多,甚至在训练早期收敛得更快。
这说明,对于这类任务,简单的“只学好的”策略本身就是一个很强的基准(baseline)。不过,他们也指出,RAFT 因为只用正样本,后期会因为模型探索性降低(熵减小太快)而被 GRPO 超越。
揭示了 GRPO 的优势来源:通过细致的对比实验(消融研究),他们发现 GRPO 相对于标准 Reinforce 算法的主要优势,其实来自于它在处理样本时,隐式地过滤掉了那些“所有回答都错了”的题目(prompt)。
也就是说,避免在完全失败的例子上学习,是 GRPO 效果提升的关键。相比之下,GRPO 中使用的那种根据同一题目下不同回答的好坏来做奖励归一化的技术,影响并不大。这说明,不是所有负样本都有用,有些负样本(全错的)甚至可能拖后腿。
提出了新的简化版 RL 算法:基于以上发现,他们提出了一个叫 Reinforce-Rej 的新方法。这个方法是对基础 Reinforce 算法的一个小改进,核心思想是:既不学习“所有回答都正确”的题目(可能太简单了),也不学习“所有回答都错误”的题目(可能是有害的),只在那些“有好有坏”的题目上进行学习。
实验证明,这个 Reinforce-Rej 方法最终性能和 GRPO 差不多,但是 KL 效率(衡量模型更新幅度)更高,训练更稳定。
提供了实践指导:总的来说,这项工作强调了在用奖励微调 LLM 时,“如何选择和使用训练样本”(尤其是负样本)比“用哪个复杂的 RL 算法”可能更重要。他们建议大家可以将 RAFT 作为一个简单、可靠的 baseline,并且未来的研究应该更深入、更原理性地去设计如何利用负样本,而不是不加区分地混用。

现有方法的详细分析
首先我们回顾几种用于 LLM 后训练(post-training)的代表性算法:
1.1 RAFT(拒绝采样微调)
RAFT 这个方法,在文献里也叫拒绝采样微调(Rejection Sampling Fine-tuning)。它的操作步骤很简单,主要分三步:
1. 收集数据:拿一批提示 x ,用一个参考模型(比如当前模型自己)给每个提示生成 n 个回答。
2. 筛选数据(拒绝采样):用奖励函数 r(x, a) 给每个回答打分,只保留那些得分最高的(通常是奖励为 1 的,也就是正确的回答)。把这些筛选出来的“好”样本汇总成数据集 D 。
3. 模型微调:用这个只包含好样本的数据集 D 来微调当前的模型 π ,目标是最大化模型在这些好样本上的对数似然。
1.2 策略梯度(Policy Gradient)与 Reinforce
这是强化学习里的经典方法。核心思想是优化一个目标函数 J(θ) ,这个函数代表了模型在所有可能的提示 x 下,生成回答 a 并获得奖励 r(x, a) 的期望值:

目标是找到让 J(θ) 最大的模型参数 θ 。通常用梯度上升来更新参数:
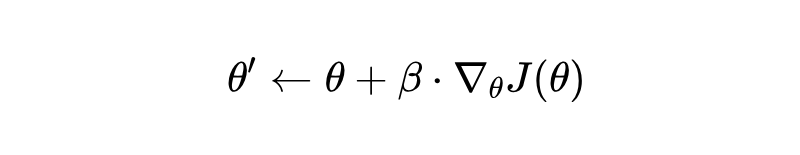
这里的 ∇θ J(θ) 就是策略梯度,它的计算公式是:
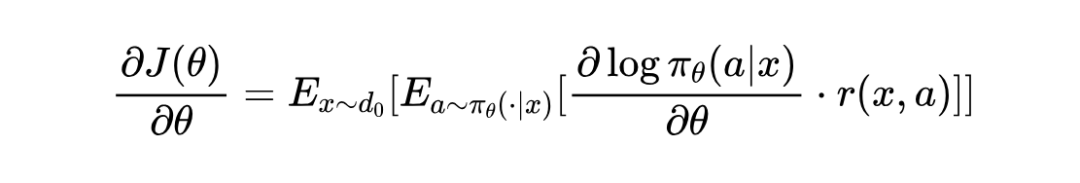
为了让训练更稳定,防止新旧模型差异过大导致重要性采样权重 爆炸,研究者们借鉴了 PPO 算法里的裁剪(clipping)技术。最终,Reinforce 算法的损失函数(这里是最小化负的目标函数)可以写成:

由于 LLM 是自回归的(一个 token 一个 token 地生成),通常会把上面的损失函数应用到 token 层面:
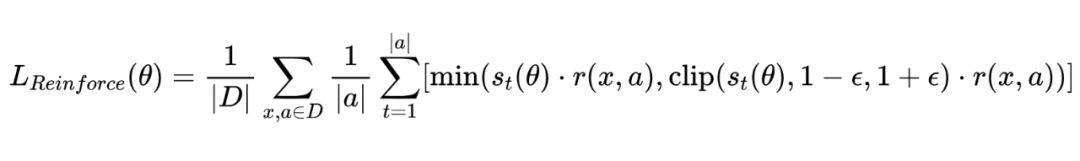
1.3 GRPO
GRPO 的损失函数形式和上面 Reinforce 的 token-level 损失很像。关键区别在于,它不用原始的奖励 r(x, a) ,而是用一个为每个 token 计算的优势函数(Advantage Function)。
具体计算方法是:对每个提示 x ,采样 n 个回答 ,得到对应的奖励 。然后计算这些奖励的平均值 mean 和标准差 std 。第 i 个回答中第 t 个 token 的优势值计算如下:
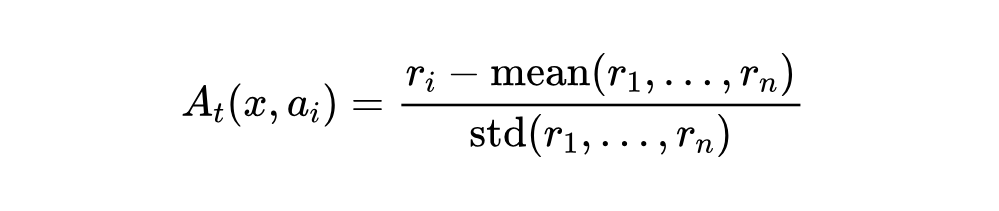
这里的 mean(r_1, …, rn) 在强化学习里叫做基线(baseline),它的作用是减小梯度估计的方差,让训练更稳定。
1.4(Iterative)DPO(直接偏好优化)
DPO 是一种不同的方法,它不直接用奖励分数,而是依赖于成对的比较数据。数据集里是这样的样本: (x, a+, a-) ,表示对于提示 x ,回答 a+ 比 a- 更好。
DPO 优化的目标是一个对比损失(contrastive loss):
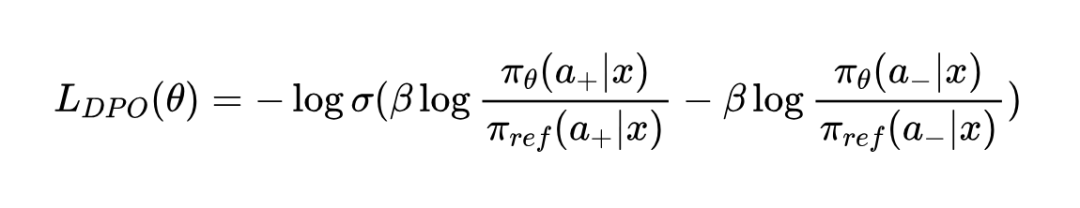
这里, σ 是 sigmoid 函数, β 是一个超参数(大于 0), π_ref 通常是初始的模型或者一个固定的参考模型。
原始的 DPO 是在离线数据上训练的。但后续研究发现,可以迭代进行:用训练过程中的模型去生成新的回答,然后根据某种方式(比如模型自己打分或者人工标注)得到新的偏好对 (a+, a-) ,再用这些新的在线数据继续训练模型。这种迭代的方式可以显著提升模型性能。
1.5 RAFT++
研究者注意到,RAFT 如果在每次迭代中,用收集到的数据(replay buffer)进行多步梯度更新,那它其实也可以看作是一种混合了离策略(off-policy)的算法。
基于这个想法,他们提出了 RAFT++,就是把 Reinforce 里的重要性采样和裁剪技术也应用到 RAFT 上。它的损失函数形式和 Reinforce 类似,但有一个关键区别:它只在最好的样本(奖励最高的那些,也就是正样本)上进行训练。这通过一个指示函数 I 来实现:
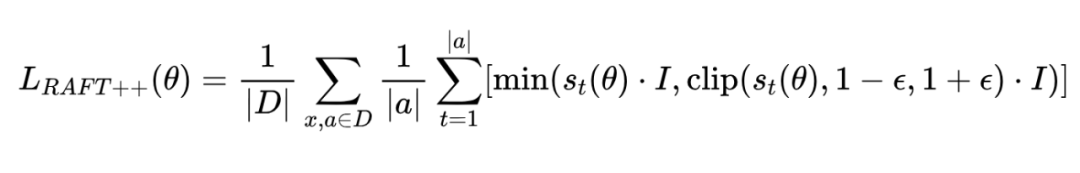
其中 是一个指示函数,当当前回答 a 是所有 n 个回答里奖励最高的那个时, I 等于 1,否则等于 0。这样就保证了只有正样本对损失有贡献。

实验结果与有趣的发现汇总
以下是基于提供的实验部分的解读,总结出的主要结果和有趣发现:

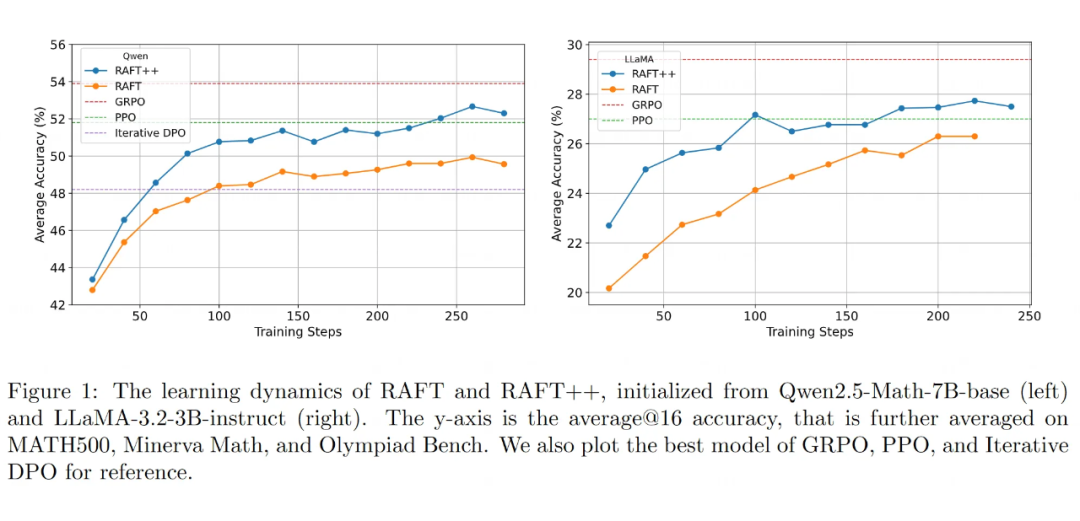
简单方法表现惊艳:
-
RAFT 及其改进版 RAFT++ ,虽然是相对简单的基于“拒绝采样”的方法(只用好的样本),但在数学推理任务上的表现出人意料地好。
-
它们的效果能跟更复杂的深度强化学习方法(如 PPO , GRPO )打个平手,超过了 iterative DPO 。
-
尤其是在 Qwen 模型上, RAFT++ (52.5%)的平均准确率非常接近当时效果最好的 GRPO (53.9%)。
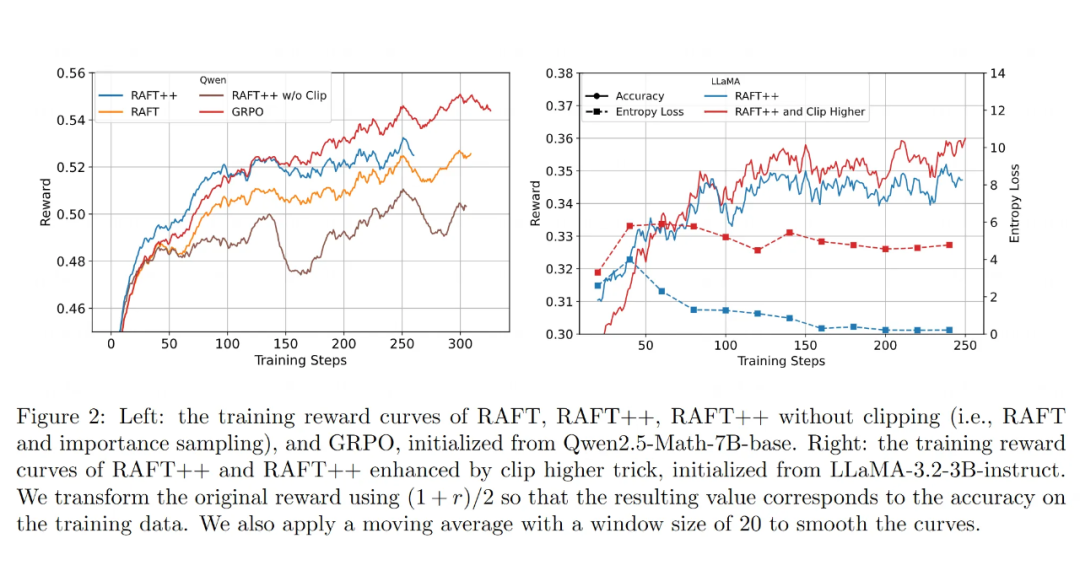
RAFT++ 的改进有效:
-
在 RAFT 基础上加入重要性采样(修正数据分布偏差)和裁剪(限制更新幅度)技术后形成的 RAFT++ ,确实比原版 RAFT 收敛更快,最终准确率也更高。
-
实验证明,裁剪步骤非常关键。如果只用重要性采样而不进行裁剪,效果反而会变差,说明无限制的更新可能会破坏训练稳定性。
学习动态对比:先快后慢 vs 持续提升:
-
RAFT++ 在训练早期学得比 GRPO 更快。
-
* 但是, RAFT++ 的性能提升在训练中后期会明显放缓,最终被 GRPO 反超。
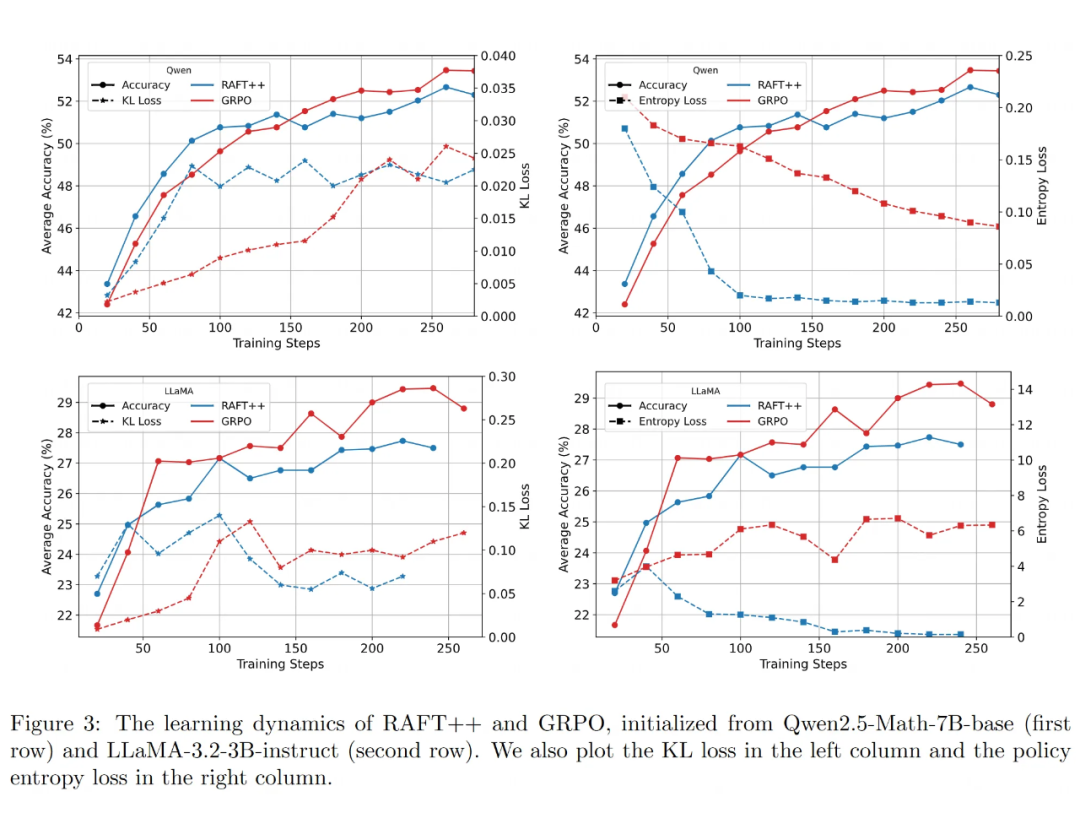
负样本是把“双刃剑”?
-
RAFT++ (只用正样本)性能提升放缓与其策略熵(模型探索性/答案多样性)的快速下降有关。熵太低,模型就不太会探索新的推理路径了。
-
GRPO 因为也考虑了负样本,策略熵下降较慢,保持了更长时间的探索能力,所以后期还能继续提升。这表明,负样本可能有助于维持探索。
-
然而,简单的 Reinforce 算法(也用负样本)在 LLaMA 模型上效果反而不如只用正样本的 RAFT++ 。这暗示,如何定义和使用负样本很重要,仅仅基于最终答案对错可能过于粗糙,不一定总能带来好处。

▲ 在 GRPO 和强化学习类型算法的各个组件上进行的消融研究。将 GRPO 与其他基于强化学习的变种进行比较,以隔离去除错误样本、正确样本和应用标准化的影响。去除错误样本(“移除所有错误”)提供了最大的奖励增益,突出了它们的有害影响。相比之下,去除正确样本没有增益。均值归零标准化增加了 KL 损失并不稳定训练。按标准差标准化几乎没有额外的好处。“Reinforce + Remove both” 变种在奖励、KL 稳定性和熵正则化之间达到了很好的平衡。
GRPO 强大的核心在于“样本剔除”:
-
通过详细的消融实验对比 Reinforce 的各种变体,发现 GRPO 性能优越的关键在于剔除了那些所有生成答案都错误的样本(“Remove all wrong”)。这些全是错误的样本对训练的干扰最大。
-
相比之下,奖励归一化(如减去均值或除以标准差)对性能提升作用不大,甚至简单的均值归一化还会导致训练不稳定。
-
剔除所有答案都正确的样本(“Remove all correct”)帮助也不大。
-
同时剔除“全对”和“全错”样本的策略(称为 Reinforce-Rej )在性能、稳定性和保持探索性之间取得了不错的平衡。

一些思考
提出新的简化基准:
-
基于以上发现,研究者认为 RAFT++ 和 Reinforce-Rej (剔除全对和全错样本的 Reinforce)是有效且更简单的基准算法,值得未来研究参考。
对负样本作用的新思考:
-
研究结果表明,在基于强化学习的大模型训练中,负样本的作用比想象中更微妙。直接使用所有负样本不一定最好,未来可能需要更精细化的方法来筛选和利用不同质量的样本。
(文:PaperWeekly)