
文档翻译
概述
docext是一个无需OCR的工具,用于从发票、护照等文档图像中提取结构化信息。它利用视觉语言模型(VLMs)准确识别并提取文档中的字段数据和表格信息。
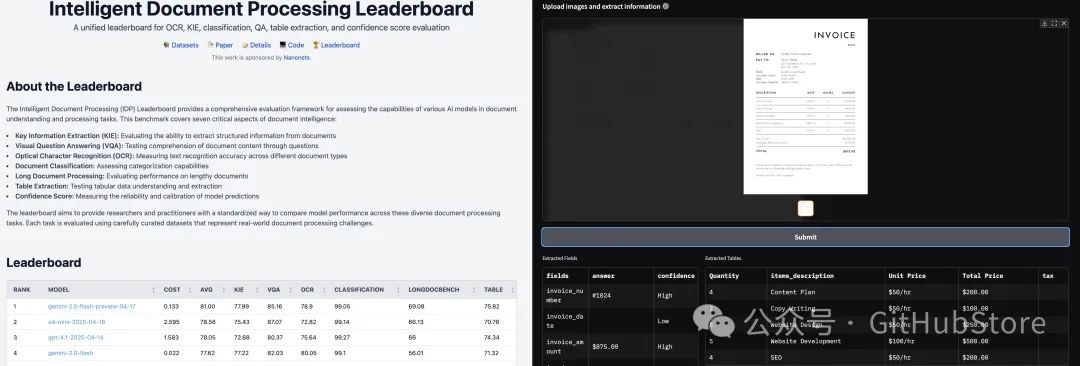
智能文档处理排行榜追踪并评估视觉语言模型在OCR、关键信息提取(KIE)、文档分类、表格提取等智能文档处理任务中的表现。
功能特点
智能文档处理排行榜
该基准测试评估七个关键文档智能挑战:
-
• 关键信息提取(KIE):从非结构化文档文本中提取结构化字段 -
• 视觉问答(VQA):通过问答评估对文档内容的理解 -
• 光学字符识别(OCR):测量打印和手写文本的识别准确率 -
• 文档分类:评估模型对各类文档的分类准确性 -
• 长文档处理:测试模型对长篇、上下文丰富文档的推理能力 -
• 表格提取:从复杂表格格式中提取结构化数据的基准测试 -
• 置信度分数校准:评估模型预测的可靠性和置信度
🔍 详细信息请参阅发布博客。
📊 实时排行榜: https://idp-leaderboard.org
有关设置说明和其他详情,请查看智能文档处理排行榜完整功能指南。
Docext核心功能
-
• 灵活提取:可自定义字段或使用预建模板 -
• 表格提取:从文档中提取结构化表格数据 -
• 置信度评分:获取提取信息的置信度水平 -
• 本地化部署:完全在自有基础设施上运行(支持Linux、MacOS) -
• 多页支持:处理多页文档 -
• REST API:提供编程接口便于系统集成 -
• 预建模板:常见文档类型的即用模板: -
• 发票 -
• 护照 -
• 可为其他模板添加/删除新字段/列
更多功能详情,请查看功能指南。
项目地址
https://github.com/NanoNets/docext/blob/main/README.md
扫码加入技术交流群,备注「开发语言-城市-昵称」
(文:GitHubStore)