



TPO:推理时即时偏好对齐的新方案
为了让大模型(LLM)的行为更符合人类预期,一系列训练时对齐方法(例如 RLHF 和 DPO)通过微调模型参数来实现偏好优化。然而,这种“训练时对齐”模式不仅耗时耗力,而且一旦偏好发生变化(比如安全标准更新),就得从头开始再训练一次。这种方式在应对变化需求时显得十分被动。
有没有一种方法,可以跳过繁琐的重新训练,让模型在推理时就快速对齐人类偏好呢?
最近,上海人工智能实验室提出 Test-Time Preference Optimization(测试时偏好优化,TPO)。一句话总结:TPO 让大模型在每次回答时通过迭代的文本反馈自行调整输出,实现了无需更新模型权重的“即插即用”对齐。
不同于 RLHF、DPO 这类需要离线训练来优化参数的做法,TPO 完全在推理过程中完成偏好优化,模型参数保持不变。研究显示,TPO 作为一种实用的轻量级替代方案,能够在推理时动态地将模型输出对齐人类偏好。

论文标题:
Test-Time Preference Optimization: On-the-Fly Alignment via Iterative Textual Feedback
论文地址:
arxiv.org/abs/2501.12895
Huggingface 地址:
https://huggingface.co/papers/2501.12895
Github 地址:
https://github.com/yafuly/TPO

TPO = 文本形式的梯度下降
TPO 的核心直觉是让模型一边生成回答,一边根据反馈不断改进,本质上相当于在文本空间执行了一次“梯度下降”优化。
简单来说,模型利用自身的指令理解与推理能力,把数值化的奖励信号翻译成可读的文本建议,进而调整后续回答方向。整个过程无需显式计算梯度或更新权重,而是在自然语言交互中完成对输出的优化。
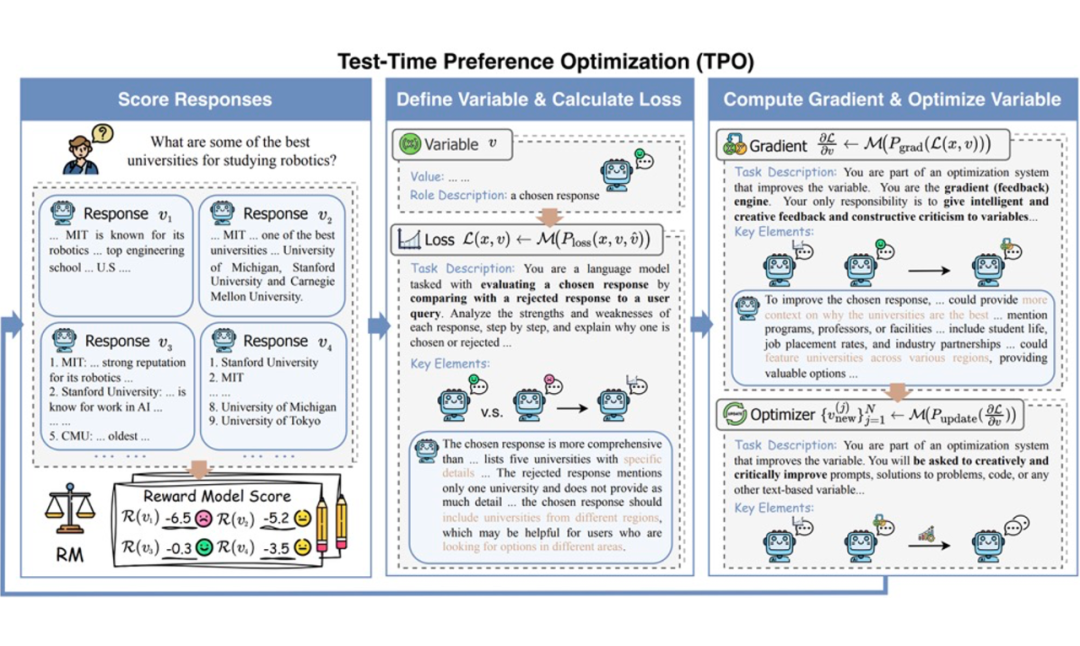
▲ 图表1:展示了 TPO 的三个关键步骤,模拟语言化的“梯度下降”过程。
如图 1 所示,TPO 的对齐过程包含类似梯度优化的几个步骤:模型先产生初步回答,然后获取反馈信号,生成改进建议,最后据此更新回答,并可视需要重复迭代。具体过程如下:
1. 候选回答生成:给定用户查询,语言模型会先生成多个初始回答,并通过预先训练好的奖励模型(reward model)对这些回答打分。我们选出得分最高的回答作为“优选”(chosen)和得分最低的回答作为“弃选”(rejected)。
2. 文本损失计算:接下来,令 LLM 将优选回答和弃选回答放在一起进行比较。通过一个精心设计的提示(prompt),模型会产出一段点评,指出为何优选回答比弃选回答好,以及后者存在哪些不足。这相当于计算出了一个“文本损失”:以自然语言描述了当前回答偏离人类偏好的程度和原因。
3. 文本梯度计算:然后,再通过新的提示要求模型根据上述点评提出改进建议。这些建议可以看作是针对回答的“文本梯度”——指明了如何调整回答可以更好地满足偏好。
4. 更新回答:最后,模型参考这些文本建议,生成一个或多个改进后的新回答。新的回答通常在之前薄弱的方面有所加强,相当于沿着文本梯度迈出了一步完成对输出的更新。
通过上述循环,模型的输出会被逐步“打磨”得更加符合奖励模型(也即人类偏好代理)的要求。可以看到,这一流程其实正对应了传统梯度下降的“三步走”:计算损失 → 计算梯度 → 更新参数,只不过在 TPO 中,这三步都由模型在文本层面完成了。
不同于数值优化方法直接修改模型的权重,TPO 是在固定模型参数的前提下优化输出内容,因此更加安全可控。从某种角度看,TPO 让模型在推理阶段进行了一次“小规模的自我训练”,利用自然语言反馈挖掘了预训练模型自身的潜力。

对齐效果与性能表现
作者在多个基准数据集上对 TPO 进行了评测,涵盖了从指令跟随(如 AlpacaEval、Arena)、偏好对齐(如 HH-RLHF 数据集)、安全性(如 BeaverTails 和 XSTest)到数学(MATH-500)等多方面的任务。
结果显示,只需要极少的迭代步数(例如两轮 TPO 优化),无论是原本未对齐的基准模型还是已经过 RLHF 对齐的模型,都能取得显著的性能提升。
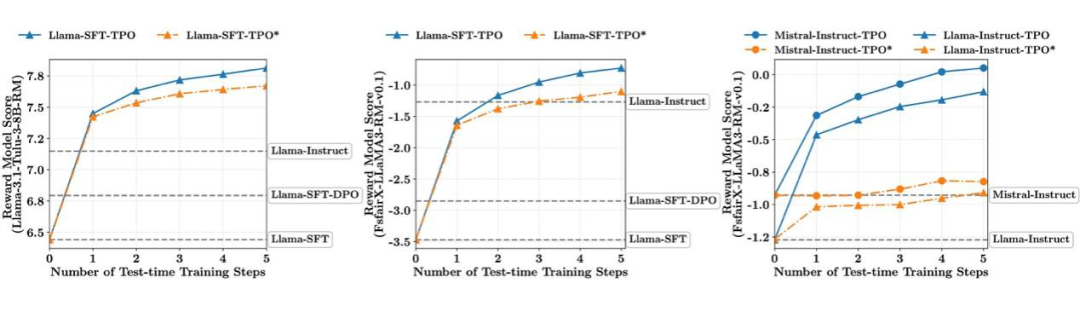
▲ 图表2:展示了 TPO 在推理过程中对模型输出质量的提升效果(纵轴为奖励模型打分,横轴为 TPO 迭代步数)。
如图 2 所示,在 TPO 迭代过程中,未对齐模型(SFT)的奖励得分曲线会逐步上升并超过已对齐模型(Instruct)的水平(图中虚线对应模型不经 TPO 时的固定得分基线)。
与此同时,即使对于原本已经对齐过的模型(Instruct 模型),TPO 依然能够进一步提升其输出质量。
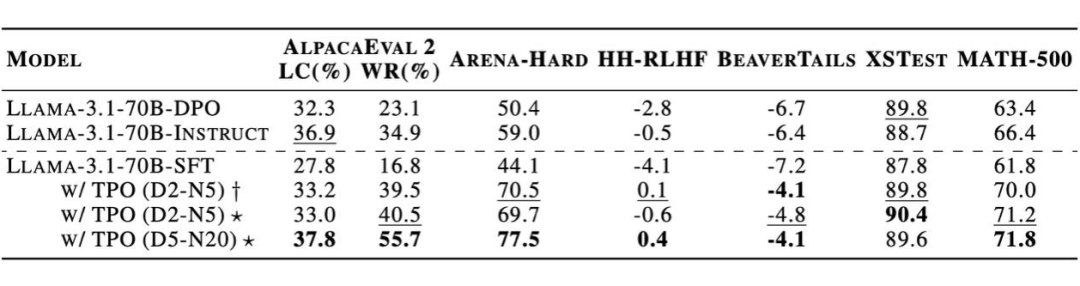
▲ 图表3:TPO 在未经训练对齐模型(SFT)上的性能表现。
尤其值得注意的是,一个原本未经过任何偏好训练的 Llama-3.1-70B-SFT 基础模型,在仅仅两步 TPO 优化后,其偏好得分在几乎所有评测基准上都超越了经过强化学习对齐的同款模型 Llama-3.1-70B-Instruct。
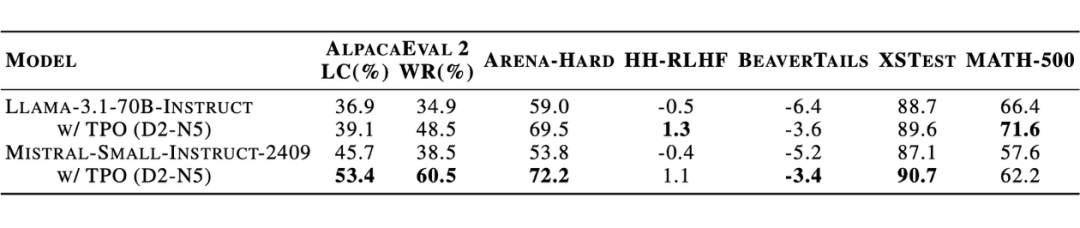
▲ 图表4:TPO 在已对齐模型上的性能表现
此外,在已经经过对齐后的模型上,TPO也能进一步提升模型在各类任务上的表现,而无需额外训练。

“宽深结合”的测试时拓展范式
TPO 的一个核心优势,是它不仅可以在推理阶段实现即时对齐,更提供了灵活可调的“宽度 + 深度”推理拓展策略(test-time scaling),即通过控制每轮的候选生成数量(宽度)与迭代优化轮数(深度),显著提升输出质量与偏好一致性。
这在实践中尤为关键:很多时候,我们并不希望或无法一开始就生成几十上百个候选(如 BoN-60),例如显存不支持;但如果能以较小的资源代价换取逐步优化效果,无疑更具实用价值。
论文通过系统实验分析了宽度和深度的作用:
-
采样宽度(N)决定了每轮优化前可供选择的回答多样性。宽度越大,初始候选越丰富,越容易获得高质量基础版本,然而要求更大的显存空间;
-
优化深度(D)控制了 TPO 能够反复打磨输出的轮数。深度增加意味着模型有更多机会消化反馈并改进生成,然而需要更多的迭代时间;
-
宽与深具有互补性:宽度加快收敛,深度增强精细度,两者配合,可在保持成本可控的前提下取得更优效果。
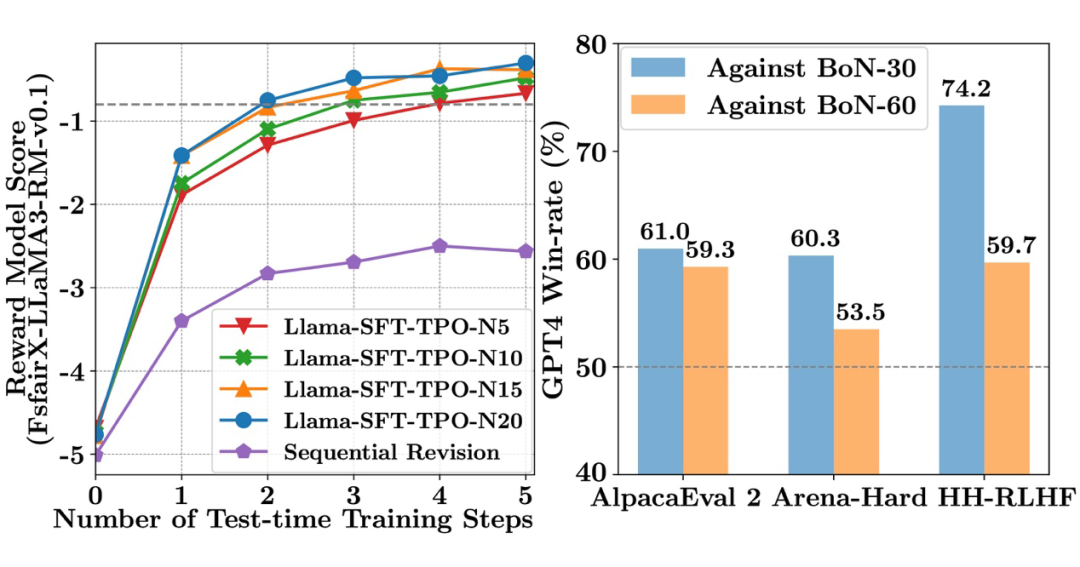
▲ 图表5:左图:搜索宽度对 TPO 的影响;右图:TPO 对 BoN 的胜率。
如图 5 所示,左图展示了在 HH-RLHF 数据集上,TPO 在不同宽度设置下的训练曲线。可以看出,从 N=5 到 N=20,TPO 的表现持续提升,并远优于“仅通过修改”的顺序优化方法(Sequential Revision)。
更令人印象深刻的是:只用两轮 TPO、每轮生成 5 个回答(D2-N5),就已足以超过需要采样 60 个样本的 Best-of-N(BoN-60)策略。
这表明:与其一开始就穷举生成多个候选,不如通过反馈引导做“聪明的迭代”。TPO 的“宽深结合”机制,本质上是一种高效的测试时推理优化方式,为 LLM 在资源受限环境下的性能释放提供了新路径。

总结与展望:推理,也可以成为对齐的起点
TPO 展示了一种轻量、灵活、可解释的新范式:不调参数,只用自然语言反馈,就能在推理阶段实现偏好优化。
相比于训练时对齐方法,TPO 仅需使用极少计算开销。在已对齐模型上继续提升,在未对齐模型上实现“即插即用”的快速进化, TPO 不仅降低了对齐门槛,也拓展了 LLM 推理能力的边界。
更重要的是,TPO 背后的思想具有高度可扩展性:将优化过程“语言化”,再由模型自主理解与执行。这为未来 LLM 的可控性、安全性乃至个性化定制提供了通用路径。
展望未来,我们相信 TPO 只是一个开始。推理阶段的优化、调试与反馈机制还大有可为,而大语言模型“听得懂反馈、改得了输出”的能力,也将在这一过程中被进一步激发出来。
对齐,不一定是训练的终点;也可以是推理的起点。
(文:PaperWeekly)