

白交 发自 凹非寺
量子位 | 公众号 QbitAI
何恺明等团队新作新鲜出炉,再次大道至简——
他们引入平均速度,实现「一步生成」新SOTA。

CMU博士生耿正阳一作,何恺明的学生邓明扬、白行健参与。
他们提出的模型是从头开始训练的,没有任何预训练、蒸馏或课程学习,最终实现了3.43的FID值,明显优于之前最先进的一步扩散/流模型。
一步生成框架:引入平均速度
一次生成模型,指的是只需一步计算就产生高质量的结果,而无需多次迭代。
团队提出了一个原则性强且有效的单步生成框架MeanFlow。其核心思想是引入平均速度的概念来表征流场,这与流匹配方法所模拟的瞬时速度截然不同。
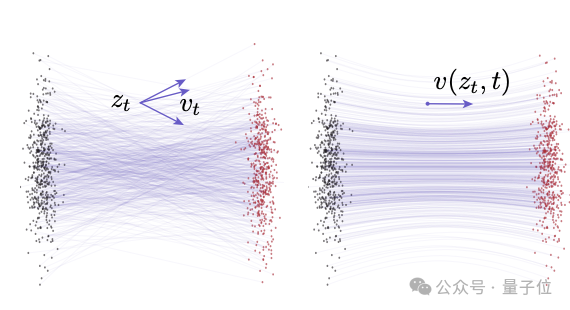
△流匹配的速度场,瞬时速度
平均速度被定义为位移与时间间隔的比率,位移由瞬时速度的时间积分给出。
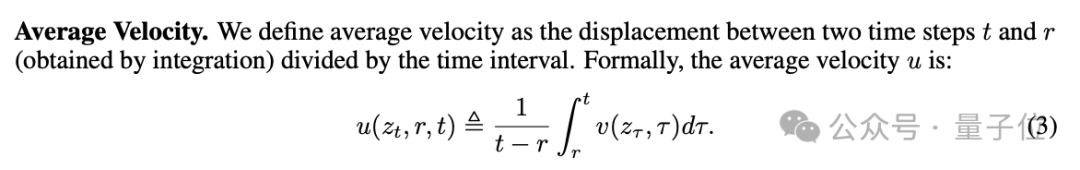
根据这一定义,这说明平均速度和瞬时速度之间定义明确的内在联系,这自然成为指导网络训练的原则基础。

我们的方法被称为MeanFlow模型,它自成一体,无需预先训练、提炼或课程学习。
演示1:通过jvp计算只需要一次后向传递,类似于神经网络中的标准反向传播,开销不到总训练时间的20%。

演示2提供了伪代码。虽然一步采样是这项工作的重点,但团队要强调的是,根据下面的公式,几步采样也是很简单的。
他们在256×256分辨率下生成的ImageNet上进行了主要实验,并对函数评估次数(NFE)进行了检验,并研究了默认情况下的1-NFE生成。
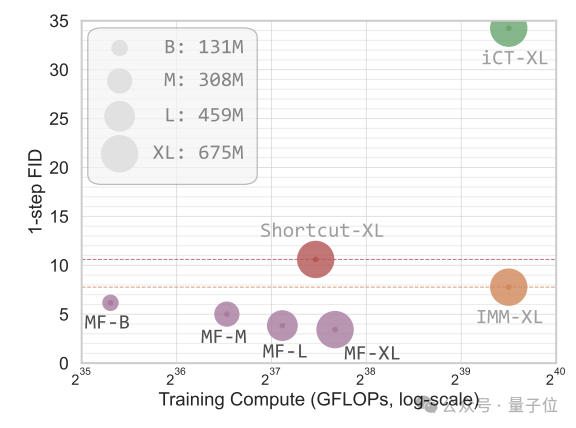
它在从零开始训练的ImageNet 256×256上通过1-NFE达到了3.43的FID,这一结果以50%到70%的相对优势明显优于同类中以前的先进方法。
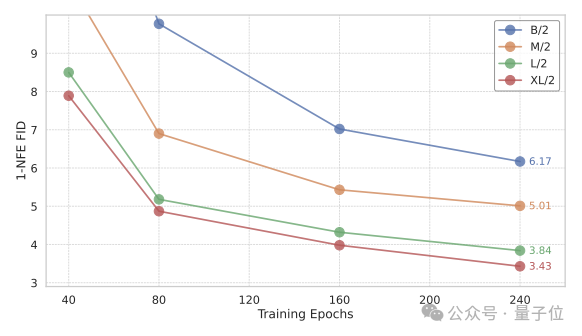
1-NFE ImageNet 256×256 生成的消融研究。

MeanFlow模型在256×256 ImageNet在模型大小方面表现出良好的可扩展性。
与其他生成模型对比,从零开始训练的1-NFE和2-NFE扩散/流动模型。
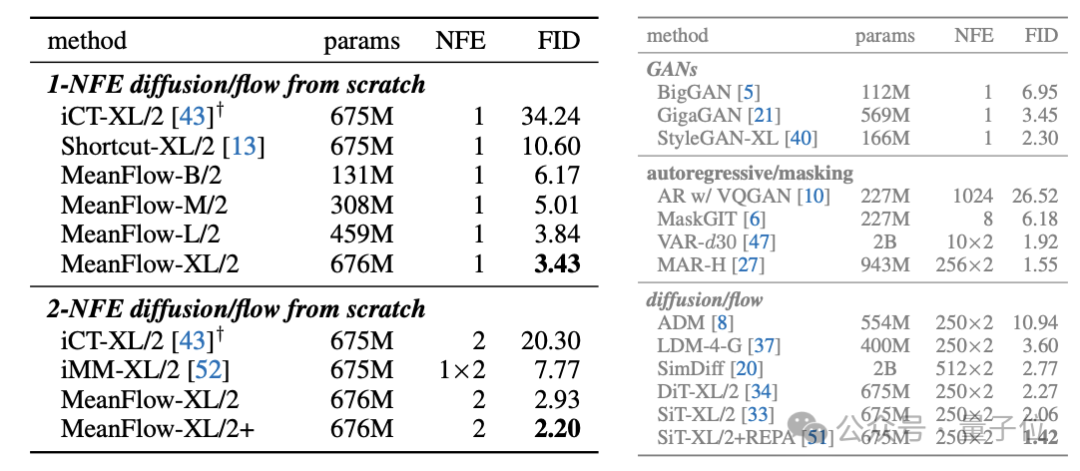
该研究大大缩小了一步式扩散/流模型与其多步式前身之间的差距。
从广义上讲,这项工作所考虑的情况与物理领域的多尺度模拟问题有关,这些问题可能涉及空间或时间上的一系列尺度、长度和分辨率。进行数值模拟本身就受到计算机分辨尺度范围能力的限制。他们的模拟涉及在更粗的粒度水平上描述基本量,这是物理学中许多重要应用的共同主题。团队希望他们工作能为相关领域的生成建模、模拟和动力系统研究架起一座桥梁。
MIT&CMU团队
这一成果由MIT&CMU团队共同完成。

其中一作耿正阳,CMU计算机博士生,导师是Zico Kolter,在MIT交流时完成此成果。此前在北大当研究助理,此外还曾在Meta Reality Labs实习,致力于识别、理解和开发自组织复杂系统的动力学。
此外还有何恺明的两位学生:邓明扬、白行健。
邓明扬本科也是在MIT读数学和计算机科学。目前他的研究重点是机器学习,特别是理解和推进生成式基础模型,包括扩散模型和大型语言模型。
白行健,他拥有牛津大学数学与计算机科学硕士和学士学位。研究方向为经典算法与深度学习的交叉领域,涵盖物理启发式生成模型和学习增强算法等主题。更广泛地说,致力于那些具有科学影响力和启发性的研究。
论文链接:
https://arxiv.org/abs/2505.13447v1
— 完 —
📪 量子位AI主题策划正在征集中!欢迎参与专题365行AI落地方案,一千零一个AI应用,或与我们分享你在寻找的AI产品,或发现的AI新动向。
💬 也欢迎你加入量子位每日AI交流群,一起来畅聊AI吧~

一键关注 👇 点亮星标
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!
(文:量子位)