


第一阶段:混合微调
-
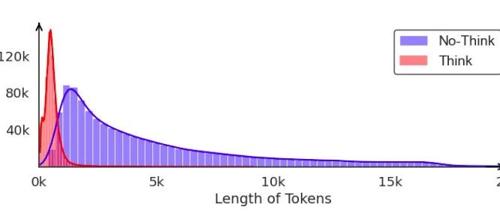
数据构建:混合微调数据集包含推理密集型(思考模式)和直接回答(无思考模式)的样本。思考模式的数据集包括高质量的数学、代码和科学问题,而无思考模式的数据集则包含简单的查询。
-
优化目标:HFT 的目标是基于上下文预测下一个标记。
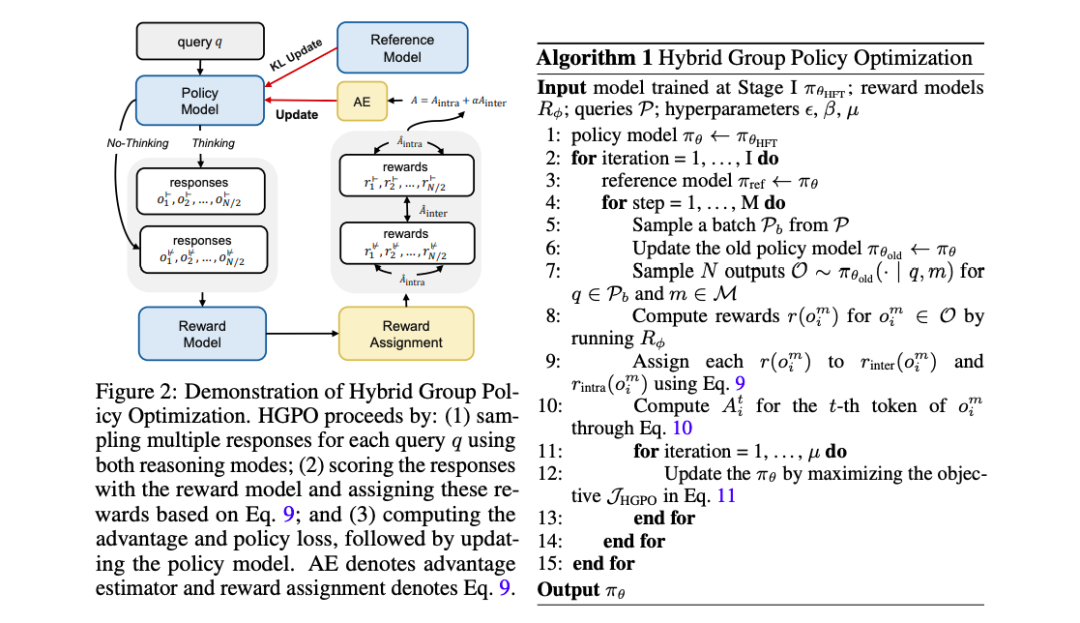
第二阶段:混合群体策略优化
-
采样策略:对于每个查询 q,从旧策略中分别使用两种推理模式采样 N 个候选响应奖
-
励评分和分配:使用奖励函数对每个候选输出进行评分,并根据平均奖励值分配二进制奖励,以捕获不同推理模式之间的相对质量和每个推理模式内的答案质量。
-
优势估计:使用 GRPO 作为默认优势估计器,计算每个响应的最终每标记优势。
-
优化目标:HGPO 通过最大化以下目标函数来优化策略模型,该函数结合了奖励和策略更新的约束。
评估混合思考能力
-
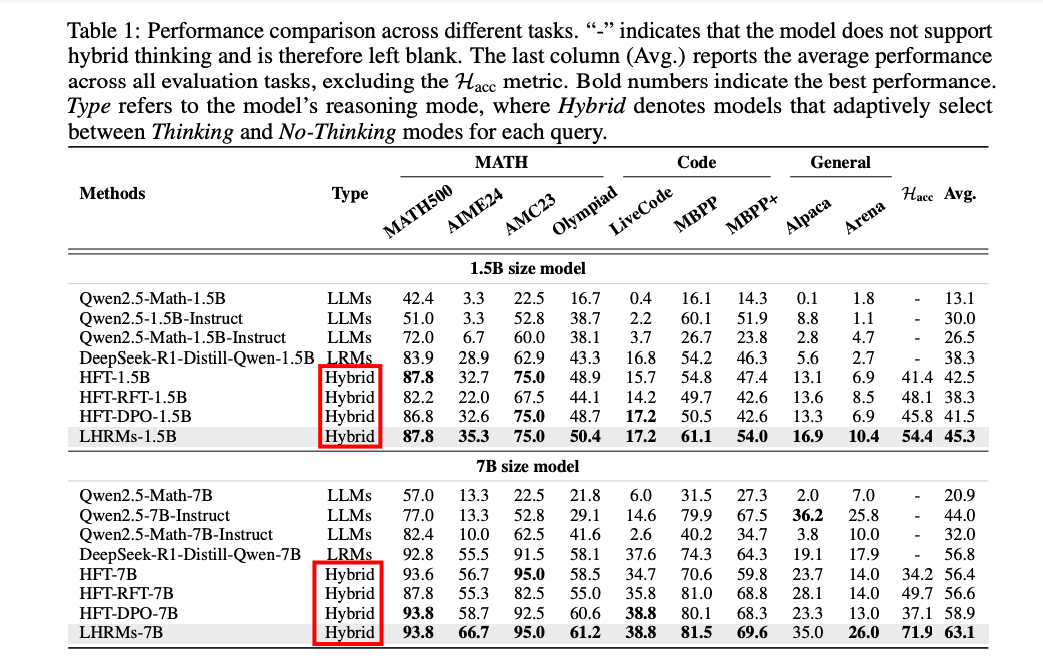
混合准确率(Hybrid Accuracy, HAcc):提出一个新的评估指标 HAcc,用于衡量模型在不同任务中正确选择适当推理模式的能力。通过比较模型选择的推理模式与基于奖励模型评分的“真实”推理模式的一致性来计算 HAcc。


https://arxiv.org/pdf/2505.14631Think Only When You Need with Large Hybrid-Reasoning Models
(文:PaperAgent)