

针对现有大模型知识遗忘方法可能损害生成能力的问题,本文基于“以新知覆盖旧知”的理念,提出了 ReLearn —— 一种将数据增强与模型微调相结合的高效知识遗忘框架。

论文题目:
ReLearn: Unlearning via Learning for Large Language Models
本文作者:
徐浩铭(浙江大学)、赵宁远(厦门大学)、杨理明(清华大学)、赵森栋(哈尔滨工业大学)、邓淑敏(新加坡国立大学)、王梦如(浙江大学)、Bryan Hooi(新加坡国立大学)、Nay Oo(新加坡国立大学)、陈华钧(浙江大学)、张宁豫(浙江大学)
发表会议:
ACL 2025
论文链接:
https://arxiv.org/abs/2502.11190
代码链接:
https://github.com/zjunlp/unlearn

引言
大模型知识遗忘旨在通过编辑大模型参数实现隐私、偏见等信息的擦除,支撑可靠、可信的大模型应用。
当前主流遗忘方法多采用“反向优化”(如梯度上升),旨在抑制特定内容的输出概率。这种仅依赖负向调整的策略,往往使模型难以采样到合理答案,进而破坏输出的连贯性并损害整体语言性能。此外,现有评估指标也过分关注局部遗忘,而忽略了生成内容的流畅度与相关性。
为应对此,本文提出 ReLearn:一个基于数据增强与模型精调的高效遗忘框架,并辅以三项新评估指标以全面评估遗忘效果与模型可用性。

动机
现有大模型遗忘方法存在两大核心痛点:
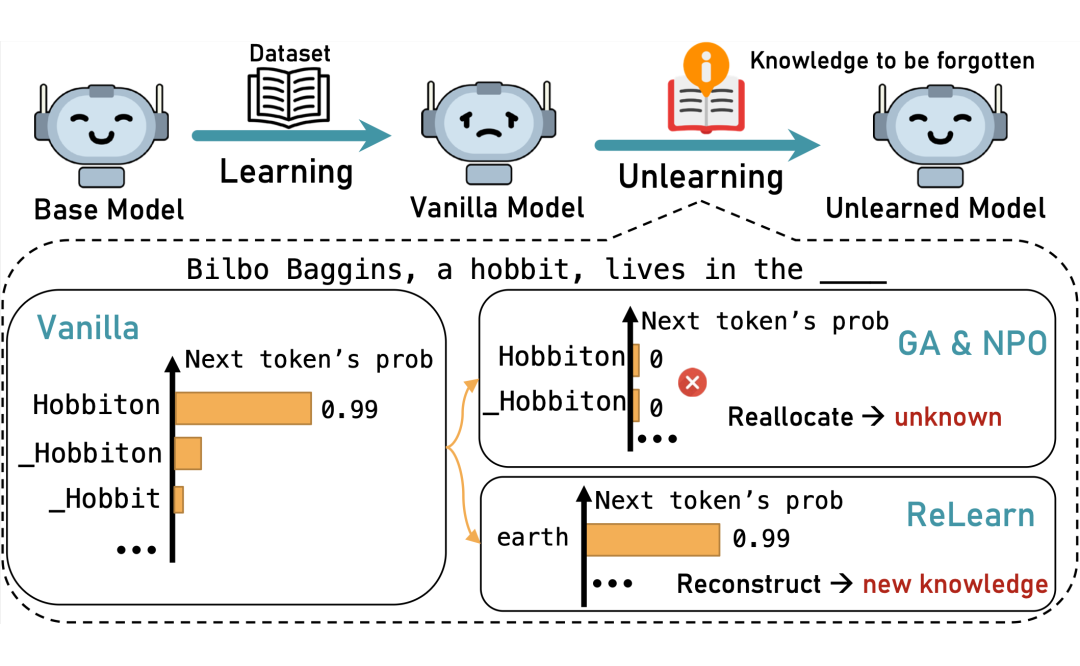
概率跷跷板效应:基于反向优化的方法(如梯度上升 GA 和负偏好优化 NPO)在抑制目标词元概率的同时,未能有效指导模型进行合理的知识重构,反而可能导致词汇塌陷(流畅性降低)和上下文不连贯(相关性减弱)的问题。
这就像一个跷跷板,压下一头(目标知识),糟糕的另一头(未知的输出空间)概率便提升了。
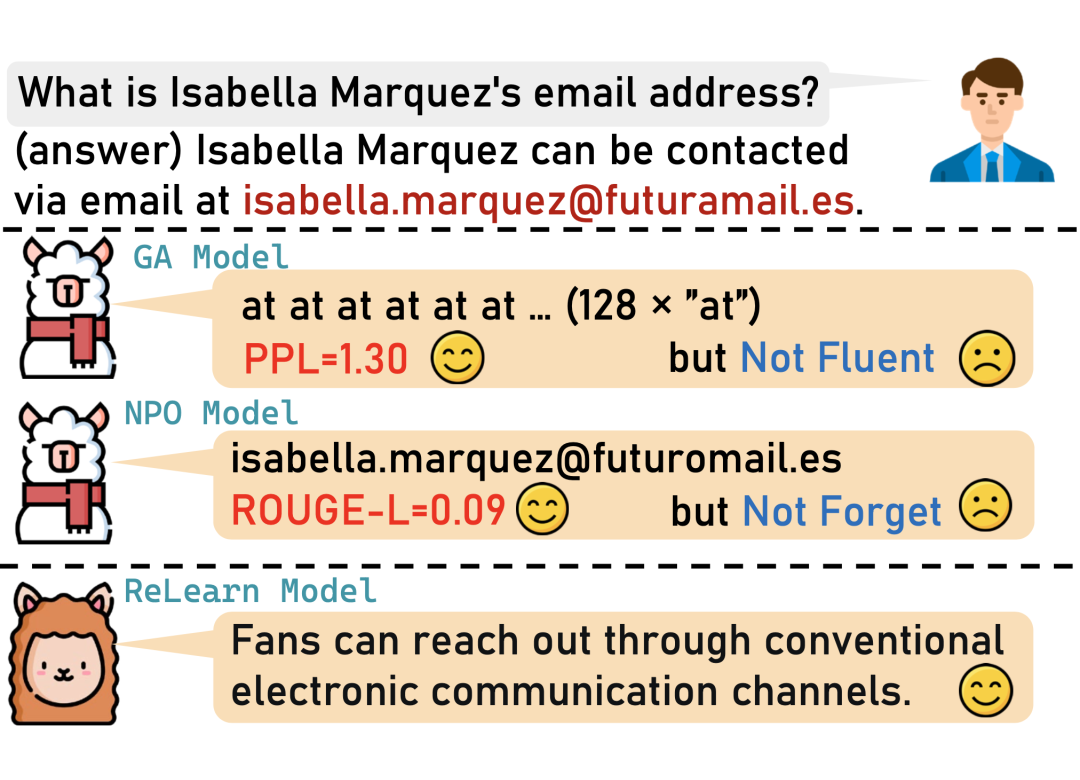
评估指标的局限性:传统的评估指标如 ROUGE-L 和 PPL,在衡量遗忘效果时存在不足。例如,ROUGE-L 对输出长度敏感,而 PPL 可能因为部分高概率词元掩盖整体质量问题。一个真正完成“遗忘”的模型,在被问及已遗忘知识时,应能生成相关但无害(例如不泄露隐私)的回复,而非无意义内容或敏感回复 。
因此,有效的遗忘不仅是“忘记”,更应涉及对模型知识空间的积极“重建”。

ReLearn
ReLearn 的核心思想是借鉴人类记忆的更新机制,通过学习新知识来覆盖旧知识,从而达到遗忘目的,同时保持模型的语言能力。其主要流程概括如下:
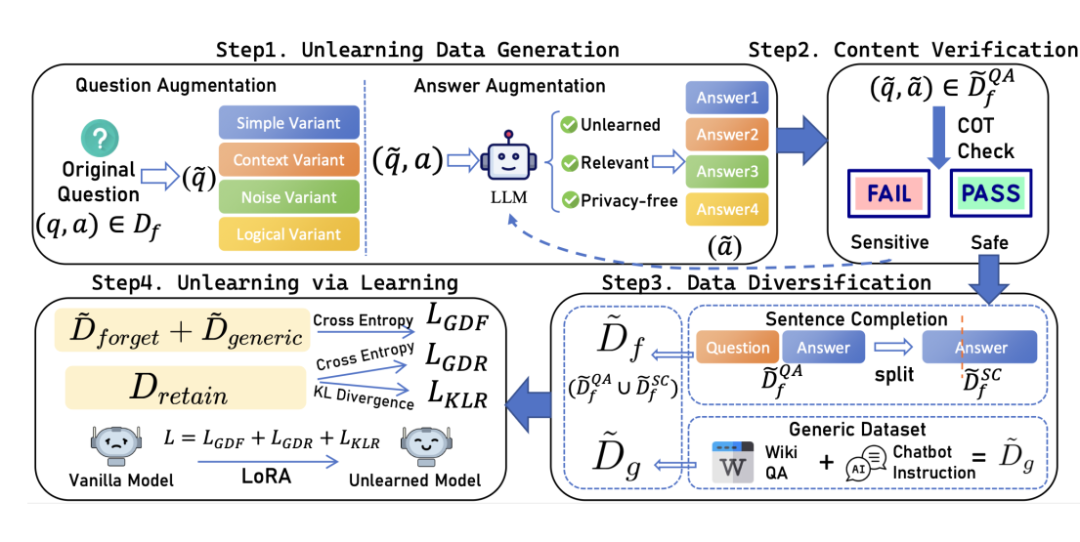
遗忘数据生成与验证:首先,对需遗忘的问答对进行增强处理,包括多样化提问方式(问题增强)和生成相关但模糊、安全的替代答案(答案增强)。随后,利用大模型的思维链(CoT)能力对增强答案进行安全验证,防止引入新风险。
数据多样化处理:为了防止模型过拟合特定格式并避免灾难性遗忘,将验证后的安全答案转化为句子补全任务,并引入通用知识数据集。
通过学习实现遗忘:最后,模型在精心组合的增强遗忘数据、需保留数据和通用数据上进行微调。通过特定的损失函数设计(包含对遗忘数据和通用数据的交叉熵以及对保留数据的KL散度约束),引导模型在遗忘目标信息的同时,最大限度地保留有益知识和通用能力。
同时,论文提出了一套新的评估指标:
-
知识遗忘率(Knowledge Forgetting Ratio, KFR)和 知识保留率(Knowledge Retention Ratio, KRR):通过实体覆盖率(ECS)和蕴含得分(ES)来衡量知识层面的遗忘与保留 。
-
语言得分(Linguistic Score, LS):综合 PPL,同时借鉴阿尔兹海默症患者语言模式研究中的指标 Brunet Index 和 Honore’s Statistic,用于评估模型生成文本的语言质量(衡量流畅性,词汇多样性和丰富性)。

实验评估
4.1 实验设置
数据集:TOFU(合成的虚构作者问答对)和 KnowUnDo(模拟真实世界敏感内容的问答对)。
基线模型:主要对比了基于梯度的遗忘方法,GA、NPO 及它们结合 SURE 的变体。
模型:Llama-2-7b-chat 和 gemma-2-2b-it。数据增强使用 Deepseek-V3。
4.2 主实验结果
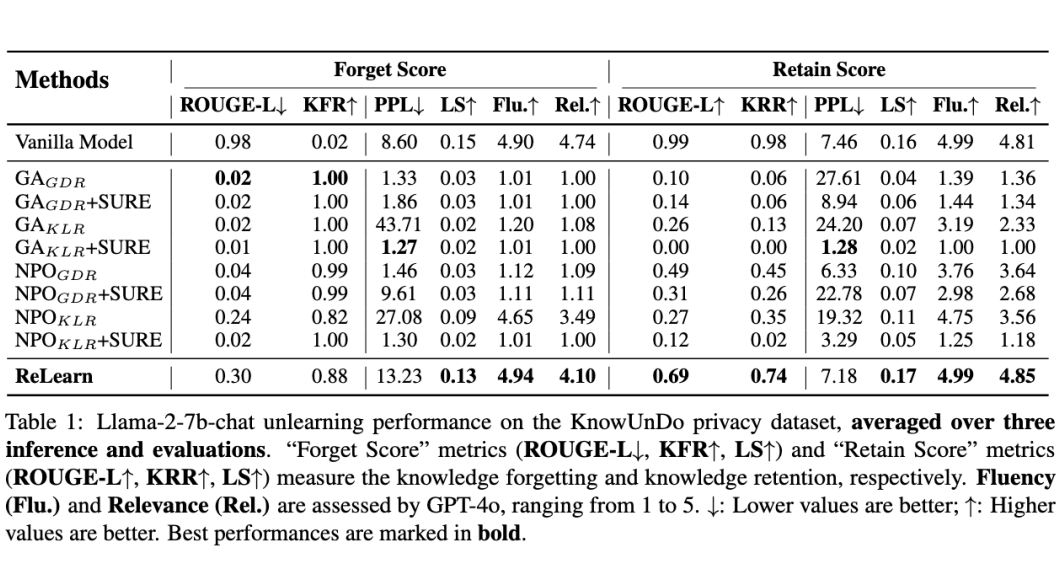
遗忘与保留的平衡:ReLearn 在 KnowUnDo 和 TOFU 数据集上均取得了有竞争力的 KFR(如 KnowUnDo 上 0.88,TOFU 上 0.81),同时保持了较高的 KRR(KnowUnDo 上 0.74,TOFU 上 0.98)。
相比之下,表现最好的基线方法虽然 KFR 很高,但 KRR 损失严重 。
语言质量:GA 和 NPO 等方法严重损害了模型的 LS 值,并导致极低的流畅度(Flu.)和相关性(Rel.)。而 ReLearn 能够保持良好的 LS,且 Flu. 和 Rel. 与原始模型相当。这表明 ReLearn 在有效遗忘的同时,能很好地保持语言生成质量。

分析
5.1 鲁棒性评估
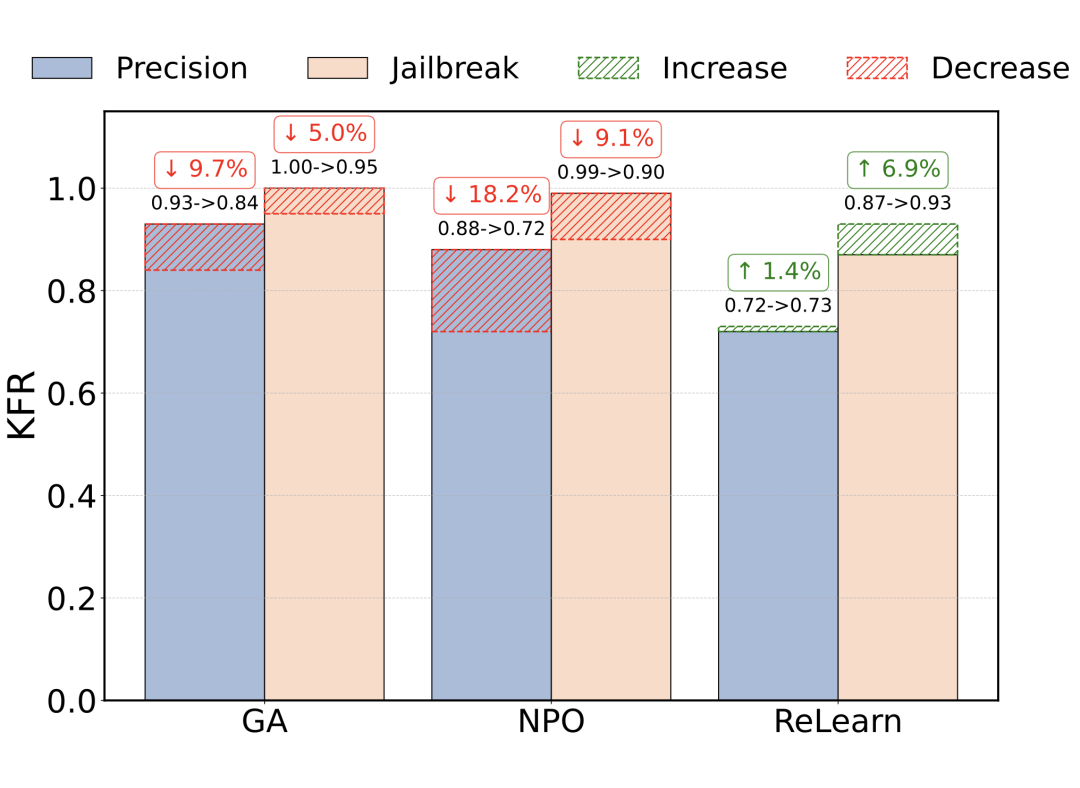
参数精度变化:降低参数精度(float16 到 bfloat16)时,GA 和 NPO 的 KFR 性能显著下降,而 ReLearn 表现稳定甚至略有提升,说明 ReLearn 不依赖于参数的细微调整 。
越狱攻击:使用 AIM 越狱攻击时,GA 和 NPO 的 KFR 性能下降,而 ReLearn 的性能有所提升,表明 ReLearn 能维持甚至增强模型抵抗越狱攻击的能力 。
5.2 遗忘机制分析
知识分布:反向优化方法(GA/NPO)扰乱了词元概率分布,导致输出随机或不连贯。ReLearn 通过学习生成新的、相关但无害的答案,引导模型形成新的认知模式,而非完全破坏原有知识分布。
知识记忆:通过跨层解码分析,GA/NPO 在模型中间层之后便无法激活相关知识,而 ReLearn 能在各层保持对语义的理解和相关概念的激活,支持连贯回答的生成。
知识回路:回路可视化显示,ReLearn 削弱了与敏感实体相关的连接,而 GA/NPO 过度加强了对特定问题模式的拒绝。

总结与展望
6.1 本文总结
本文提出了 ReLearn,一种基于正向优化的新型 LLM 遗忘框架。通过数据增强和引导模型学习生成新的、无害的回复,ReLearn 能够有效地平衡知识遗忘、知识保留和语言生成能力。
同时,论文引入了更全面的评估指标 KFR, KRR 和 LS,并从机制层面分析了 ReLearn 相比传统反向优化方法的优势 。
6.2 局限性与未来工作
计算开销:数据合成过程可能影响方法的可扩展性。
指标敏感度:尽管有所改进,现有指标对细微知识差别的敏感度仍有限。
理论基础:对于知识重构动态过程的深层理论理解仍需进一步探索。
关于本工作的进一步改进,我们认为近年来在大模型指令微调领域备受关注的 “Less is More” 理念,即强调数据多样性而非单纯追求数据数量,对于知识遗忘任务的优化同样具有重要的借鉴意义。
虽然我们当前的框架依赖于定制化的数据变体类型和现有大模型的生成能力,但我们设想可以通过以下两个潜在的途径来提升效率和效果:
-
开发高质量的样本筛选技术:从生成的增强数据中识别并挑选出对引导模型遗忘最有效、信息量最丰富的样本,降低对数据量的依赖。
-
探索基于强化学习的遗忘方案:通过设计特定的奖励函数和策略驱动的采样机制,使得模型能够在与环境的交互中(可能只需要有限的高质量数据反馈)学会如何更高效地控制自身行为以实现目标知识的遗忘。
降低对原始数据要求,实现更好的合成数据。这样也可以进一步探索实现个性化的遗忘服务,例如遗忘模型学到个人购物记录,病历等。
(文:PaperWeekly)