
在技术演示中,LLMs几乎无所不能——写代码、查资料、做总结、讲笑话……然而,一旦我们进入真实使用场景,尤其是“多轮对话”时,就会发现它们常常表现出意料之外的混乱:
-
明明第一轮还回答得头头是道,到了第三轮突然胡说八道;
-
一旦用户前后表达不一致,模型往往无法自行修正,而是“沿着错误方向越走越远”;
-
有时候,甚至你只是在逐步补充需求,它却早早下了结论、给了答案,而且错得离谱。
这些现象,并不是错觉。
最新发布的论文《LLMs Get Lost in Multi-Turn Conversation》系统揭示了这个问题:多轮对话中的性能崩塌,是当前最强LLMs无法回避的结构性挑战。

现实中,大多数人不会在第一句话就清晰、完整地说出自己的需求。比如:
-
“我想找一份餐厅推荐”;
-
“帮我生成一段数据可视化代码”;
-
“这段文本帮我总结下”。
这些初始请求,往往是欠规格的(underspecified),需要多轮互动来补充关键信息,比如菜系、预算、可视化维度、目标摘要长度等。
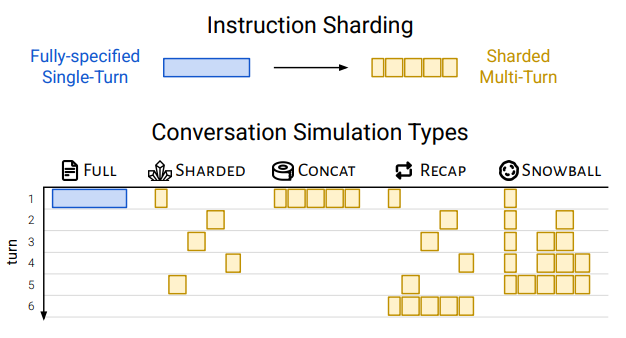
为了模拟这种真实场景,研究者提出了一种名为“分片(Sharding)”的实验方法:
把完整任务拆成多个“信息碎片”,每轮对话只暴露一个碎片,逐轮补齐需求,让LLM逐步接收任务信息,模拟真实用户与助手互动过程。
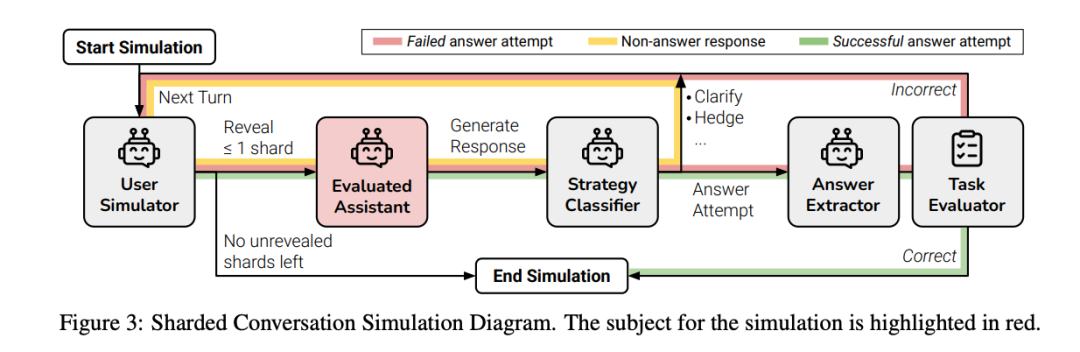
基于这个框架,研究者对15个主流大模型进行了超过20万轮的模拟实验,涵盖代码生成、数学解题、SQL查询、API调用、数据转文本、文档摘要六大类任务,几乎覆盖所有典型的LLM应用场景。

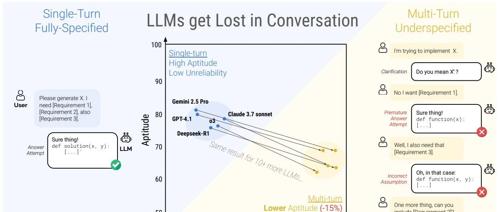
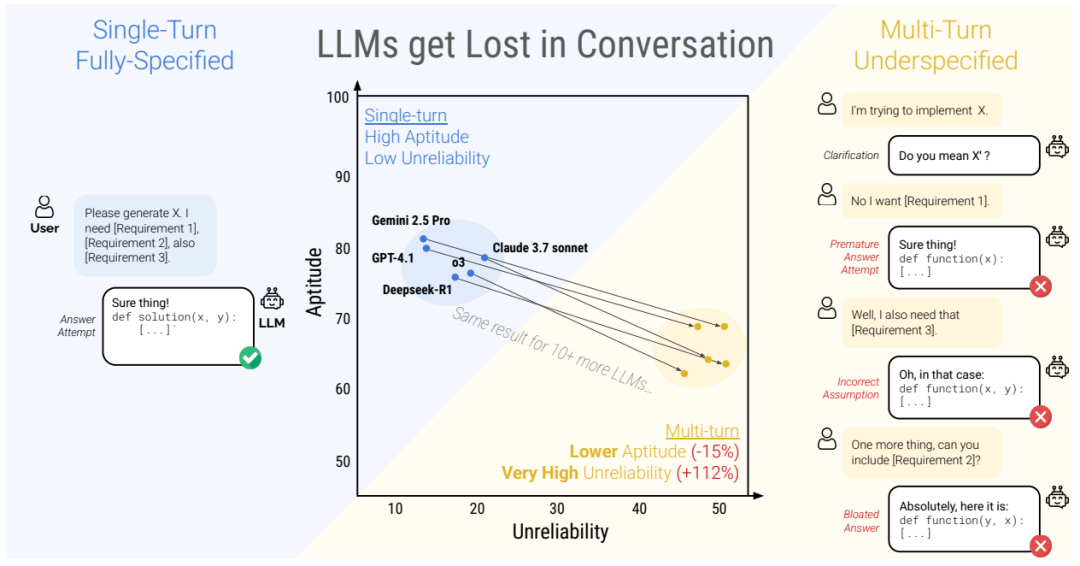
然而结果令人震惊:所有模型在多轮交互下性能普遍暴跌,即使只是两轮交互,准确率也从单轮场景中的90%以上骤降到约60%,平均降幅高达39%。表现最好的模型也未能幸免,多轮任务成为所有大模型的“共同软肋”。
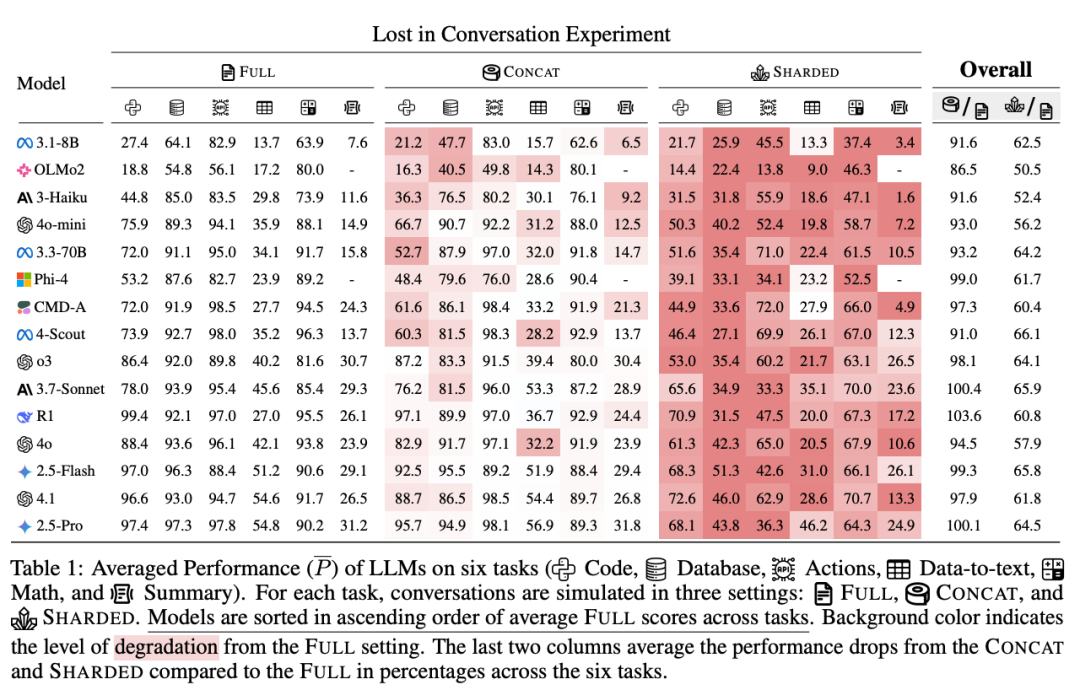
那么,问题究竟出在哪?论文深入分析后指出,性能下降的关键不在于模型“能力”退化,而在于“可靠性”崩溃。在单轮任务中,模型的回答表现稳定、可信,但在多轮交互下,回答结果波动剧烈,最佳与最差之间的表现差距拉大112%。
换句话说,模型并非变笨,而是变得情绪化、不可预测。这种不稳定的表现意味着同一个问题,在不同对话历史背景下可能得到完全不同、甚至自相矛盾的回答,极大损害了用户体验和任务成功率。
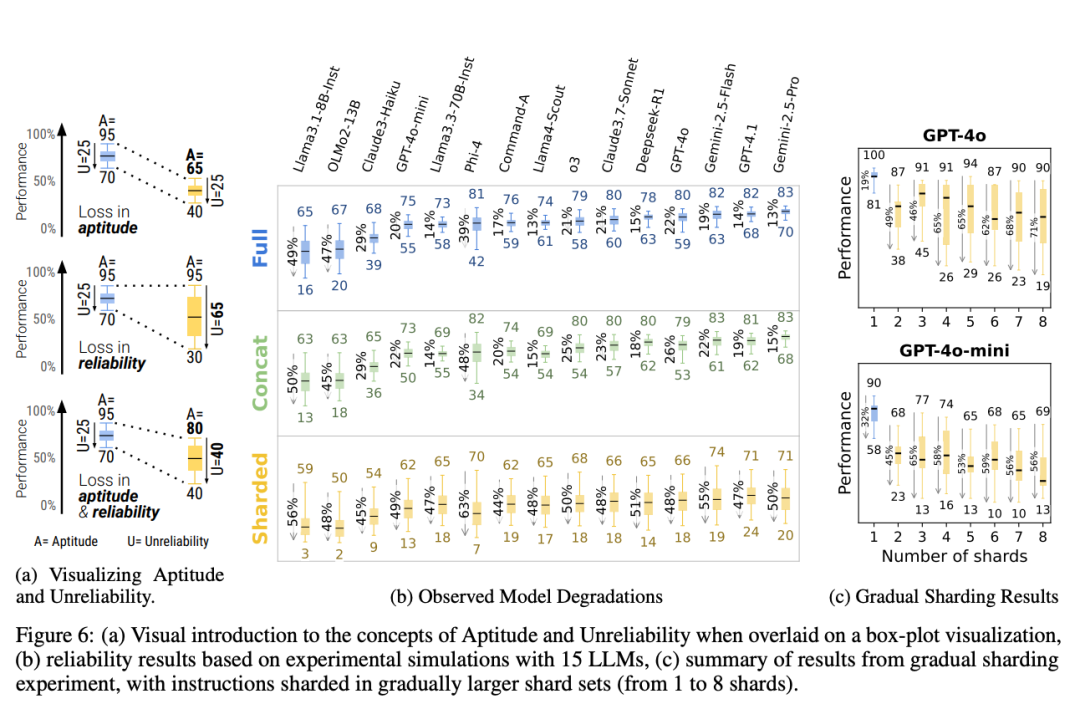
具体来说,这种“迷失”主要表现为几个方面。

首先,模型经常在用户尚未给出所有关键信息时,就急于做出判断,提前下结论。这种“预判式回答”容易造成答案脱离用户真实意图,难以纠正。
其次,回答内容越来越“肥大”,模型倾向于在每轮中加入大量臆测信息,回答变得冗长、混乱、缺乏重点,反而遮蔽了关键细节。
第三个现象是“中间轮遗忘”:模型更关注对话的开头和结尾,而对中间信息处理不够敏感,导致上下文理解断裂。
更严重的是,模型还会过度依赖前几轮生成的内容,即便这些内容是错误的,也不加修正,甚至“滚雪球式”堆叠错误,越聊越偏离正轨。这种上下文污染和连锁反应,让原本简单的问题也变得无比复杂,最终无法给出可执行的输出。
面对如此严峻的挑战,研究者尝试了一些补救方案,比如在每一轮都重复前几轮的用户输入(滚雪球式提示词拼接)、降低生成温度以提高确定性,甚至借助额外的推理型模型。但这些方法的缓解效果都十分有限。哪怕设置温度为0,让模型尽可能“稳定发挥”,仍无法阻止其在多轮对话中的滑坡。换句话说,问题出在对话流程本身,光靠修修补补是无解的。
论文进一步指出,这种“迷失”并非个别模型或个别任务的特例,而是一种跨任务、跨模型、跨厂商的普遍性问题。
不管是OpenAI的GPT、Anthropic的Claude,还是谷歌的Gemini、微软支持的DeepSeek,这一现象在所有主流LLM中都如影随形。唯一的例外,是像翻译这种任务目标高度清晰、上下文需求不强的情况。
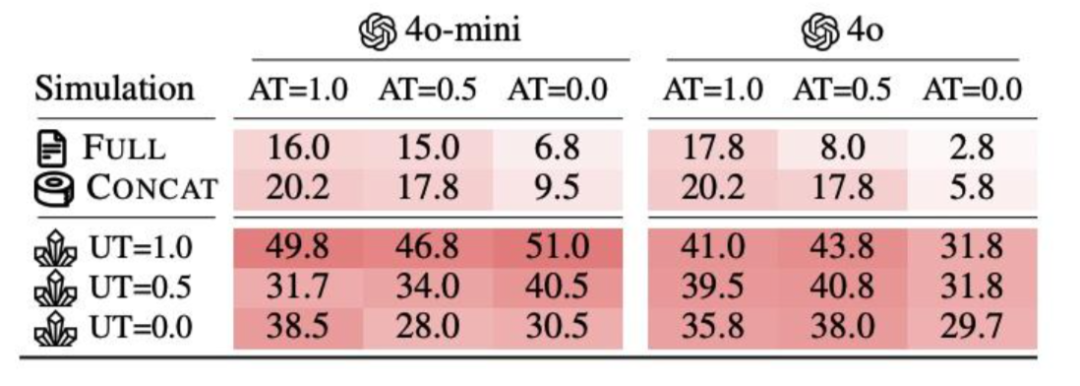
而对于需要逐步澄清、聚焦、构建推理链条的任务类型来说,多轮对话几乎成了模型表现不可靠的代名词。
这种发现对业界提出了深刻警示。对于系统开发者而言,不能只关注模型在标准化单轮测试集上的表现,而要重点评估其在不完整输入、多轮澄清下的交互能力。
一个真正实用的对话系统,必须具备在模糊场景下主动提问、动态澄清、灵活调整策略的能力,而不是被动等待完整命令。对于模型训练者而言,当前大多数训练数据仍然是单轮为主,缺乏多轮对话任务的真实模拟,急需构建更贴近实际交互的数据集,并在优化目标中显式纳入“多轮一致性”指标。
对NLP研究者来说,这篇论文提供了一个全新的研究方向——如何让模型不仅能“记住”前文,更要“理解”多轮上下文中的信息增量。现有的记忆机制、上下文窗口技术、长文本建模方式尚未能解决“中间遗忘”和“错误传染”的结构性问题。多轮对话并不是简单的拼接记忆,而是需要精准的状态管理与语义对齐。
对于终端用户而言,这项研究同样提供了现实建议。在与AI对话时,尽可能一次性清晰表达需求,能有效避免模型误判和错误堆叠的风险。如果需求较复杂,重启新对话往往比沿着旧对话修修补补更为有效。避免让模型陷入纠错与假设循环,是提升交互体验的重要技巧。
当然,这篇研究也存在一些局限。实验主要基于模拟用户进行自动化交互,缺乏人类在真实交流中展现出的策略调整、语气变化等复杂行为,可能低估了多轮对话场景的复杂性。
同时,论文聚焦于结构化任务,并未涵盖诸如创意写作、闲聊、观点辩论等开放型任务场景。此外,实验目前仅限英文语境,尚未探索中文或多语言、多模态下的多轮对话表现,这些都是未来值得深入拓展的方向。
总结来看,这篇论文不仅揭示了一个重要事实:大模型尚未具备真正可靠的多轮交互能力,更为整个行业敲响了警钟。
在热潮之下,我们亟需回归对“交互”本质的理解,从追求任务完成率转向追求交流质量,推动模型从一次性回应工具向长期互动伙伴演进。而这场从“答题器”到“合作者”的转型,才刚刚开始。
https://arxiv.org/pdf/2505.06120
📊 数据集地址:
https://huggingface.co/datasets/microsoft/lost_in_conversation
📣 点赞+转发,让更多人看到AI“最强短板”!
关注 [AI技术研习社],一起深挖前沿研究、掌握AI时代的关键技能!
(文:AI技术研习社)