

Laser团队 投稿
量子位 | 公众号 QbitAI
1+1等于几?
现在的大推理模型(LRMs)已经展现出了非凡的推理能力。但是面对这样最简单的数学问题,现有的LRMs仍需要花费1400+的tokens来思考。
那么有办法让LRMs在推理思考时更快更强吗?
来自港科大、港城、滑铁卢大学和Apple的研究人员,最近提出了Laser系列新方法,实现了更好的模型效率和准确率平衡,做到了两者的共同显著提升。

经过Laser和它的进阶方法Laser-D、Laser-DE训练后的模型,相较于训练前模型或者其他方法训练的模型,在准确率(Accuracy)和Tokens使用效率(Efficiency)上,同时取得了显著的提升。
例如在知名复杂数学推理基准AIME24上,Laser-D和Laser-DE方法能够让模型在减少Tokens使用量63%的情况下,还继续提升6.1的性能。
同时,研究人员还发现,经过训练的模型的思考过程里,冗余的“self-reflection”的比例大大降低,呈现出了一种更加健康的思考模式。

这一研究也在𝕏引起了讨论:

那么,Laser是如何让大模型推理又快又好的呢?
三大创新实现性能-效率双赢
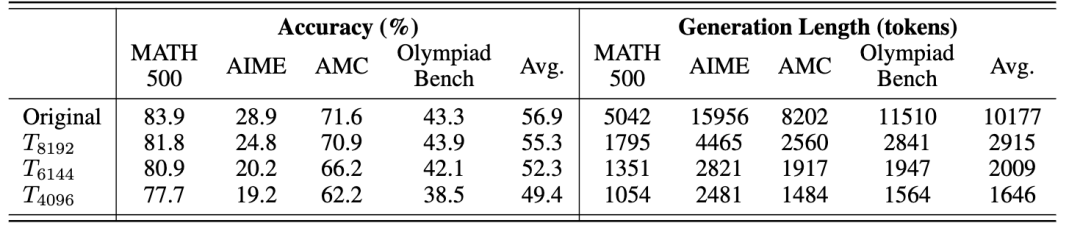
Laser的研究人员首先发现,仅仅通过在强化学习过程中,对模型输出长度进行截断,就可以让训练后的模型的推理效率大幅提升。
但这种方式,只能带来效率的提升,对于模型推理的准确性仍然有不小的损害。
这意味着,推理的准确性和效率其实是一个平衡问题(Trade-off),用更多的Tokens经常能取得更高的准确率,反之可能准确率就会受到损害。
所以不应该仅仅关注某一指标,而应该将两者一同考虑,将问题的重点放在如何提升它们之间的平衡上面。
Laser主要通过以下三点创新来平衡效率和准确率,以做到双提升:
1、统一视角:提出了一套统一的框架来看待各类基于长度的奖励设计(Length-based Reward),并且将训练时截断这一简单方法也统一进了这一套框架内。
2、Laser(Length-bAsed StEp Reward):基于这一个统一框架,研究人员提出一种全新的基于目标长度和阶跃函数(Step Function)的奖励设计,规避了之前奖励设计存在的一些问题。
3、动态且带有难度感知的Laser-D、Laser-DE方法:进一步的,研究人员提出了一套自动适配机制,来匹配不同难度下,不同题目的最优目标长度,让Laser达到最优的平衡。
下面分别详细展开下。
统一视角看待不同奖励设计
研究人员首先将直接截断训练的方法和先前不同的长度奖励设计联系起来,统一成了一套统一的奖励设计框架。
具体而言,所有的这些方法,都可以看做是正确性的奖励C(x)、基于长度的奖励S(x),以及一个控制开关λ(y)的组合。

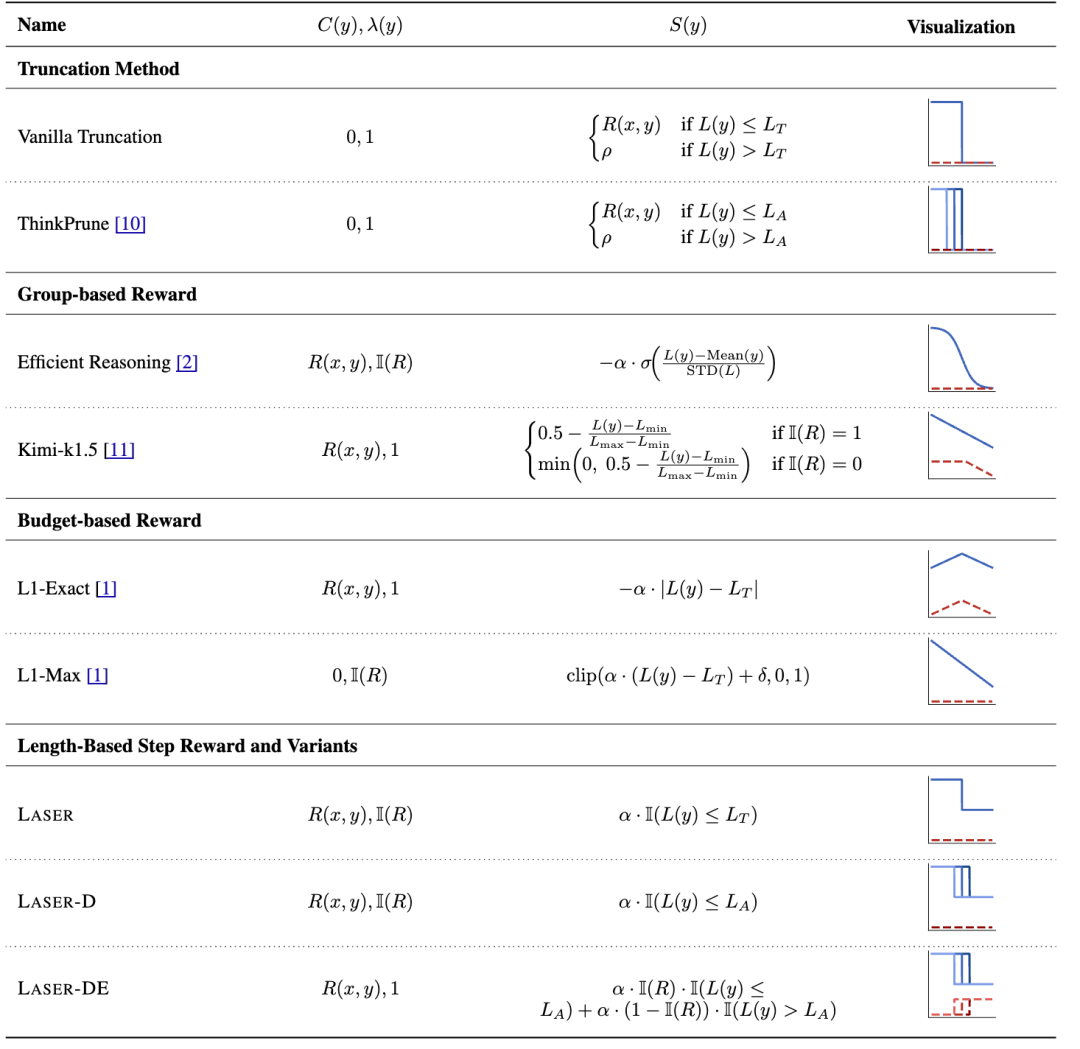
表中最右侧的可视化图片,展示了不同的方法对应的奖励函数的不同形状,其中蓝线代表正确的回复对应的奖励函数,红线代表错误的回复对应的奖励函数。
从图上可以看到,训练时直接截断的方法,有一个很大的问题在于,当模型产生的回复很长的时候,正确回复和错误回复的奖励会杂糅在一起,使得模型无法正确区分回复的正确性,影响对对应数据的学习。
Laser:基于目标长度和阶跃函数的奖励设计
为了解决训练截断中“无法区分正确但冗长的回答”这一问题,研究人员提出了Laser奖励函数。
Laser不再“惩罚”所有长回答,而是对在目标长度以内生成的正确回答给予额外的正向奖励。
这种阶跃函数(Step Function)形式的奖励机制,既鼓励简洁,也保留了对准确推理的认可,有效提升了准确率与效率的整体平衡。
动态且带有难度感知的LASER-D / LASER-DE方法
在进一步提升准确率与效率的平衡性上,研究人员提出了LASER-D方法:
通过引入动态调整目标长度与题目难度感知机制,模型在训练过程中可以根据题目的难易程度,自适应设定更合适的token使用上限。
这一机制通过监控模型在不同难度题目上的生成表现,动态评估不同难度题目的最优目标长度。
具体来说,这一机制会定期使用一个小规模的监控集,对不同长度设定下的“预期正确回答数量”进行估算,并据此动态更新易/中/难三类题目的目标长度,几乎不增加训练开销,却显著提升了训练时奖励函数的灵活性与适应性。
此外,他们还提出了LASER-DE。即在模型答错时,鼓励模型在更长长度上进行探索,尝试纠正错误、发现更优的推理路径,从而提升在困难题目上的表现。
这一系列改进让LASER系列方法在多个benchmark上,实现了更优的性能-效率双赢效果。
实验效果
研究人员用DeepSeek-R1-Distill-Qwen的1.5B / 7B / 32B三个不同规模的模型,在MATH500、AIME24、AMC23、Olympiad Bench上进行了广泛实验。
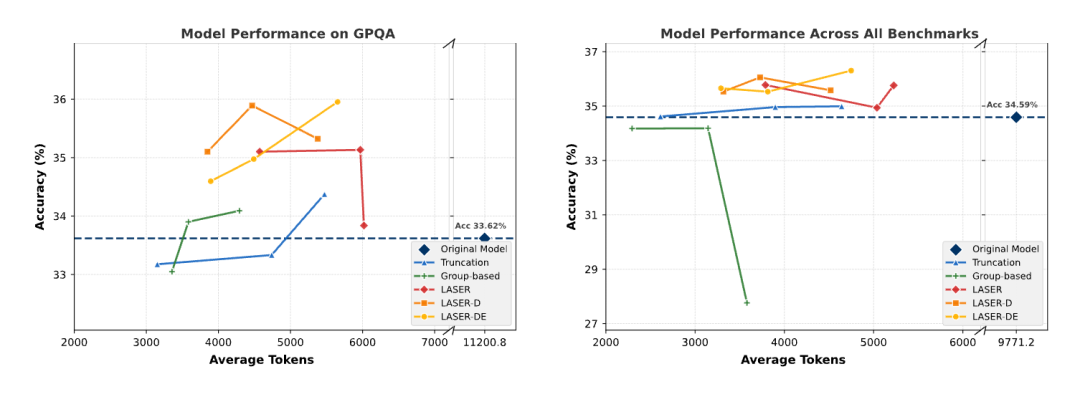
首先,他们通过调整各个方法在训练中的关键参数,绘制出不同方法在准确率(Accuracy)与token使用量(Efficiency)上的帕累托(Pareto)前沿。
如图所示,在AIME2024和所有Benchmarks的平均上,原始模型(蓝色虚线)在token使用上代价巨大。
而其他baselines方法虽然在效率上有所提升,但准确率下降明显。
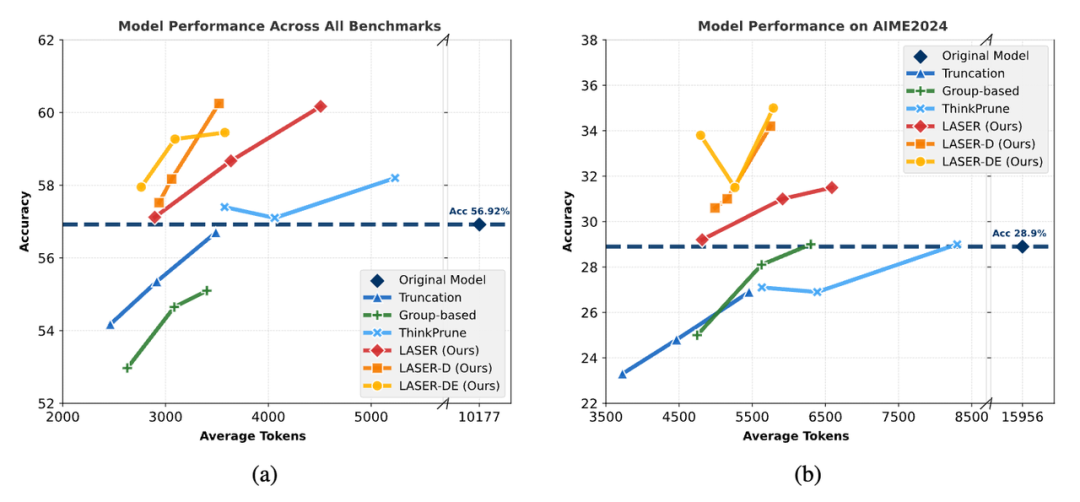
相比之下,LASER、LASER-D和LASER-DE(橙红色)始终位于原模型的准确率之上——
在显著减少Tokens使用的同时,准确率还明显高于baseline,展现出强大的推理性能和推理效率双提升。
特别是在AIME2024上,LASER-D在只使用原始模型1/3 Tokens的情况下,就能取得+6.1的准确率提升,证明其在复杂数学推理任务中的强大效果。
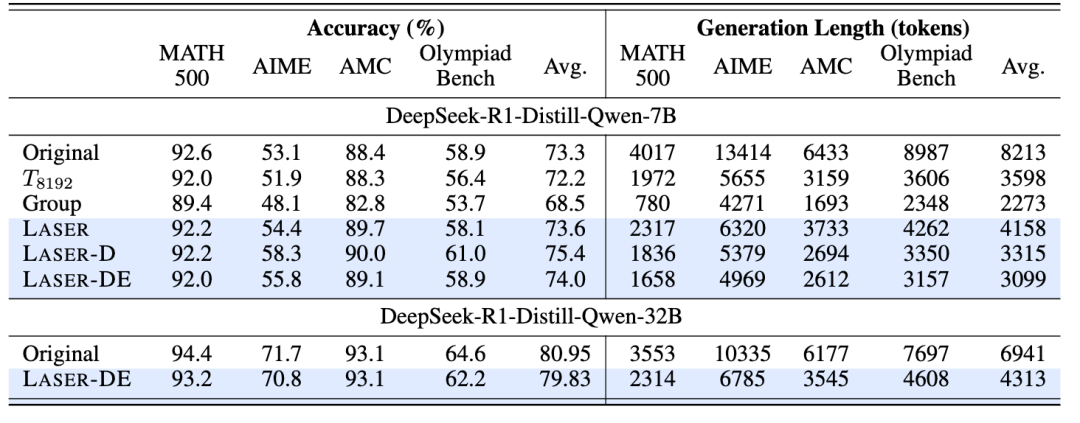
在7B和32B模型上,LASER-D和LASER-DE相较于其他方法,在准确率和token使用效率上都取得了更优表现。
DeepSeek-R1-Distill-Qwen-7B模型上,例如对于AIME24,LASER-D在7B模型上,在提升5.1的准确率的同时,平均token使用量还能降低60%,再次实现效率准确率双提升。
研究人员还在多个领域外(OOD)测试集(GPQA、LSAT、MMLU)上对他们的方法进行了验证。
实验结果表明,在OOD测试集上,LASER、LASER-D和LASER-DE取得良好的泛化,同样取得了最优的准确率与效率平衡,实现了准确率效率双提升。
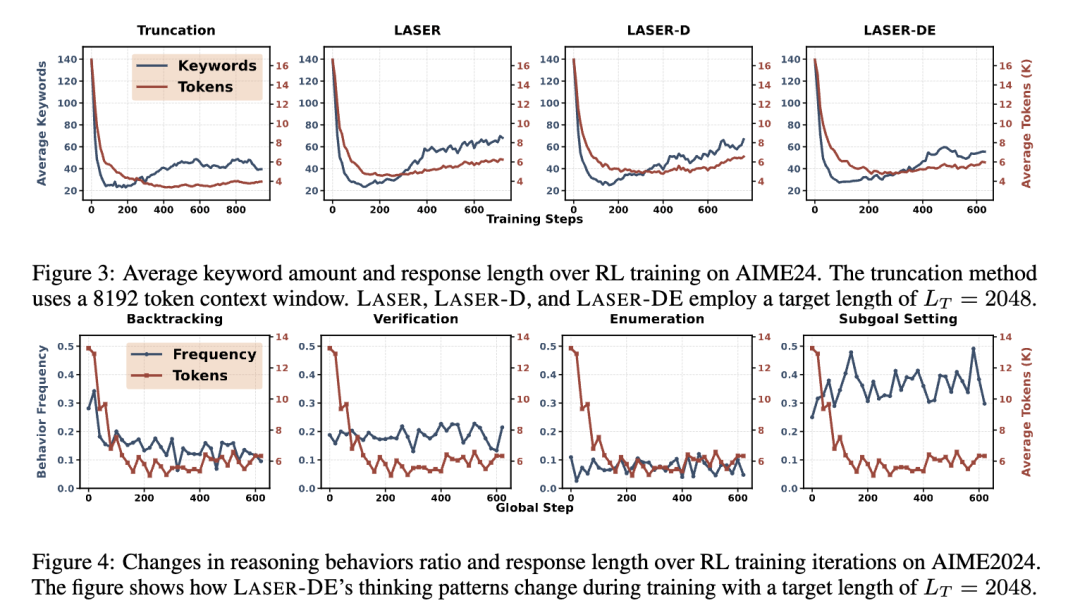
行为分析
为了进一步理解LASER系列方法为何能在保持准确性的同时大幅压缩token使用,研究人员对模型推理行为的变化进行了分析。
结果显示,经过LASER训练后,模型生成中冗余的Backtracking(反复自我否定)显著减少,而Verification(验证)、Subgoal Setting(子目标拆解)等关键推理行为得以保留甚至增强。
这表明LASER不仅压缩了长度,还引导模型学会了更简洁、结构更清晰的思考方式。
这也与文章开头展示的 “1+1等于几” 的案例相呼应——
训练后的模型不再陷入反复的self-reflections,而是能直接识别出问题的关键,做出高效、准确的回应。
团队表示,他们相信“能够准确且精简地表达”是高级智能的重要体现。
真正强大的模型,应在准确性与简洁性之间实现良好平衡,而非只追求其中任何一者。
LASER系列方法正是朝这一目标迈出的关键一步,它不仅压缩了推理长度,更提升了推理质量。
团队也表示,未来将继续探索更灵活、更通用的方法,进一步推高模型的这一高级智能的能力。
论文: https://arxiv.org/abs/2505.15612
GitHub仓库: https://github.com/hkust-nlp/Laser
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!
— 完 —

🌟 点亮星标 🌟
(文:量子位)