
ml-diffucoder:探索和改进用于代码生成的掩码扩散模型

ml-diffucoder提出耦合采样方案提升扩散模型效率,并引入自回归性评分量化生成过程中的因果模式,探讨扩散模型在代码任务的独特表现。
ml-diffucoder提出耦合采样方案提升扩散模型效率,并引入自回归性评分量化生成过程中的因果模式,探讨扩散模型在代码任务的独特表现。

科技巨头通过开源策略争夺人形机器人生态主导权。中国凭借制造业基础和政策支持优势可能领先。到2050年全球人形机器人市场收入预计可达5万亿美元。

上周苹果因发布关于推理大模型的研究观点而引起巨大讨论:尽管LRMs具备复杂自我反思机制,但超出一定阈值时仍会完全崩溃。反驳声音不断,苹果通过论文驳斥:这些失败更多是由于实验设计选择而非模型本身局限性。

和视频生成模型
Seedance 1.0 pro
,支持 256K 上下文,综合成本下降 63%,视

上周苹果因发布关于推理大模型的研究观点而引起巨大讨论:尽管LRMs具备复杂自我反思机制,但在问题复杂性超过一定阈值时会完全崩溃。苹果反驳称实验设计选择而非模型本身局限性导致失败。
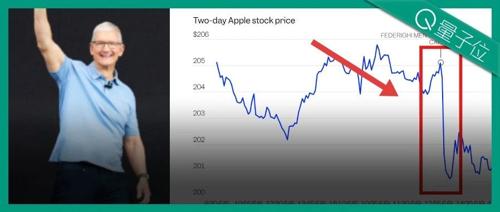
苹果WWDC大会因Siri更新推迟引发股价暴跌750亿美元。发布会聚焦液态玻璃设计、全系操作系统功能更新及AI能力的集成,但开发者反馈冷淡。苹果强调AI战略地位,但仍面临与OpenAI合作等挑战。

Laser团队提出的新方法提升了大模型的推理效率与准确性,通过统一视角看待不同奖励设计、基于目标长度和阶跃函数的奖励机制以及动态且带有难度感知的目标调整,实现了在减少Tokens使用量的同时保持或提升准确率。

Apple and Anthropic reportedly are collaborating on an AI coding platform for internal use, leveraging Anthropic’s Claude model to enhance iPhone development.

