

人类天生通过将视觉和听觉联系起来进行学习。例如,我们可以观看某人演奏大提琴,并认识到演奏者的动作产生了我们听到的音乐。

麻省理工学院(MIT)和其他机构的研究人员开发出一种新方法,提高了人工智能模型以这种方式学习的能力。这种方法在新闻和电影制作等领域可能非常有用,模型可以通过自动检索视频和音频来帮助策划多模态内容。
从长远来看,这项工作可用于提高机器人对现实世界环境的理解能力,因为在现实世界中,听觉和视觉信息通常密切相关。
研究人员改进了他们团队之前的工作,创建了一种方法,帮助机器学习模型在不需要人工标签的情况下,对齐视频片段中的相应音频和视觉数据。
他们调整了原始模型的训练方式,使其能够学习特定视频帧与那一刻发生的音频之间的更细致的对应关系。研究人员还对系统架构进行了一些调整,帮助系统平衡两个不同的学习目标,从而提高性能。
这些相对简单的改进综合起来,提高了他们在视频检索任务中以及对音视频场景中动作进行分类的准确性。例如,新方法可以自动且精确地将视频片段中门砰的一声与门关闭的视觉画面匹配起来。
“我们正在构建能够像人类一样处理世界的 AI 系统,即同时接收音频和视觉信息,并能够无缝处理这两种模态。展望未来,如果我们能将这种音视频技术整合到我们日常使用的工具中,比如大型语言模型,那么可能会开辟许多新的应用场景。”
麻省理工学院研究生、该研究论文的共同作者安德鲁·鲁迪琴科(Andrew Rouditchenko)说。
论文的作者还包括第一作者埃德森·阿拉乌霍(Edson Araujo),他是德国歌德大学的研究生;前麻省理工学院博士后研究员袁功(Yuan Gong);现任麻省理工学院博士后研究员索拉布奇·巴提(Saurabhchand Bhati);IBM 研究院的萨缪尔·托马斯(Samuel Thomas)、布莱恩·金斯伯里(Brian Kingsbury)和列昂尼德·卡尔林斯基(Leonid Karlinsky);麻省理工学院 – IBM 沃森人工智能实验室的首席科学家兼经理罗杰里奥·费里斯(Rogerio Feris);麻省理工学院计算机科学与人工智能实验室(CSAIL)语音语言系统组的高级研究科学家、组长詹姆斯·格拉斯(James Glass);以及高级作者、歌德大学计算机科学教授、麻省理工学院 – IBM 沃森人工智能实验室的附属教授希尔德·库恩(Hilde Kuehne)。这项工作将在计算机视觉与模式识别会议上展示。
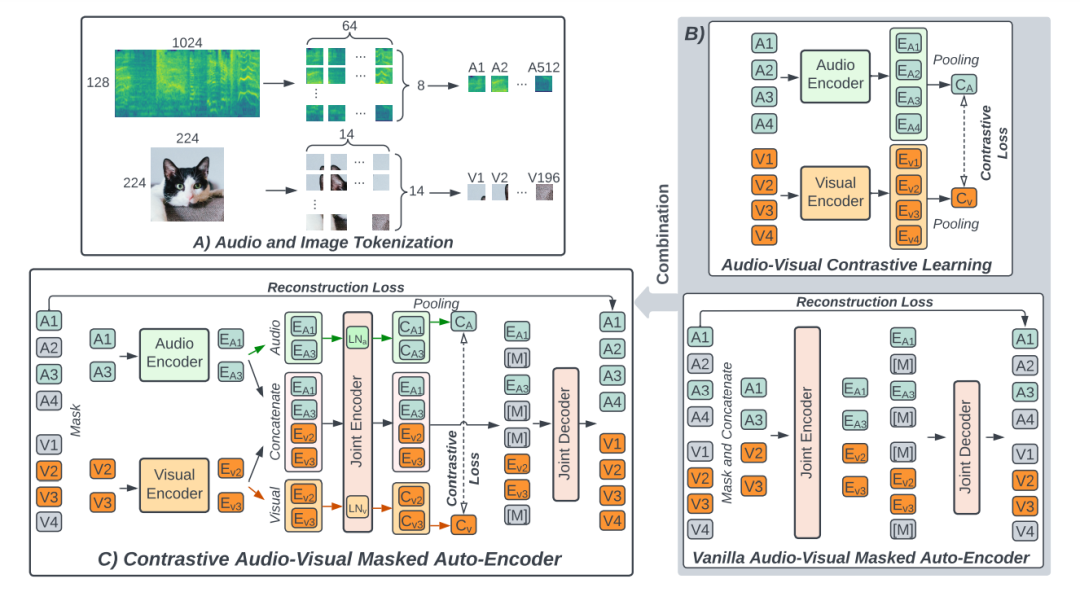
这项工作是在研究人员几年前开发的一种机器学习方法的基础上进行的,该方法提供了一种高效的方式,用于训练多模态模型,使其能够在不需要人工标签的情况下同时处理音频和视觉数据。
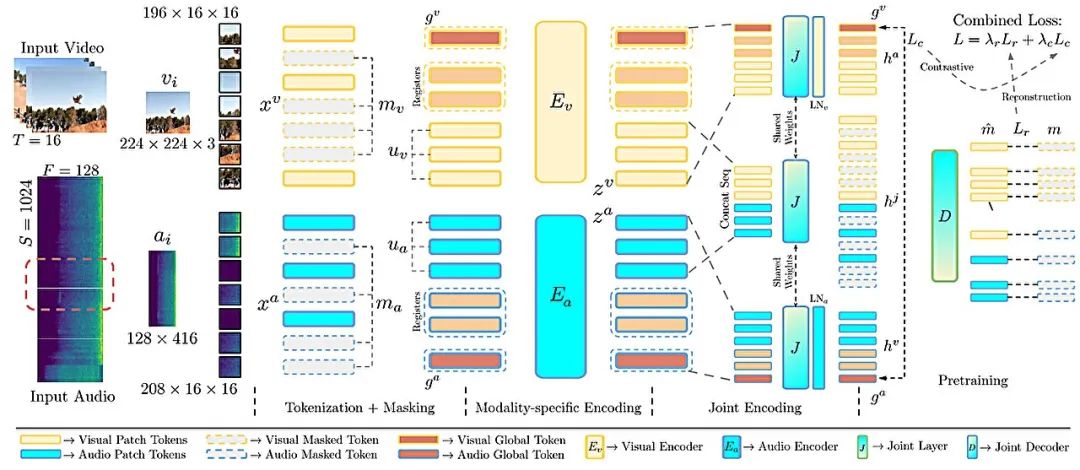
研究人员将这种模型称为 CAV-MAE,向其输入未标记的视频片段,它会分别将视觉和音频数据编码成称为“标记”的表示。利用录音中的自然音频,该模型自动学习将对应的音频和视觉标记在内部表示空间中映射到接近的位置。
他们发现,使用两个学习目标可以平衡模型的学习过程,这使得 CAV-MAE 能够理解对应的音频和视觉数据,同时提高其根据用户查询检索视频片段的能力。
但 CAV-MAE 将音频和视觉样本视为一个整体,因此,一个 10 秒的视频片段和门砰的一声被映射在一起,即使这个音频事件只发生在视频的一秒钟内。

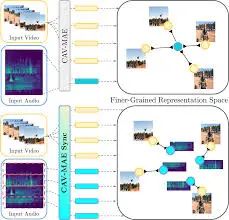
在他们改进的模型 CAV-MAE Sync 中,研究人员在模型计算数据表示之前将音频分成更小的窗口,因此它会生成与每个音频小窗口对应的单独表示。
在训练过程中,模型学习将一个视频帧与仅在该帧期间发生的音频联系起来。
阿拉乌霍说:
通过这样做,模型学习了更细致的对应关系,这在我们聚合这些信息时有助于后续的性能。
他们还引入了架构上的改进,帮助模型平衡其两个学习目标。
该模型包含一个对比目标,即学习将相似的音频和视觉数据联系起来,以及一个重建目标,旨在根据用户查询恢复特定的音频和视觉数据。
在 CAV-MAE Sync 中,研究人员引入了两种新的数据表示或标记,以提高模型的学习能力。
其中包括专门用于对比学习目标的“全局标记”和专门用于重建目标的“寄存器标记”,帮助模型关注重要细节。
阿拉乌霍补充道:
本质上,我们为模型增加了更多的灵活性,使其能够更独立地执行这两个任务,即对比任务和重建任务。这有助于整体性能。
尽管研究人员直觉上认为这些增强功能会提高 CAV-MAE Sync 的性能,但需要仔细结合多种策略,才能使模型朝着他们希望的方向发展。
鲁迪琴科说:
由于我们有多种模态,我们需要为每种模态本身都有一个好的模型,但我们也需要让它们融合在一起并协同工作。
最终,他们的增强功能提高了模型根据音频查询检索视频以及预测音视频场景类别(如狗吠或乐器演奏)的能力。
其结果比他们之前的工作更准确,而且它还比需要更多训练数据的更复杂的、最先进的方法表现更好。
阿拉乌霍说:
有时,非常简单的想法或你在数据中看到的一些小模式,当应用于你正在研究的模型时,会有很大的价值。

未来,研究人员希望将生成更好数据表示的新模型整合到 CAV-MAE Sync 中,这可能会提高性能。他们还希望使他们的系统能够处理文本数据,这将是朝着生成音视频大型语言模型迈出的重要一步。
这项工作部分由德国联邦教育与研究部和麻省理工学院 – IBM 沃森人工智能实验室资助。
(文:AI音频时代)