


0x00 前言

后续会陆续更新一些CUDA和Triton Kernel编程入门向的文章,虽然比较浅显简单,但我自己挺喜欢这种温故而知新的感觉。原文档链接:Fused Softmax – Triton documentation(https://triton-lang.org/main/getting-started/tutorials/02-fused-softmax.html#sphx-glr-getting-started-tutorials-02-fused-softmax-py);不过Triton官方的Fused Softmax示例代码年久失修,现在已经完全跑不起来了。本文提供了一个修改后能跑的。
本人更多的技术笔记以及CUDA学习笔记,欢迎来LeetCUDA(https://github.com/xlite-dev/LeetCUDA)查阅。LeetCUDA包括了本人的LLM/VLM文章整理,以及对FlashAttention、SGEMM、HGEMM、GEMV等常见CUDA Kernel的示例实现,目前已经累计3k+ stars,传送门:https://github.com/xlite-dev/LeetCUDA

本人Triton相关笔记列表如下:
-
DefTruth:[Triton编程][基础] Triton极简入门: Triton Vector Add(https://zhuanlan.zhihu.com/p/1902778199261291694) -
DefTruth:[Triton编程][基础] Triton Fused Softmax Kernel详解: 从Python到PTX(https://zhuanlan.zhihu.com/p/1899562146477609112) -
DefTruth:[Triton编程][基础] vLLM Triton Merge Attention States Kernel详解(https://zhuanlan.zhihu.com/p/1904937907703243110) -
DefTruth:[Triton编程][进阶] vLLM Triton Prefix Prefill Kernel图解(https://zhuanlan.zhihu.com/p/695799736)
本文内容包括以下部分:
-
0x00 前言 -
0x01 Naive Softmax实现 -
0x02 Triton Fused Softmax实现 -
0x03 row索引的计算方式 -
0x04 num_stages的作用是什么 -
0x05 num_programs计算 -
0x06 性能对比 -
0x07 总结
0x01 Naive Softmax实现
首先,使用pytorch实现一个row-wise的naive softmax:
importtorch
defnaive_softmax(x):
"""Compute row-wise softmax of X using native pytorch
We subtract the maximum element in order to avoid overflows. Softmax is invariant to
this shift.
"""
# read MN elements ; write M elements; 读取MN元素;写M个元素
x_max=x.max(dim=1)[0]
# read MN + M elements ; write MN elements; 读取MN+M元素;写入MN元素
z=x-x_max[:,None]
# read MN elements ; write MN elements; 读取MN元素;写入MN元素
numerator=torch.exp(z)
# read MN elements ; write M elements; 读取MN元素;写M个元素
denominator=numerator.sum(dim=1)
# read MN + M elements ; write MN elements; 读取MN M元素;写入MN元素
ret=numerator/denominator[:,None]
# in total: read 5MN + 2M elements ; wrote 3MN + 2M elements;
returnret# 共:读取5MN+2M元素;写了3MN+2M个元素从代码中的注释可知,naive softmax的访存量为:读取5MN+2M元素;写了3MN+2M个元素;即8MN+4M;
0x02 Triton Fused Softmax实现
softmax_kernel的主要思路为:给kernel分配num_programs个programs(也就是thread blocks,后边都把program等同于thread block),每个thread block处理互不重合的一部分rows;对每个row,按行求safe softmax,先求max,再求exp,最后求:softmax_output = numerator / denominator。这个softmax_kernel只需要对x进行读操作一次,以及对y进行写操作一次,对比naive softmax的8MN+4M访存量,Triton softmax_kernel只需要2MN的访存量,约为原来的1/4;
@triton.jit
defsoftmax_kernel(output_ptr,input_ptr,input_row_stride,output_row_stride,n_rows,n_cols,BLOCK_SIZE:tl.constexpr,
num_stages:tl.constexpr):
# starting row of the program
row_start=tl.program_id(0)
row_step=tl.num_programs(0)
forrow_idxintl.range(row_start,n_rows,row_step,num_stages=num_stages):
# The stride represents how much we need to increase the pointer to advance 1 row
row_start_ptr=input_ptr+row_idx*input_row_stride
# The block size is the next power of two greater than n_cols, so we can fit each
# row in a single block
col_offsets=tl.arange(0,BLOCK_SIZE)
input_ptrs=row_start_ptr+col_offsets
# Load the row into SRAM, using a mask since BLOCK_SIZE may be > than n_cols
mask=col_offsets<n_cols
row=tl.load(input_ptrs,mask=mask,other=-float('inf'))
# Subtract maximum for numerical stability
row_minus_max=row-tl.max(row,axis=0)
# Note that exponentiation in Triton is fast but approximate (i.e., think __expf in CUDA)
numerator=tl.exp(row_minus_max)
denominator=tl.sum(numerator,axis=0)
softmax_output=numerator/denominator
# Write back output to DRAM
output_row_start_ptr=output_ptr+row_idx*output_row_stride
output_ptrs=output_row_start_ptr+col_offsets
tl.store(output_ptrs,softmax_output,mask=mask)0x03 row索引的计算方式
kernel中,关键是要理解这几句:(https://triton-lang.org/main/python-api/generated/triton.language.range.html#triton.language.range)
row_start=tl.program_id(0)
row_step=tl.num_programs(0)
forrow_idxintl.range(row_start,n_rows,row_step,num_stages=num_stages)根据tl.range的文档说明,该函数实现的是python/torch中的range功能。row_start其实就是block idx,取值为[0, num_programs),row_step的值就是num_programs的实际值,比如num_programs=10,表示这个kernel分配了10个thread block。那么为啥rows是按照num_programs(row_step)为间隔来取的,这是一开始让人想不明白的。这种方式不是很直观。但是,我们将几句展开来看,就会明白了。假设n_rows=100, row_step=num_programs=10,row_start就是block idx,取值为[0, num_programs=10)
>>>list(range(0,100,10))# thread block 0, row_start 0
[0,10,20,30,40,50,60,70,80,90]
>>>list(range(1,100,10))# thread block 1, row_start 1
[1,11,21,31,41,51,61,71,81,91]
>>>list(range(2,100,10))# thread block 2, row_start 2
[2,12,22,32,42,52,62,72,82,92]我们能看到,展开后,每个thread block实际负责的rows索引都是互不重复的。值得吐槽的是,这个kernel的变量命名方式,确实是让人有点困惑。这种方式不是很直观,猜测这种交替的索引布局方式,会影响L2 Cache的命中率。不然,其实改成[0,10), [10,20),…,[90,100)这种方式,我认为会更直观。
0x04 num_stages的作用是什么
我们先来看看tl.range的API文档是怎么说的:

在tl.range中,num_stages表示对当前的for loop进行多级流水线化,也就是在循环的一次迭代中,会加载num_stages份数据(num_stages行)。对应到PTX中的指令应用,应该就是cp.async了,意思就是说,可以利用cp.async和num_stages来实现多级流水线,来将kernel中的计算和访存操作进行overlap,从而提高kernel性能。那么,到底是不是真的这样子呢?我们可以把gen code dump下来,抓出其中的PTX来分析。我们可以通过TRITON_CACHE_DIR环境变量,将Triton生成的中间IR保存下来。
exportTRITON_CACHE_DIR=$(pwd)/cache
python3 triton_fused_softmax.py
cd cache && tree .
.
├── 0d7duE9PwZgNUtoh6wb3yun356hXMwGHw2TM8-BcO5s
│ └── __triton_launcher.so
├── Jd4HhUM5PbKNdPpOLLxG6knNnfS3WPM3oXHA6POM45M
│ ├── __grp__softmax_kernel.json
│ ├── softmax_kernel.cubin
│ ├── softmax_kernel.json
│ ├── softmax_kernel.llir
│ ├── softmax_kernel.ptx
│ ├── softmax_kernel.ttgir
│ └── softmax_kernel.ttir
└── q4oIpkjOtdHHfi8xBkm4jC4JWIk5AjKtN8WRkZb8MD8
└── cuda_utils.so我们只要关注softmax_kernel.ptx这个中间文件就可以了,在代码中,我们指定了k_stages=num_stages=4:
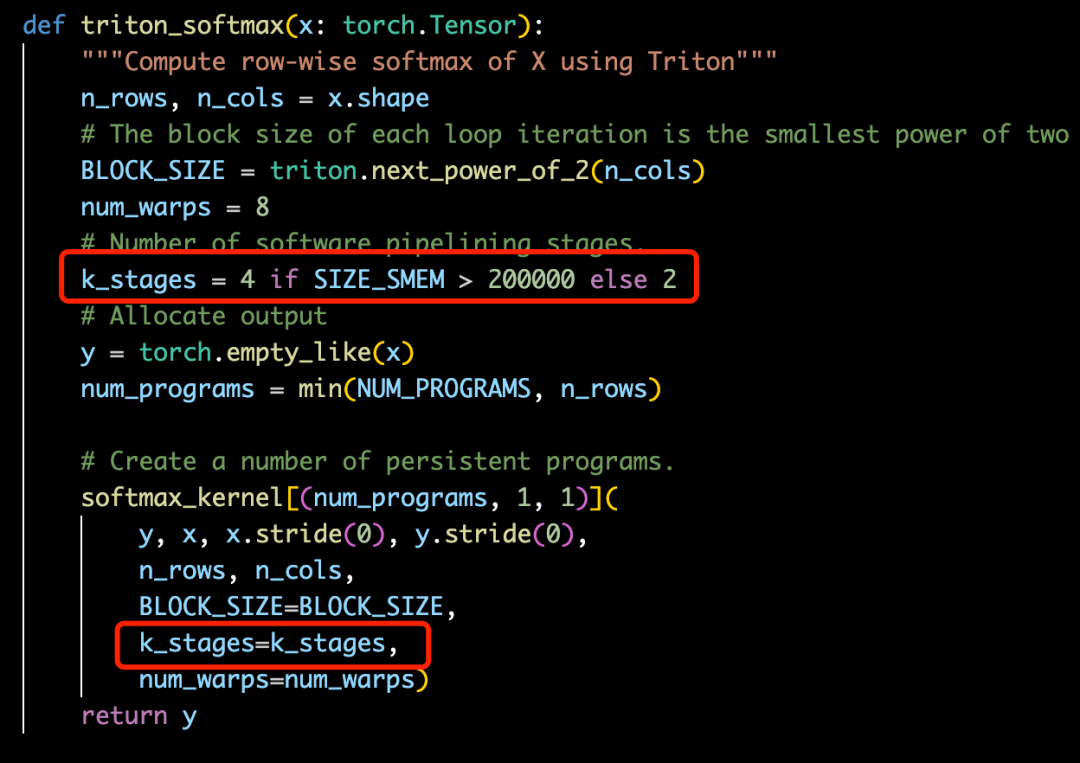
对应到softmax_kernel.ptx中,就是调用了4次cp.async指令,如下图。调用4次cp.async后,先commit_group,然后执行一些计算后,再wait_group;等数据加载到SRAM后,再执行后续的计算。不过,从生成的PTX看,Triton生成的pipeline逻辑,也不是最优的,因为它wait_group 0x0,导致还是要等待所有内存事务ready后才执行exp相关的计算。

0x05 num_programs计算
在Triton的Fused Softmax示例中,num_programs的值不是拍脑袋得出来的,而是根据kernel使用的寄存器数量、当前device的SM数量、device最大支持的寄存器数量以及occupancy来计算得到的,逻辑如下:
properties=driver.active.utils.get_device_properties(DEVICE.index)
NUM_SM=properties["multiprocessor_count"]
NUM_REGS=properties["max_num_regs"]
SIZE_SMEM=properties["max_shared_mem"]
WARP_SIZE=properties["warpSize"]
target=triton.runtime.driver.active.get_current_target()
kernels={}
defsofmax(x):
n_rows,n_cols=x.shape
# The block size of each loop iteration is the smallest power of two greater than the number of columns in `x`
BLOCK_SIZE=triton.next_power_of_2(n_cols)
num_warps=8
# Number of software pipelining stages.
num_stages=4ifSIZE_SMEM>200000else2
# Allocate output
y=torch.empty_like(x)
# pre-compile kernel to get register usage and compute thread occupancy.
kernel=softmax_kernel.warmup(y,x,x.stride(0),y.stride(0),n_rows,n_cols,BLOCK_SIZE=BLOCK_SIZE,
num_stages=num_stages,num_warps=num_warps,grid=(1,))
kernel._init_handles()
n_regs=kernel.n_regs
size_smem=kernel.metadata.shared
ifis_hip():
# ...
else:# CUDA
occupancy=NUM_REGS//(n_regs*WARP_SIZE*num_warps)
occupancy=min(occupancy,SIZE_SMEM//size_smem)
num_programs=NUM_SM*occupancy
num_programs=min(num_programs,n_rows)
# Create a number of persistent programs.
kernel[(num_programs,1,1)](y,x,x.stride(0),y.stride(0),n_rows,n_cols,BLOCK_SIZE,num_stages)不过,Triton官方的Fused Softmax示例代码年久失修,现在已经完全跑不起来了。NUM_SM、NUM_REGS这些属性的获取方式,在最新的triton API中,也被移除了,我用pycuda写了一个等价的。
defget_device_properties(device_id=None):
importpycuda.driverascuda
importpycuda.autoinit
device=(cuda.Device(device_id)ifdevice_idisnotNone
elsetorch.cuda.current_device())
NUM_SM=device.get_attribute(
cuda.device_attribute.MULTIPROCESSOR_COUNT)
NUM_REGS=device.get_attribute(
cuda.device_attribute.MAX_REGISTERS_PER_BLOCK)
SIZE_SMEM=device.get_attribute(
cuda.device_attribute.MAX_SHARED_MEMORY_PER_BLOCK)
WARP_SIZE=device.get_attribute(
cuda.device_attribute.WARP_SIZE)
returnNUM_SM,NUM_REGS,SIZE_SMEM,WARP_SIZE0x06 性能对比
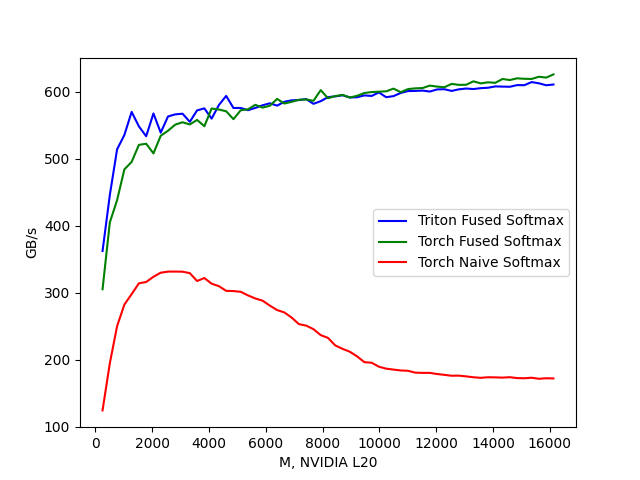
Triton官方的Fused Softmax示例代码年久失修,现在已经完全跑不起来了。本文提供了一个修改后能跑的,代码在:triton fused-softmax(https://github.com/xlite-dev/LeetCUDA/tree/main/kernels/openai-triton/fused-softmax),性能结果如下。按照前文的分析,triton softmax_kernel只需要对x进行读操作一次,以及对y进行写操作一次,对比naive softmax的8MN+4M访存量,triton softmax_kernel只需要2MN的访存量,约为原来的1/4;我们看到,从测试结果看,triton-fused-softmax的带宽吞吐是naive-softmax的4倍左右,与我们分析的结论相符合。
0x07 总结
本文详细介绍了Triton Fused Softmax Kernel的实现逻辑,分析了Fused Softmax的访存量,只有naive softmax的1/4;同时,也深入到PTX层面,分析了tl.range中num_stages的作用和其实现的多级流水线(cp.async);最后,本文还对年久失修的Triton Fused Softmax代码进行了修复,跑通benchmark,其性能结果符合理论分析,带宽吞吐提升4x;代码在:https://github.com/xlite-dev/LeetCUDA/tree/main/kernels/openai-triton/fused-softmax。
本人更多的技术笔记以及CUDA学习笔记,欢迎来LeetCUDA(https://github.com/xlite-dev/LeetCUDA)查阅。LeetCUDA包括了本人的LLM/VLM文章整理,以及对FlashAttention、SGEMM、HGEMM、GEMV等常见CUDA Kernel的示例实现,目前已经累计3k+ stars,传送门:https://github.com/xlite-dev/LeetCUDA
老样子,错误先更后改……
– The End –

长按二维码关注我们
本公众号专注:
1. 技术分享;
2. 学术交流;
3. 资料共享。
欢迎关注我们,一起成长!
(文:GiantPandaCV)