


极市导读
本文提出了一种名为 MaskUNet 的新方法,通过对扩散模型中的 U-Net 参数进行掩蔽,显著提升了图像生成质量。该方法利用时间步和样本依赖的掩蔽策略,动态选择有效的 U-Net 参数,从而提高生成效果,同时保持模型的泛化能力。 >>加入极市CV技术交流群,走在计算机视觉的最前沿

paper title: Not All Parameters Matter: Masking Diffusion Models for Enhancing Generation Ability
南开大学发表在CVPR 2025的工作
作者:Lei Wang, Senmao Li, Fei Yang† , Jianye Wang, Ziheng Zhang Yuhan Liu, Yaxing Wang, Jian Yang†
paper:https://arxiv.org/pdf/2505.03097
项目主页:https://gudaochangsheng.github.io/MaskUnet-Page/
代码:https://github.com/gudaochangsheng/MaskUnet
Abstract
扩散模型在早期阶段主要致力于构建基本的图像结构,而精细的细节(包括局部特征和纹理)则是在后续阶段生成。因此,相同的网络层被迫同时学习结构信息和纹理信息,这与传统的深度学习架构(例如 ResNet 或 GAN)显著不同,后者通常在不同层捕捉或生成图像语义信息。这种差异启发我们探索扩散模型中的时间维度机制。我们最初研究了 U-Net 参数对去噪过程的关键贡献,并识别出:适当地将某些参数置零(包括较大的参数)有助于去噪,从而在生成过程中显著提升图像质量。基于这一发现,我们提出了一种简单但有效的方法——称为 “MaskUNet”——该方法能够在几乎不增加参数量的前提下提升生成质量。我们的方法充分利用了时间步和样本相关的有效 U-Net 参数。为了优化 MaskUNet,我们提出了两种微调策略:1. 一种基于训练的策略;2. 一种免训练的策略,包括定制网络和优化函数。在 COCO 数据集上的 zero-shot 推理实验中,MaskUNet 实现了最优的 FID 分数,并在多个下游任务评估中展现出其有效性。
扩散模型 [20, 54] 是一类基于迭代去噪过程的生成模型,近年来因其在生成高质量图像、视频和三维数据表示方面的强大能力而受到广泛关注。文本到图像生成模型,如 Stable Diffusion(SD)[47],已成功将预训练的 U-Net 模型应用于多个下游任务,包括个性化文本图像生成 [33, 48]、关系反转 [25]、语义绑定 [2, 12, 24, 46] 以及可控生成 [7, 41, 64, 68]。在去噪的早期阶段,扩散模型建立表示语义结构的空间信息;而在后期阶段,则逐步细化至元素的局部细节 [5, 13]。因此,在不同的推理步骤中,扩散模型使用相同的网络参数(例如 SD 中的 U-Net)被迫学习不同类型的信息:早期学习全局结构与语义特征,后期学习边缘、纹理等局部信息。
然而,传统的分类模型 [17, 23, 53, 58](例如 ResNet [17])在不同层级上捕捉图像信息(如结构和语义特征)。通常,浅层负责提取结构信息,而深层则捕捉更高级的语义特征 [30, 51, 67]。类似地,在传统的生成模型中 [27, 28],生成器的前几层控制结构信息的合成,而更深的层则表示纹理和边缘等细节。无论是经典的分类任务还是生成任务,它们都利用模型的不同部分来表征样本的内部属性,从而降低网络优化的难度并增强其表征能力。与上述两类方法不同,扩散模型在生成一个样本时使用相同的参数被迫学习不同的信息。然而,据我们所知,这种扩散模型中 U-Net 的差异性尚未被充分研究。
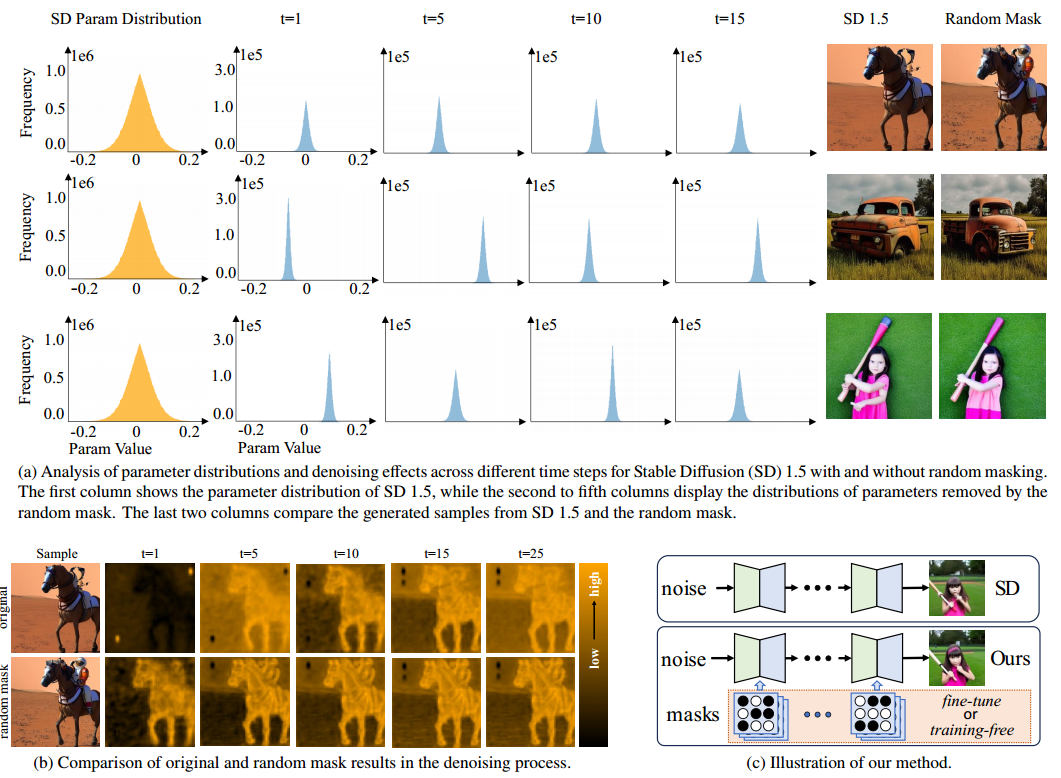
除了扩散模型的应用之外,本文关注的问题是:预训练 U-Net 参数在去噪过程中的有效性。为更好地理解去噪机制,我们首先通过在推理阶段引入随机掩码的实证分析,探索扩散模型的生成过程 —— 这是一个此前较少被研究的方向。如图 1(c) 所示,我们在推理阶段将预训练的 U-Net 权重与一个随机的、U-Net 结构相似的二值掩码相乘,从而在每一个时间步生成一个不同的网络。这种设计旨在保持与传统网络结构一致性,即在不同层捕捉不同的语义特征。如图 1(a)(第二列和最后一列)所示,使用特定的随机掩码能够增强 U-Net 架构的去噪能力,从而在保真度和细节保持方面生成更优的图像结果。此外,我们还可视化了在不同时间步的特征表示(见图 1(b))。与原始 SD 的特征相比,引入掩码后的主干网络能提取出更多结构信息和细节,从而提升去噪性能。这一结果表明,生成的样本可从不同的 U-Net 参数配置中受益。
基于上述发现,我们希望从扩散模型中选择那些有助于提升样本质量的关键参数。为实现这一目标,我们需要学习一个理想的二值掩码,该掩码能够屏蔽无效参数,保留关键参数。直接使用随机掩码无法保证良好的生成效果,因为理想的掩码与当前去噪的样本是相关的。如图 1(第三至第六列)所示,对每个样本进行纵向观察可以发现,不同样本所需的关键权重并不相同,这说明我们需要为每个样本生成一个定制化的掩码,才能合成高质量图像。这一观察结果促使我们在掩码生成中引入样本依赖性,使模型能够更好地适应每个 prompt 的具体需求。在本文中,我们提出了一种新颖策略,称为 MaskUNet,该方法在不更新预训练 U-Net 任何参数的前提下提升文本到图像生成的能力。具体而言,如图 1(c) 所示,我们引入一种可学习的二值掩码策略,用于从预训练的 U-Net 中采样参数,从而构建一个时间步依赖和样本依赖的 U-Net,突出生成敏感参数的重要性。为了高效地学习该掩码,我们设计了两种微调策略:一种是基于训练的策略,另一种是免训练的策略。在训练式方法中,我们使用一个参数采样器生成时间步和样本相关的掩码,该过程通过扩散损失进行监督。该参数采样器由一个 MLP 实现,其参数量相比预训练的 U-Net 可忽略不计。另一方面,免训练方法则直接在奖励模型 [61, 62] 的监督下生成掩码,无需引入显式的掩码生成器。
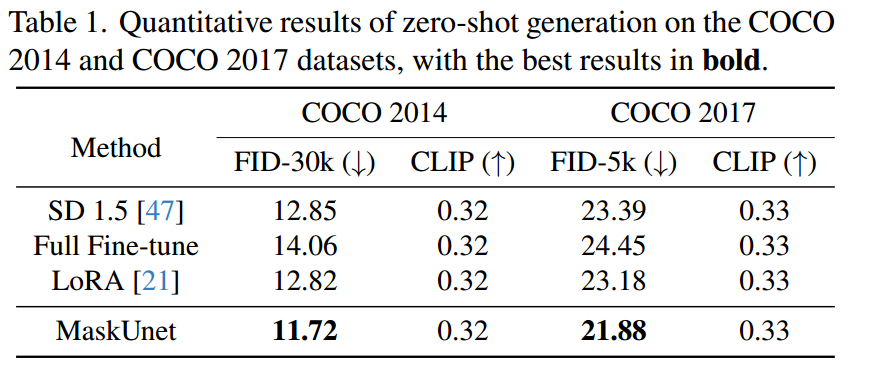
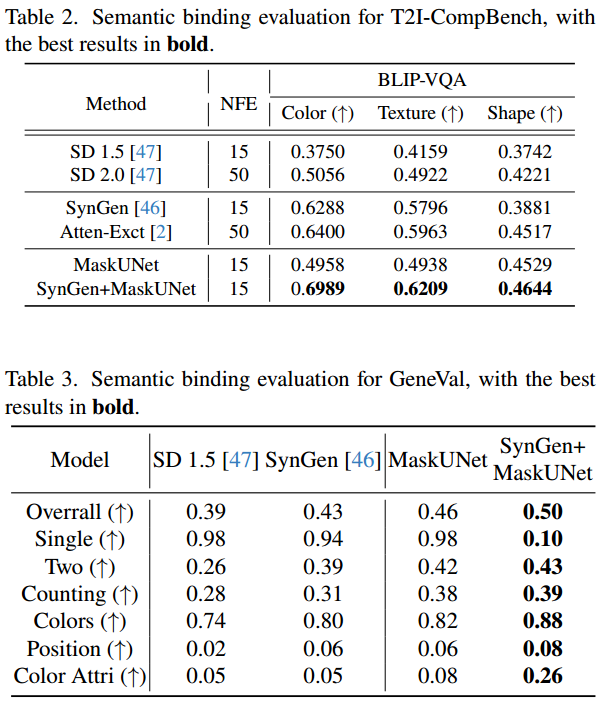
与现有的微调方法相比,MaskUNet 致力于挖掘模型的内在潜力,在 COCO 2014 [34] 和 COCO 2017 [34] 数据集上的 zero-shot 推理精度上取得了提升。我们还将 MaskUNet 应用于多个下游任务,包括图像定制 [10, 48]、视频生成 [29]、关系反转 [25] 和语义绑定 [2, 46],以验证其有效性。
本文的主要贡献总结如下:
-
我们深入研究了预训练 U-Net 参数、样本与时间步之间的关系,揭示了参数独立性的有效性,为高效利用 U-Net 参数提供了新的视角。 -
我们提出了一种用于文本到图像预训练扩散模型的全新微调框架,称为 MaskUNet。
在该框架中,训练式方法通过扩散损失优化掩码,而免训练方法则通过奖励模型优化掩码。可学习的掩码在保留模型泛化能力的同时,增强了 U-Net 的生成能力。
-
我们在 COCO 数据集及多个下游任务上对 MaskUNet 进行了评估。实验结果表明,该方法在样本质量和关键评估指标上均取得了显著提升。
2. Related Work
2.1. Diffusion Models
扩散模型 [20, 54, 56, 57] 在图像生成领域取得了显著成功,但直接在像素空间中进行计算效率较低。为了解决这一问题,Latent Diffusion Model(LDM)[47] 引入了变分自编码器(VAE),将图像压缩到潜空间中进行处理。此外,为了应对推理阶段的迭代去噪问题,一些工作提出了可以减少去噪步数的采样器 [37, 55, 65],而另一些方法则利用知识蒸馏来降低采样步数 [4, 6, 38, 42]。还有部分方法采用结构化剪枝以加速推理过程 [32, 40]。随着大规模图文数据集 [49, 50] 和视觉语言模型 [26, 44] 的出现,以 Stable Diffusion(SD)为代表的文本到图像生成网络得到了广泛应用,支持多种任务,例如可控图像生成 [41, 64]、可控视频生成 [7, 68],以及图像定制 [31, 33, 48]。
2.2. Training-based Models
基于训练的方法通过更新模型参数来增强 U-Net,通常采用以下策略:在特定层引入可训练模块以适配预训练权重用于新任务 [15, 41, 45, 63],选择性地微调部分已有参数 [14, 22],或直接更新全部参数。然而,这些方法存在过拟合的风险。近年来,LoRA [21] 和 DoRA [35] 等方法被提出,它们通过在预训练权重中注入低秩矩阵来提高模型灵活性并缓解过拟合问题。但这些方法仍然会调整原始参数空间,可能对预训练模型的泛化能力产生影响。相比之下,我们提出的 MaskUNet 在不更新 U-Net 参数的前提下保留了预训练模型的泛化能力。
2.3. Training-free Models
旨在增强 U-Net 生成能力的免训练模型大致可分为三类方法。第一类方法侧重于调整特征尺度 [16, 39, 52]。例如,FreeU [52] 引入了与样本相关的缩放因子用于调整 U-Net 的特征输出,并抑制跳跃连接中的特征,从而重新分配特征权重以提升生成质量。第二类方法强调通过多种监督机制优化潜在编码,例如注意力图 [1, 2, 46, 66]、噪声反演 [43] 或奖励模型 [8],以增强 U-Net 的生成性能。第三类方法关注于优化文本嵌入 [3, 9, 59]。例如,Chen 等人 [3] 使用平衡文本嵌入损失来修正关键 token 嵌入中的潜在问题,从而提升生成效果。与上述方法不同,MaskUNet 通过奖励模型对掩码进行监督,从而动态选择有效的 U-Net 参数以增强其生成能力。
3. Proposed Method
扩散模型在生成样本时使用相同的参数被迫学习不同的信息,限制了其生成的适应性。本文旨在学习一个与时间步和样本相关的掩码生成模型,用于从预训练的 U-Net 中进一步选择目标参数,从而增强扩散模型中预训练 U-Net 的表达能力。本节首先介绍扩散模型的基本背景作为理论基础(第 3.1 节),随后分别说明通过训练式(第 3.2 节)和免训练式(第 3.3 节)方法增强 U-Net 的策略。
3.1. Preliminary
扩散模型通过向数据添加噪声构造一个马尔可夫链,从而逼近一个简单的先验分布(通常为高斯分布)[20]。神经网络被训练用来反向还原这一过程,即从噪声出发逐步去噪以恢复原始数据,在每个步骤中学习提取有用信息。在 Latent Diffusion Model(LDM)[47] 中,扩散过程发生在一个低维的潜空间中,而不是像素空间中,从而显著提高了计算效率。LDM 的训练目标可以表示为最小化以下损失函数:
其中 表示均方误差, 是标准高斯分布的噪声, 是在时间步 的带噪潜变量, 是由去噪网络(参数为 )预测的噪声。
在文本到图像的扩散过程中,额外的文本提示 用于引导图像生成,以获得更可控的输出,因此训练目标变为:
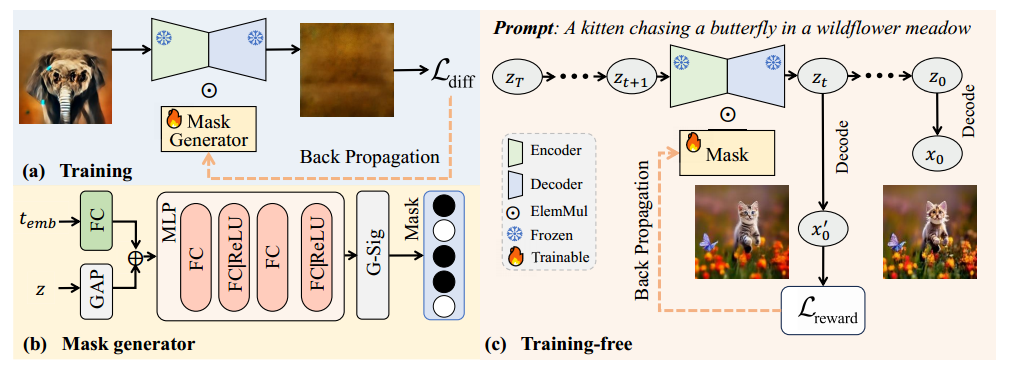
3.2. Training with Learnable Masks
为了充分挖掘模型参数的潜力,我们引入了一个可学习的掩码,用于从预训练的 U-Net 中采样权重。我们提出了一种基于训练的微调方法来优化该掩码,如图 2(a) 所示。该掩码通过公式 (2) 中定义的扩散损失进行训练。掩码由一个掩码生成器生成,如图 2(b) 所示。设输入的展平特征图为 ,其中 表示 batch size, 是 patch 数量, 表示输入通道数。掩码生成器的输入包括时间步嵌入 和潜变量编码 ,其中 和 分别表示 的高和宽。我们首先将 与 合并如下:
其中 是合并后的输出, 表示全连接层, 表示全局平均池化。
随后,我们对 施加一个含有两个 ReLU 激活函数的四层 MLP,引入非线性变换:
其中 是 MLP 的输出。
为了对权重进行采样,我们将 作为一个二值掩码处理:
其中 是通过 Gumbel-Sigmoid 激活函数 得到的输出。温度系数 控制 的离散程度:当 时, 趋近于一个二值分布;当 时, 趋于一个均匀分布。阈值 用于将概率分布离散化。
接下来,我们将重构后的掩码 应用于 U-Net 的线性层权重 ,以获得掩码后的权重:
其中 表示掩码后的权重, 表示逐元素乘法。
最后,将输入 与掩码后的权重 进行计算以获得输出特征:
其中 , 表示 batch 矩阵乘法操作。
通过引入掩码生成器,我们期望预训练的 U-Net 权重能够动态适应不同样本特征和时间步嵌入。值得注意的是,该设计并不更新 U-Net 的参数;相反,它利用样本和时间步相关的调控机制,使模型能够针对每个输入选择性地激活特定的 U-Net 权重。这种方法在保持预训练结构稳定性的同时,增强了预训练 U-Net 的灵活性。
3.3. Training-Free with Learnable Masks

为进一步验证掩码的有效性,受到 ReNO [8] 的启发,我们提出了一种免训练的算法,用于引导掩码的优化。如图 2(c) 所示,给定去噪过程中的中间状态 ,该状态由上一步中的表示 通过去噪得到,并在提示词 的引导下,可表示为:
其中 是预训练的 U-Net, 表示其参数。与训练式方法类似,我们引入掩码 作用于参数 ,即:
主要区别在于 并不依赖于掩码生成器。因此,式(8)可重写为:
接着,通过 VAE 将 解码为像素空间,得到 。利用 和提示词 ,我们将其输入到奖励模型中计算损失。该奖励损失随后反向传播,用于更新掩码参数,从而提升生成图像与提示词之间的一致性。
奖励损失定义如下:
其中 表示预训练奖励模型, 是权重因子。在本工作中,我们设 ,即使用两个奖励模型,分别为 ImageReward [62] 和 HPSv2 [62]。完整细节见算法 1。
4. Experiments
定量结果
定性结果





更多分析请见paper。
5. Conclusion
本文提出了 MaskUNet,一种用于增强扩散模型中 U-Net 参数表现的方法。通过引入可学习的二值掩码,MaskUNet 在推理过程中生成与时间步和样本相关的 U-Net 参数。实验结果表明,MaskUNet 显著提升了 U-Net 的生成能力,在 COCO 数据集的 zero-shot 任务中表现出更高的样本质量。此外,在图像定制、关系反转以及文本生成视频等下游任务中,我们的方法也优于现有方法。为提升计算效率,我们还提出了一种免训练的掩码学习方法,并在两个语义绑定基准测试上验证了其有效性。

(文:极市干货)