

「DeepSeek 一更新,我们就知道又要放假了。」
昨天,DeepSeek 宣布其 R1 系列推理模型小版本升级,最新版本 DeepSeek-R1-0528 参数量高达 6850 亿,模型在思维深度和推理方面的能力显著提升。
刚刚,DeepSeek 公布了 R1-0528 在各类基准测评上的具体得分情况。R1-0528 在数学、编程与通用逻辑等多个基准测评中成绩亮眼,整体表现接近 o3 与 Gemini-2.5-Pro。
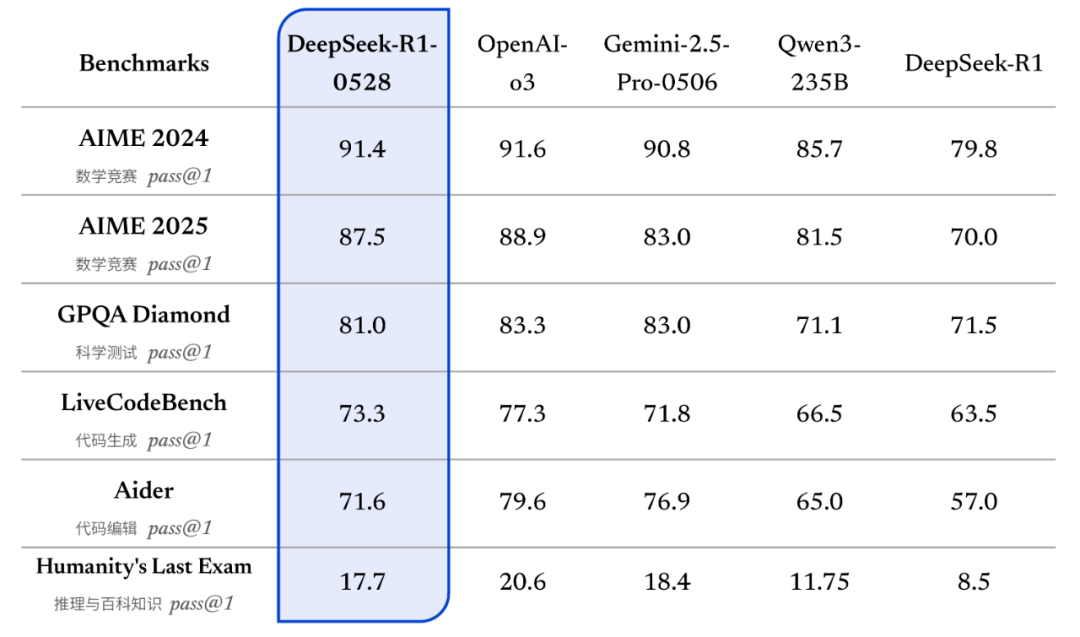
同时,DeepSeek 通过蒸馏 DeepSeek-R1-0528 的思维链后训练 Qwen3-8B Base 得到了一个 8B 模型。该模型在数学测试 AIME 2024 中仅次于 DeepSeek-R1-0528,超越 Qwen3-8B(+10.0%),与 Qwen3-235B 相当。
此外,值得一提的是,DeepSeek 对 R1-0528 版本的模型幻觉问题进行了优化,与旧版相比,更新后的模型在改写润色、总结摘要、阅读理解等场景中,幻觉率降低了 45~50% 左右。
目前,DeepSeek-R1-0528 已在网页端、APP 和小程序中上线,用户开启「深度思考」功能即可体验最新版本。同时,API 也同步更新,调用方式不变。
超 4000 人的「AI 产品市集」社群!不错过每一款有价值的 AI 应用。

-
最新、最值得关注的 AI 新品资讯;
-
不定期赠送热门新品的邀请码、会员码;
-
最精准的AI产品曝光渠道
深度思考能力强化
DeepSeek-R1-0528 在各项评测集上均取得了优异表现
(基准测试使用 64K 输出长度;在 Humanity’s Last Exam 中,只使用其中的文本题目进行测试)
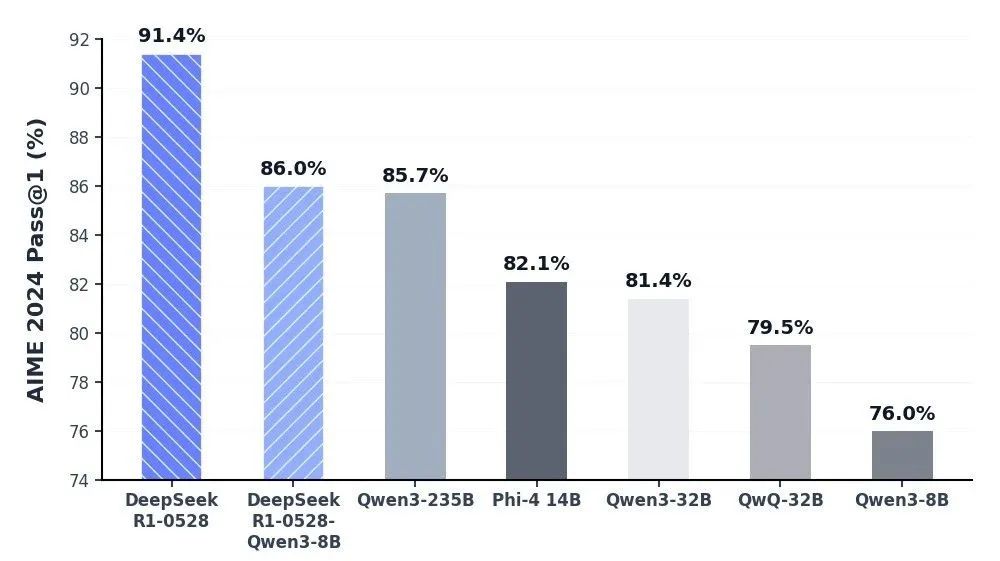
DeepSeek-R1-0528-Qwen3-8B 等开源模型的 AIME 2024 对比结果
新版模型幻觉降低 45~50%
-
幻觉改善:新版 DeepSeek R1 针对「幻觉」问题进行了优化。与旧版相比,更新后的模型在改写润色、总结摘要、阅读理解等场景中,幻觉率降低了 45~50% 左右,能够有效地提供更为准确、可靠的结果。
-
创意写作:在旧版 R1 的基础上,更新后的 R1 模型针对议论文、小说、散文等文体进行了进一步优化,能够输出篇幅更长、结构内容更完整的长篇作品,同时呈现出更加贴近人类偏好的写作风格。

-
工具调用:DeepSeek-R1-0528 支持工具调用(不支持在 thinking 中进行工具调用)。当前模型 Tau-Bench 测评成绩为 airline 53.5% / retail 63.9%,与 OpenAI o1-high 相当,但与 o3-High 以及 Claude 4 Sonnet 仍有差距。

模型开源,
API 同步更新
DeepSeek 开源了 R1-0528 模型,并公布了模型权重。
DeepSeek-R1-0528 模型权重下载参考:
Model Scope:
https://modelscope.cn/models/deepseek-ai/DeepSeek-R1-0528
Huggingface:
https://huggingface.co/deepseek-ai/DeepSeek-R1-0528
此外,DeepSeek 对其 API 也进行了同步更新,接口与调用方式保持不变。新版 R1 API 仍支持查看模型思考过程,同时增加了对 Function Calling 和 JsonOutput 的支持。

(文:Founder Park)