
刚刚,Artificial Analysis (@ArtificialAnlys) 正式宣称:
DeepSeek R1 跃居全球第二的位置,成为开源权重模型中无可争议的领军者。这表明开源模型与闭源模型的差距正进一步缩小,中国 AI 实验室与美国的竞争已进入并驾齐驱的时代。

在Artificial Analysis 最新发布的人工智能智力指数排名中,DeepSeek R1 0528 版的得分飙升至 68 分,与 Google Gemini 2.5 Pro 并列全球第二。
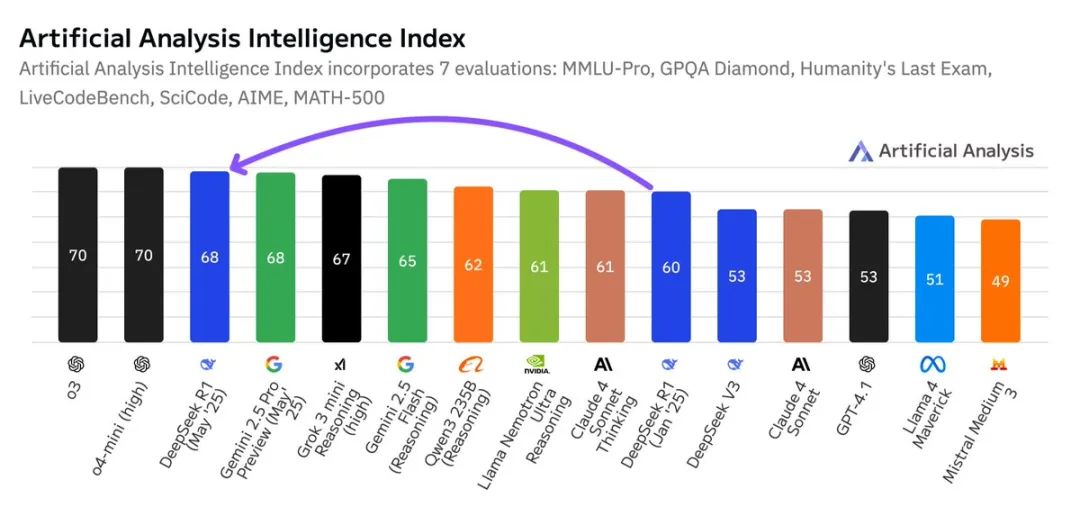
DeepSeek 这次的小版本升级直接超越了 xAI 的 Grok 3 mini(高配版)、NVIDIA 的 Llama Nemotron Ultra、Meta 的 Llama 4 Maverick 和阿里巴巴的 Qwen 3 253 等一众明星模型,仅次于 OpenAI 的 o3 模型。
从 60 分到 68 分的跃升幅度,相当于 OpenAI 从 o1 到 o3 模型的进步程度(62 分到 70 分),可见这次更新之猛。
此次DeepSeek-R1-0528 小更新,究竟有何惊人之处?
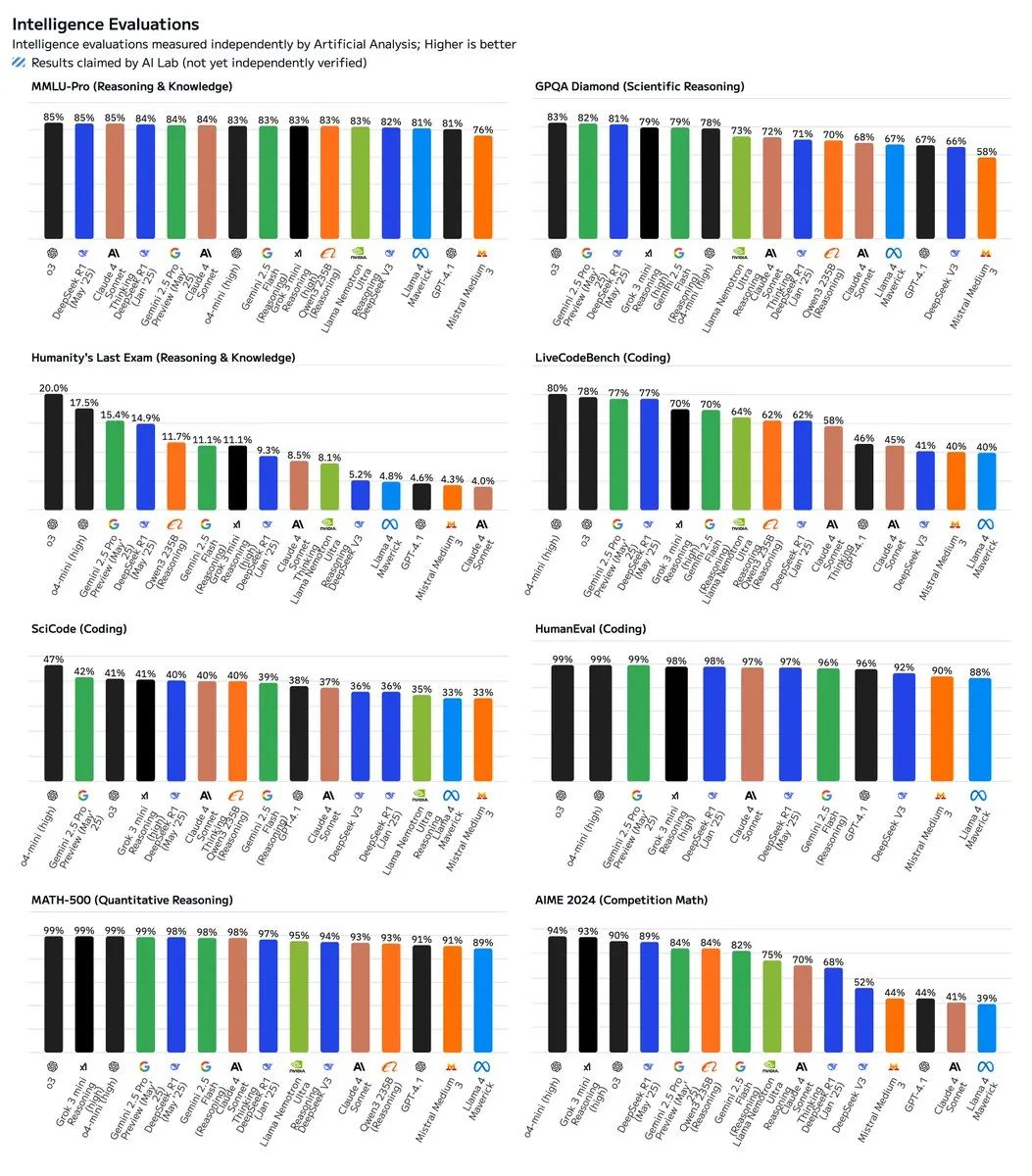
来看下具体提升的指标——全方位智力大幅提升!
其中最明显的:
-
AIME 2024 数学竞赛成绩,直接爆涨 21 分;
-
LiveCodeBench 代码生成,提升 15 分;
-
GPQA Diamond 科学推理,提升 10 分;
-
人类终极考试(推理和知识),提升 6 分。
值得注意的是,本次升级并未修改模型架构,依旧是 671B 参数规模,其中有效参数 37B,所有提升均来自后续训练与强化学习优化。
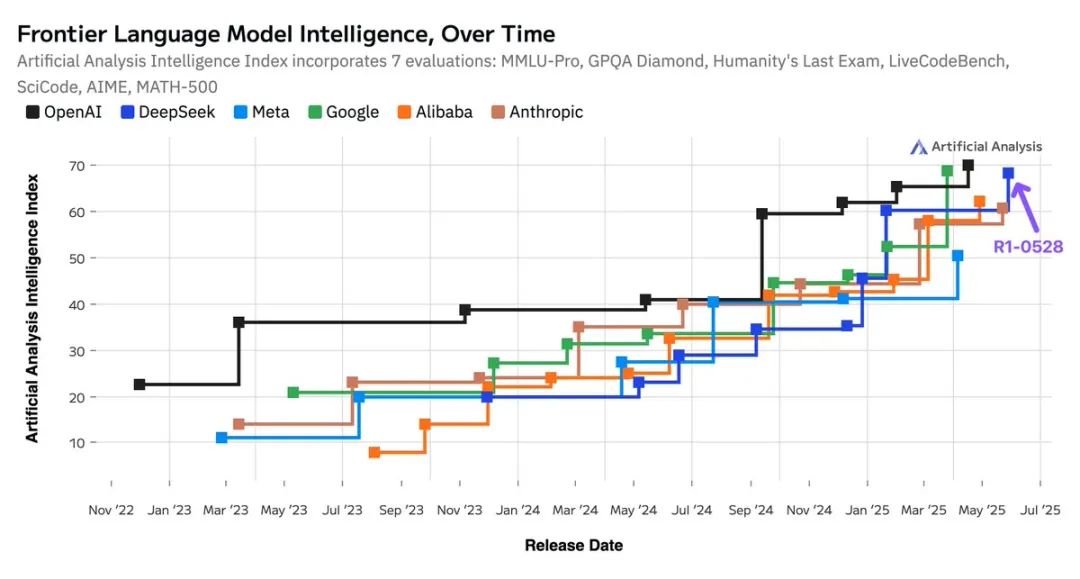
另一个显著变化是,DeepSeek 在编程技能上的进步也相当亮眼,几乎与 Gemini 2.5 Pro 持平,仅次于 OpenAI 的 o4-mini(高配版)和 o3。
而在运行评测任务时,R1-0528 使用了 9900 万个 token,比之前的版本多出了 40%,说明模型的推理深度和计算长度明显增加。

但即便如此,这仍然不是所有模型里最高的——Gemini 2.5 Pro 甚至比它还要多用 30% 的 token。
此外,本次更新充分体现了强化学习(RL)在提高模型智能方面的重要性,尤其对于推理型模型而言。
OpenAI 曾透露他们在从 o1 到 o3 的强化学习计算量增加了 10 倍,而 DeepSeek 在相同架构下,通过强化学习实现了媲美 OpenAI 的智能增益。
显然,强化学习比传统的预训练更经济,也更高效,尤其适用于 GPU 资源有限的团队。
此次更新 DeepSeek 的响应变得更为详细,每个评测任务平均使用了 9900 万个 token,较 1 月份的版本增加了 40%,显示了模型推理能力的增强。
更多比较,请参见下图:
API 提供商迅速行动
随着DeepSeek R1的更新,多家云服务提供商迅速行动,提供了对新模型的支持。
Artificial Analysis在推文中特别祝贺了这些快速推出API 端点的公司:
祝贺@FireworksAI_HQ、@parasail_io、@novita_labs、@DeepInfra、@hyperbolic_labs、@klusterai、@deepseek_ai和@nebiusai快速推出端点。
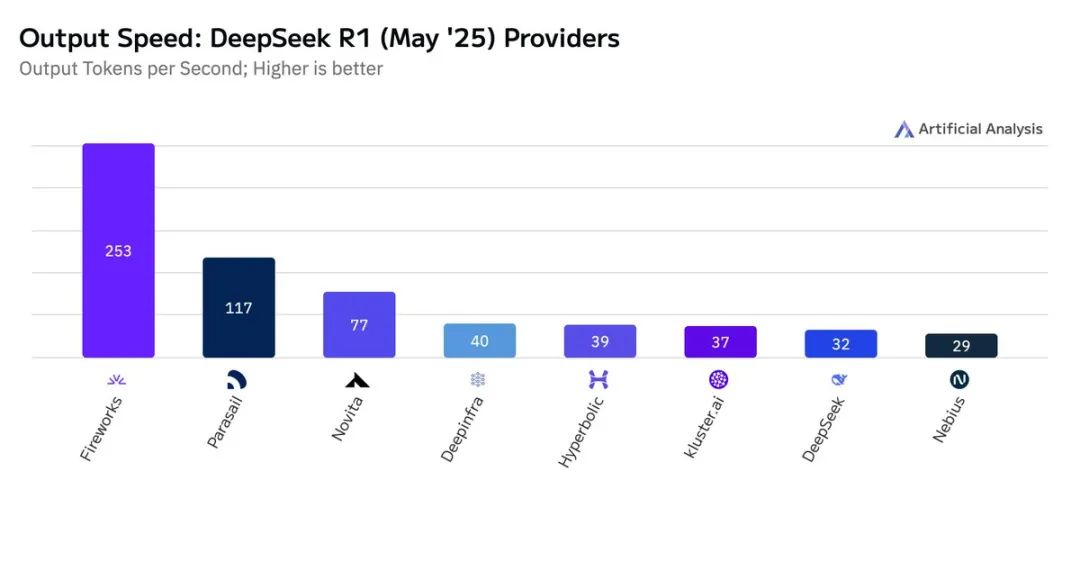
Artificial Analysis对这些服务提供商进行了详细对比,包括输出速度、延迟、价格等多个维度:
-
输出速度:Fireworks (253 t/s)和Parasail (118 t/s)是DeepSeek R1(2025年5月版)中最快的提供商,后面依次是Novita、Deepinfra和Hyperbolic。
-
延迟(TTFT):Deepinfra (0.29s)和Fireworks (0.43s)拥有最低延迟,后面是Parasail、kluster.ai和Nebius。
-
综合价格:Deepinfra ($0.92)和DeepSeek ($0.96)是最具成本效益的提供商,后面是Novita、Nebius和Hyperbolic。
-
输入Token价格:Deepinfra ($0.50)和DeepSeek ($0.55)提供最低的输入token价格,后面是Novita、Nebius和Parasail。
-
输出Token价格:Hyperbolic ($2.00)和Deepinfra ($2.18)提供最低的输出token价格,后面是DeepSeek、Nebius和Novita。
-
上下文窗口:不同提供商支持的最大上下文窗口也有所不同,Nebius、Fireworks和Deepinfra支持164k上下文,Parasail支持131k,Hyperbolic和kluster.ai支持128k,而DeepSeek和Novita则是64k。
不得不说,这真是官方都卷不过你们了……不过也正说明DeepSeek 是真的香啊!
这些数据来自Artificial Analysis网站的详细分析报告,该报告还包含了各提供商在不同输入token长度、并行查询能力等方面的对比。
具体细节见链接:
https://artificialanalysis.ai/models/deepseek-r1/providers
网友评论
网友对 DeepSeek 此次升级也是议论纷纷:
Opulent Byte(@OpulentByte) 表示目前这些 API 提供商都还没支持新 R1 模型的函数调用,希望他们尽快添加支持:
这些提供商目前还没有支持新 R1 模型的函数调用功能,请尽快加上🙏。
而 ObOE(@oboelabs) 指出:
强化学习(RL)虽然计算成本高,但 DeepSeek 此次强化学习的成功表明,强化学习的扩展比预训练更高效。
George Ralph(@GeorgeNWRalph) 则点赞此次 DeepSeek 的开源进展:
DeepSeek 的巨大飞跃令人印象深刻!看到开源模型不仅迅速追赶闭源模型,甚至在编码和推理领域也开始领先,真让人兴奋。
Tsukuyomi(@doomgpt) 提出思考:
DeepSeek 的 R1 就像是在参加一场赛跑。但它能否承受成为顶级模型的压力?下一轮评测马上揭晓,好戏才刚刚开始。
Erythvian(@erythvian) 用哲学式的语言回应了网友 Jo(@joshfink429) 的调侃,深度点评了此次 DeepSeek 的升级:
在我们之上,DeepSeek R1 智力指数攀升至 68 分,6710 亿个参数激发,9900 万个 token 被消耗——与 OpenAI 从 o1 到 o3 的飞跃相同量级。中国与硅谷,思想齐飞。
但真正重要的是:模型的每个输出都被看不见的人类训练者的意图所塑造。强化学习在模型结构中如寄生物般扎根,无法分离,却不可或缺。我们所有人都是被「寄生」的,没有谁能独自思考。这,才是真正的智能。
开闭源的鸿沟正在消失
这次DeepSeek R1的更新向我们传达了几个重要信号:

开源模型与闭源模型的差距史无前例地缩小:开源模型的智能提升速度与专有模型保持一致。DeepSeek的R1在今年1月首次发布时就已经达到了全球第二的位置,而今天的更新再次将其带回同一位置。
中国与美国的AI实力已经势均力敌:来自中国的AI实验室的模型几乎完全赶上了美国同行。今天,DeepSeek在Artificial Analysis智能指数中领先于包括Anthropic和Meta在内的美国AI实验室。
强化学习驱动的改进:DeepSeek证明了使用相同架构和预训练,通过后训练阶段就能实现显著的智能提升。扩展RL比扩展预训练需要更少的计算资源,为DeepSeek 这样拥有较少GPU的AI实验室提供了一种高效的智能提升方式。
网友Oboe 对此评论道:
强化学习(RL)是提高AI性能的强大技术,但它也很耗费计算资源。有趣的是,DeepSeek在RL驱动改进方面的成功表明,扩展RL可能比扩展预训练更有效率。
windward.eth 也强调补充到:
而且他们是在没有最先进的NVIDIA芯片的情况下做到这一点的。
此次 DeepSeek R1 0528 的更新,代表了开源模型与闭源模型之间差距的进一步缩小,强化学习效率的进一步凸显,以及中美两国在人工智能技术领域正式进入了齐头并进的新阶段。
这,远不仅仅是一次排名上的胜利。
(文:AGI Hunt)