

近日,腾讯混元与腾讯音乐联合开源了一款数字人音频驱动模型:HunyuanVideo-Avatar。

只需一张人物照片(单人/多人)和一段音频或语音文本,就能生成高度同步的嘴型、表情、动作动画,支持多角色对话和多种风格(真人、动漫、3D、卡通)。
它基于多模态扩散变换器(MM-DiT),通过一张人物图片和一段音频(最长14秒),生成高保真的语音驱动动画,支持单角色和多角色对话。
而此次 HunyuanVideo-Avatar 也引入了三项关键创新:
-
• 角色图像注入模块,确保了动态运动和强大的角色一致性; -
• 音频情感模块(AEM),用于从情感参考图像中提取和传递情感线索到目标生成的视频,实现细粒度和精确的情感风格控制; -
• 面部感知音频适配器(FAA),通过潜在级别的面部掩码隔离音频驱动的角色,使多角色场景中的音频注入能够通过交叉注意力独立进行。
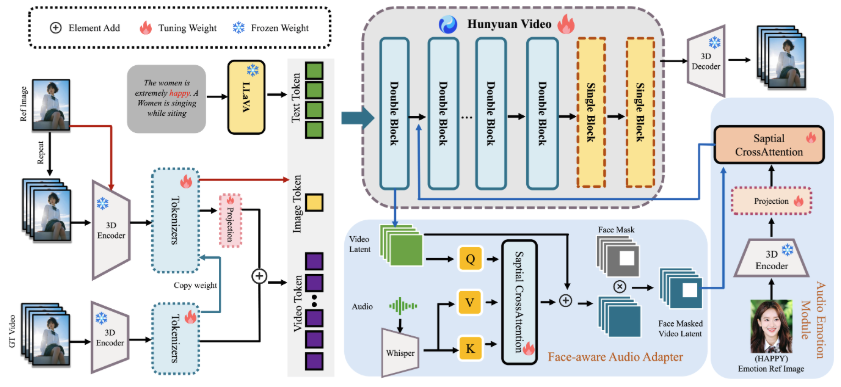
这些创新使 HunyuanVideo-Avatar 能够在基准数据集和全新提出的野外数据集上超越现有最先进的方法,生成动态、沉浸式场景中的逼真虚拟形象。

语音驱动的数字人技术正在席卷全球。从虚拟主播到电商代言,从二次元动画到虚拟歌手,逼真的AI数字人正改变视频创作的规则。
核心亮点
-
• 语音驱动:自动分析语音语速、停顿、情绪,生成对应口型与动态表情。 -
• 情绪可控的虚拟人动画生成:输入角色图像 + 音频,即可生成情绪同步的口型与表情动画。 -
• 支持多角色动画生成:可实现多个角色独立说话并表现出各自情绪。 -
• 支持多风格图像:支持真实照片、卡通、3D、拟人角色等图像风格。 -
• 多尺度生成:支持肖像、半身、全身图像。 -
• 高保真:角色一致性和动态效果拉满。
快速使用
目前 HunyuanVideo-Avatar 功能已经上线了混元官网,可直接免费使用。(地址放文末了)
(来源X网友:tekiteki所创作的唱歌视频)
你只需准备:一张人物图(可真人、卡通、动漫、3D)、一段语音或说话的文案(说话 or 唱歌)
人物图尽量保证是清晰的正脸,这样效果会更好!
上传了图片和语音后,可调节语速控制,还可选择14种音色进行搭配。
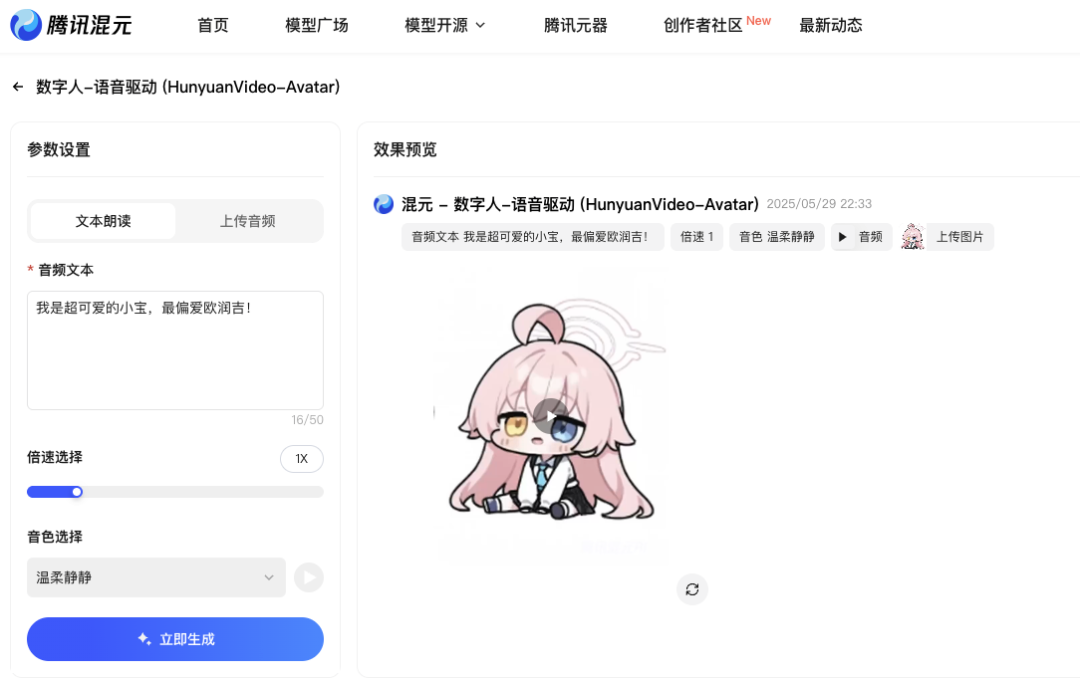
最后点击生成,等待一段时间后即可预览动画效果!
当然,对于有条件的个人或企业,也可以自己部署该服务。
最低要求:GPU内存得24GB,但速度非常慢。建议使用具有96GB内存的GPU。
首先克隆项目代码
git clone https://github.com/Tencent-Hunyuan/HunyuanVideo-Avatar.git
cd HunyuanVideo-Avatar再安装环境及依赖包
# 1. 创建虚拟环境
conda create -n HunyuanVideo-Avatar python==3.10.9
# 2. 激活虚拟环境
conda activate HunyuanVideo-Avatar
# 3. 安装 PyTorch 和其他依赖
# For CUDA 11.8
conda install pytorch==2.4.0 torchvision==0.19.0 torchaudio==2.4.0 pytorch-cuda=11.8 -c pytorch -c nvidia
# For CUDA 12.4
conda install pytorch==2.4.0 torchvision==0.19.0 torchaudio==2.4.0 pytorch-cuda=12.4 -c pytorch -c nvidia
# 4. 安装pip依赖
python -m pip install -r requirements.txt
# 5. Install flash attention v2 for acceleration (requires CUDA 11.8 or above)
python -m pip install ninja
python -m pip install git+https://github.com/Dao-AILab/flash-attention.git@v2.6.3习惯使用Docker部署服务的同学,也可以用Docker镜像快速部署:
# For CUDA 12.4 (updated to avoid float point exception)
docker pull hunyuanvideo/hunyuanvideo:cuda_12
docker run -itd --gpus all --init --net=host --uts=host --ipc=host --name hunyuanvideo --security-opt=seccomp=unconfined --ulimit=stack=67108864 --ulimit=memlock=-1 --privileged hunyuanvideo/hunyuanvideo:cuda_12
pip install gradio==3.39.0 diffusers==0.33.0 transformers==4.41.2
# For CUDA 11.8
docker pull hunyuanvideo/hunyuanvideo:cuda_11
docker run -itd --gpus all --init --net=host --uts=host --ipc=host --name hunyuanvideo --security-opt=seccomp=unconfined --ulimit=stack=67108864 --ulimit=memlock=-1 --privileged hunyuanvideo/hunyuanvideo:cuda_11
pip install gradio==3.39.0 diffusers==0.33.0 transformers==4.41.2最后运行 Gradio 服务器
cd HunyuanVideo-Avatar
bash ./scripts/run_gradio.sh该方式适合有Python基础的企业用户,新手可先试用线上版本。
应用场景推荐
-
• 电商直播助播:上传产品人物图 + 解说音频,自动生成带情绪的介绍视频 -
• AI 虚拟播报:录入播报文案音频,数字主播自动生成 -
• AI 个性教师:老师照片 + 授课音频,打造定制教育讲解视频 -
• 数字人访谈:多人角色图 + 问答音频,自动对话演绎访谈节目 -
• 卡通唱歌视频:二次元人物图 + 歌曲音频,生成嘴型情绪俱佳的 MV 视频
写在最后
还在用静态照片做视频内容?现在你可以通过 HunyuanVideo-Avatar 直接让照片动起来,说话、唱歌、甚至聊天!
它通过字符注入(CII)、情绪模块(AEM)和面部适配(FAA),实现高保真、多角色、情绪同步的动画生成。
不论是唇形同步,还是适配角色及音频的表情情绪,都是高质量!能够轻松玩出虚拟唱歌、数字人播报、讲课等创意玩法。
对自媒体、电商、教育、数字人创业者,它提供了一个快速实现“AI 代言人”的能力基座,并且完全开源免费并可本地部署!
GitHub 项目地址:https://github.com/Tencent-Hunyuan/HunyuanVideo-Avatar
官网体验:https://hunyuan.tencent.com/modelSquare/home/play?modelId=126

● 一款改变你视频下载体验的神器:MediaGo
● 字节把 Coze 核心开源了!可视化工作流引擎 FlowGram 上线,AI 赋能可视化流程!
● 英伟达开源语音识别模型!0.6B 参数登顶 ASR 榜单,1 秒转录 60 分钟音频!
● 开发者的文档收割机来了!这个开源工具让你一小时干完一周的活!
● PDF文档解剖术!OCR神器+1,这个开源工具把复杂排版秒变结构化数据!

(文:开源星探)