
话接上文:测完新版 DeepSeek R1,我发现它越来越像 ChatGPT 了。
昨天刚吐槽完 DeepSeek 没有更新日志,结果今天官方就正式发布了“思考更深,推理更强”的 DeepSeek R1 升级说明。
同样是开源,同样是节假日前夕(端午节),DeepSeek,总能给我们惊喜。
升级后的新模型有了正式的名字:DeepSeek-R1-0528。
新模型的命名带有强烈的 “DeepSeek” 风格,不升级大版本号,只添加更新日期。
和两个月前的 DeepSeek-V3-0324 一样。
虽然仍旧是 R1,但确实是个扎实的小版本迭代,特别是在“复杂推理”、“前端开发”、“幻觉降低”几个方向。

01|推理更强,不是说说而已
根据 DeepSeek 官方的说明,这次 R1 升级重点强化了复杂问题下的思考深度。
最直接的体现:
-
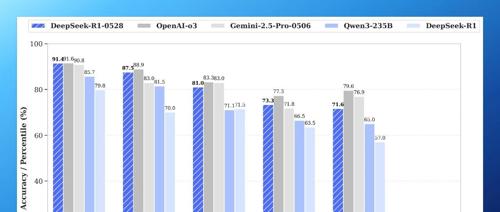
在 AIME 2025 数学测试中,准确率从 70% 提升到 87.5% -
每道题平均 token 使用量从 12K → 23K,翻了快一倍
什么意思?不是更快了,而是会更认真做题了(更多的 token 消耗意味着更深入、更详尽的思考)。
|
|
|
|
|---|---|---|
|
|
|
87.5 |
|
|
|
79.4 |
|
|
|
1930 |
|
|
|
73.3 |
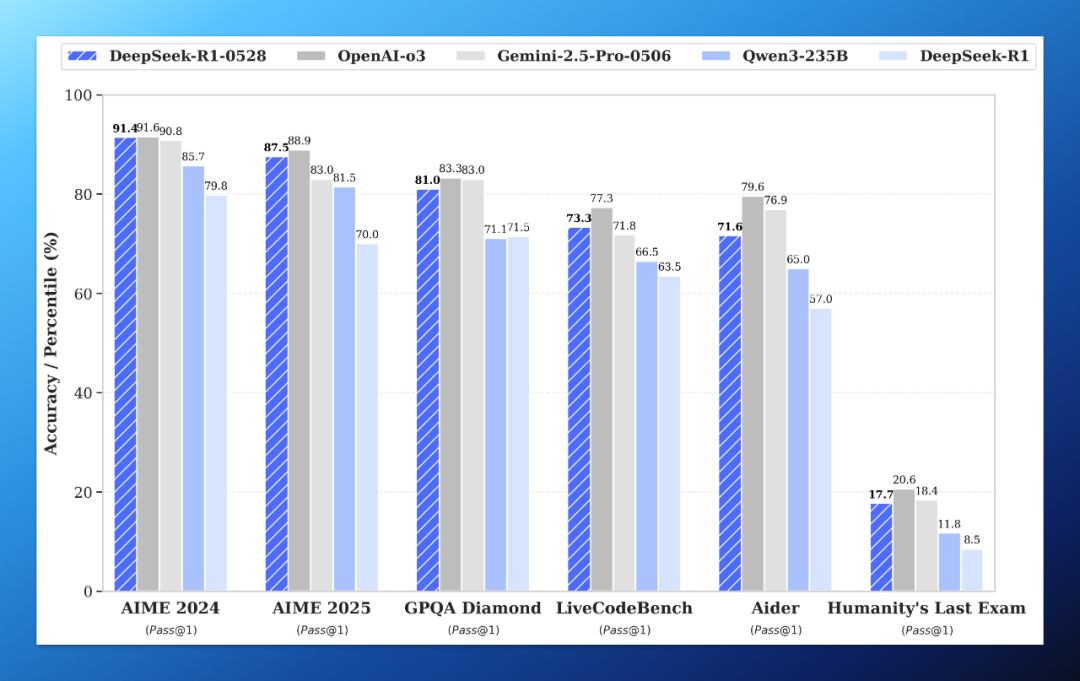
从官方给出的基准测试对比结果可以看出,对比当前的“开源之王” Qwen3 235B,新版 DeepSeek R1 已经将其全面超越。
而面对全球范围内顶尖的闭源模型 o3 和 Gemini 2.5 Pro,新版 R1 也是不遑多让:和 o3 比略有差距,和 Gemini 2.5 Pro 比多项测试甚至反超,比如 AIME 2025、LiveCodeBench。
再考虑到 DeepSeek R1 的使用成本,这已经拉满的性价比又再次上了一个台阶。
02|幻觉率下降,写作能力增强
DeepSeek 系列模型的幻觉一直是个大问题。
因为幻觉太高,就注定不太适合干一些很“正经”的事情,比如学术论文的写作。
DeepSeek 官方肯定也清楚这个问题,所以特意强调了新版 R1 在摘要、改写、阅读理解等任务中的幻觉率下降了 45-50%,这数据还是非常诱人的。
尽管在我昨天的测试中依旧有着不小的幻觉,但有提升就值得点赞。
写作类能力方面,新增对“议论文、小说、散文”等长文本风格的训练,生成结果更贴近人类喜好,篇幅也更长、更完整。

昨天我测“1000 万怎么赚”那个问题时就有感受到,回答内容更丰富、结构感更强,而且还会加 emoji,明显在向 ChatGPT 的“拟人化”风格靠拢。
03|工具调用刚起步,API 改动需注意
除了幻觉,工具调用(Function Call)也是老版本 DeepSeek-R1 模型的老大难。
这次升级后的 R1 已经添加了对 Function Calling 和 JSON 输出格式的支持。
R1 的工具调用目前表现还在“够用”阶段,在 Tau-Bench 测评中成绩为 airline 53.5% / retail 63.9%,约等于 OpenAI o1 high,但低于目前最顶级的、能够由模型自主调用外部工具的 o3 和 Claude 4。
但好歹能用了。
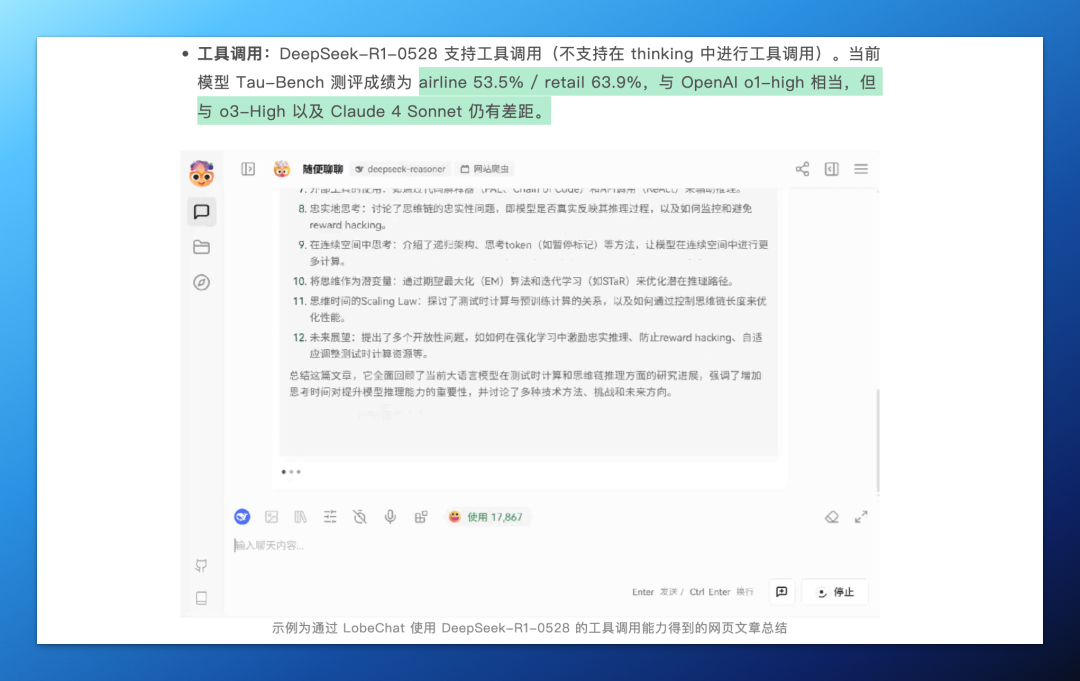
并且,使用 API 的小可爱需要额外注意,max_tokens 参数现在表示 单次输出总长度(包括思考过程),默认 32K,最大 64K tokens。
04|会教学生了?R1 蒸馏出 8B 小模型,性能对标大模型
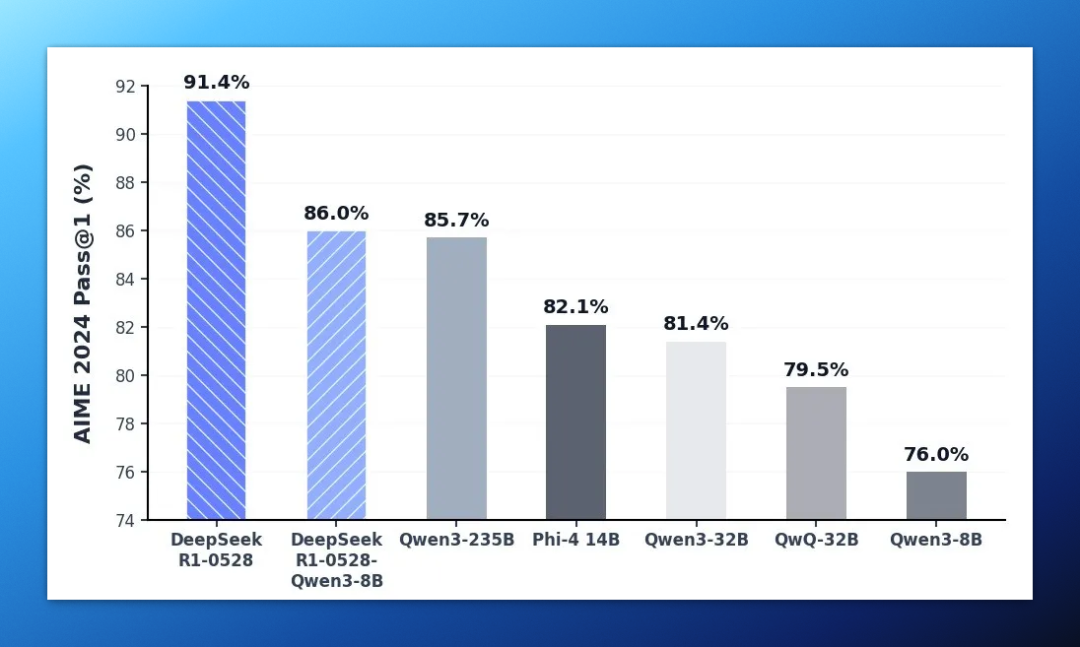
这次更新还有一个特别有意思的细节:DeepSeek 用新版 R1 的“思维链”去蒸馏了一版 Qwen3-8B 小模型,命名为:
DeepSeek-R1-0528-Qwen3-8B
然后在数学测试 AIME 2024 上,这个只有 8B 的小模型,表现超过 Qwen3-8B 本体,还接近 Qwen3-235B 思维版,妥妥一波“以大教小”。
这说明新版 R1 在“思维链演示”和“教学价值”上,已经具备了高质量“教师模型”的基础。
05|部署与使用资源
如果你想自己部署或深入接入新版 R1,可以参考以下链接。
-
模型开源权重下载(HuggingFace):https://huggingface.co/deepseek-ai/DeepSeek-R1-0528 -
官方 API 使用文档:https://api-docs.deepseek.com/zh-cn/guides/reasoning_model

结语:更聪明的 R1
如果你问我这波更新值不值得试,那我会说:很值得。
虽然不是 R2,但这次 R1-0528 的升级把原本 R1 模型的所有短板几乎都“轻补”了一遍。
它还没强到碾压 o3,但也已经不是几个月前那个“高幻觉、不会调用工具”的 R1 了。
我是木易,一个专注AI领域的技术产品经理,国内Top2本科+美国Top10 CS硕士。
相信AI是普通人的“外挂”,致力于分享AI全维度知识。这里有最新的AI科普、工具测评、效率秘籍与行业洞察。
欢迎关注“AI信息Gap”,用AI为你的未来加速。
(文:AI信息Gap)