

大型语言模型(LLMs)通过大规模强化学习(RL)展现了卓越的推理能力。然而,利用RL算法赋能LLMs进行有效的多工具协作推理仍然是一个开放性挑战。为了解决这一问题,我们提出了 Tool-Star ,一个基于强化学习的框架,旨在引导大模型逐步高效掌握调用多种工具的能力,从而提升其处理复杂推理任务的泛化性。我们的实验表明,Tool-Star框架能够在复杂计算型推理任务(AIME24、AIME25、MATH、MATH500等),以及知识型推理任务上(WebWalker、MuSiQue、Bamboogle等)同时取得卓越的性能。我们相信Tool-Star为模型多工具协同推理的研究方向奠定了坚实基础。

论文标题:Tool-Star: Empowering LLM-Brained Multi-Tool Reasoner via Reinforcement Learning论文链接:https://arxiv.org/abs/2505.16410代码仓库:https://github.com/dongguanting/Tool-Star开源数据:https://huggingface.co/datasets/dongguanting/Tool-Star-SFT-54K开源模型:https://huggingface.co/dongguanting/Tool-Star-Qwen-3B
目前不仅在X上收获了很高的关注度,同时荣登当日Huggingface Daily Paper第三名🥉
在最近的研究中,大语言模型通过大规模的强化学习展现出了卓越的能力。然而对于真实世界的复杂任务,仅靠模型本身的推理能力可能很难完成。工具调用被视为一种协助模型推理过程的有效手段。但是现有推理模型调用工具的研究并不充分,它们大部分聚焦于工具调用Prompt设计与强化学习激发模型单工具调用能力,对于多工具调用的研究仍待完善。因此,我们在研究中想解决以下两个问题:
-
• 如何赋予大模型多种工具协同推理的能力? -
• 如何在保证模型推理能力的同时平衡工具调用成本?

-
• Tool-Star框架允许模型在训练阶段调用三种不同的工具(代码编译器、搜索引擎、网页浏览代理),并在测试推理阶段提供了额外的三种工具(代码调试器、回溯工具、精炼工具)以让模型在多工具辅助下完成推理任务。 -
• 为了解决工具使用数据稀缺的问题,我们提出了一种通用的工具推理数据合成流程,该流程结合了双重工具调用数据采样方法,并进一步引入了工具调用正则化与难度感知数据划分阶段,自动化合成高质量的工具调用数据集。 -
• 为了充分激发模型在多工具协作中的能力,我们创新性地提出了一个两阶段的训练框架:(1)我们引入冷启动监督微调策略,让模型具有初步的探索推理能力;(2)在第二阶段,我们引入了一种全新的自我批评奖励微调方法,在经典的GRPO训练中引入了奖励感知训练,以更促进模型对奖励机制的建模。 -
• 我们在十种具有挑战性的推理数据集(包括计算型推理任务和知识型推理)上充分验证了Tool-Star的有效性,并做了大量的分析实验以验证我们方法的泛化性。
-
• 直接基于提示词工程的方法:严重依赖于模型已有能力,在小模型上很难实现。 -
• 基于单工具训练的方法:只能让模型专注于单方面的任务,缺乏泛化性。 -
• Tool-Star方法:在多个工具调用任务上进行训练,同时提升泛化性和准确性。
在本文中,针对工具的使用以及任务的复杂性,我们设计了一共六种工具供模型调用:
训练阶段
-
• 搜索引擎:执行搜索查询以检索相关信息,支持本地和基于网络的搜索模式。 -
• 网页浏览:通过访问URL解析网页搜索结果,提取相关内容,并总结关键信息以响应查询。 -
• 代码编译器:在沙箱环境中执行LLM生成的代码片段,根据代码的正确性返回执行结果或错误信息。
推理阶段
-
• 代码调试器:当代码执行出错时,调用一个与推理模型同尺寸的模型修正错误。 -
• 工具调用回溯:当代码调试出错时,回溯到agent发起工具请求前的部分,让agent重新输出。 -
• 推理精炼器:当推理路径过长时,调用额外的模型对推理路径进行精炼。
借助多种工具的帮助,Tool-Star能够在通用推理任务上表现优异。
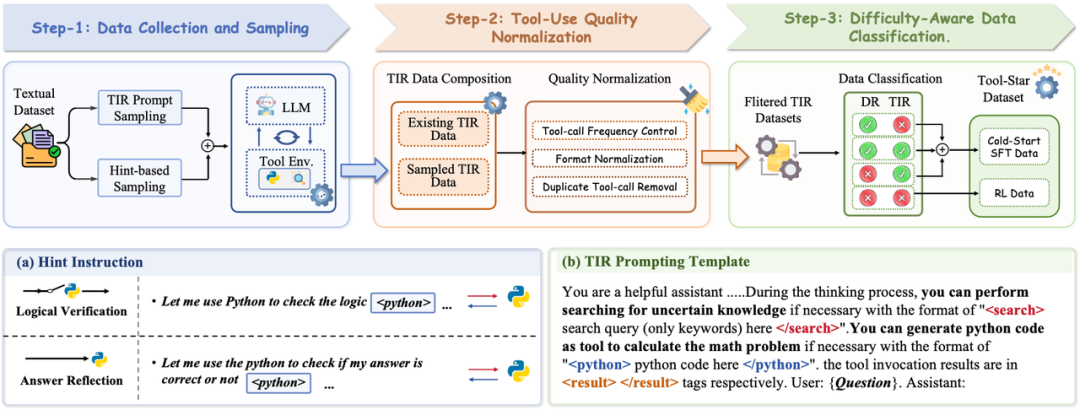
-
• 采用prompting-base的方法,直接引导模型对训练集的问题进行调用工具推理。 -
• 采用hint-base的方法,在纯文本推理链中插入特殊token刺激模型调用工具推理。
工具调用正则化:基于合成的工具调用数据,我们采用以下准则进行不合理样本过滤:
-
• 去除工具调用次数过多的样本——保证推理链路的正确高效性。 -
• 去除调用内容多次重复的样本——保证推理链路的简洁精准性。 -
• 去除不符合格式要求的样本——保证推理链路的格式正确性。
难度感知数据划分:我们根据直接推理(DR)与工具调用推理(TIR)的结果,设计四维准则划分由易到难的划分冷启动微调与强化学习的数据集:
-
• DR对,TIR错:我们选择DR的数据作为冷启动微调数据,因为DR必要。 -
• DR对,TIR对:我们选择DR的数据作为冷启动微调数据,因为TIR并非必要。 -
• DR错,TIR对,我们选择TIR数据作为冷启动微调数据,因为TIR必要。 -
• DR错,TIR错:两种模式均无法答对,我们将这部分视作困难样本,在强化学习阶段进一步探索与泛化。
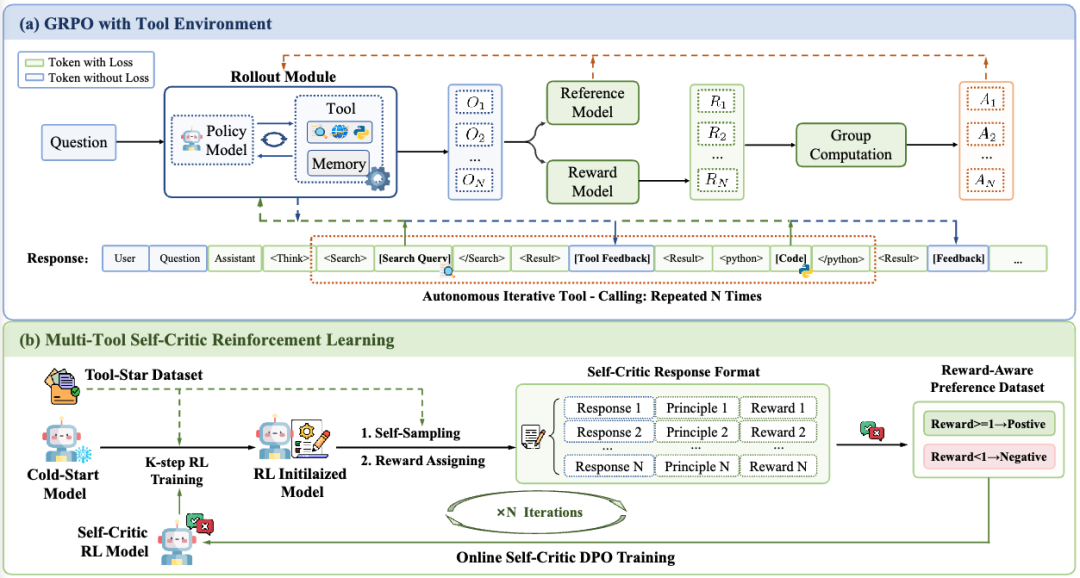
-
• 冷启动微调阶段:我们使用构造的简单样本让模型快速熟悉工具调用的推理格式。
-
• 自校准的强化学习阶段: -
• 多工具调用Roll-out模块:支持模型在采样过程中通过自主解码不同的特殊token来获得多样化的工具反馈。 -
• Memory机制:对于重复的工具调用请求,我们设计memory模块直接返回结果,减少工具调用开销。 -
• 使用GRPO进行RL训练:基于筛选的RL训练数据进行强化学习训练。 -
• 层级奖励机制:输出格式错误时给予严格惩罚,格式与结果正确性给予奖励,对于同时调用搜索引擎和Python编辑器会给额外的奖励。
-
• Self-Critic机制实现reward感知训练: 综上所述,我们模型在冷启动后,每K步的RL训练就会搭配一次reward感知训练,如此反复可以on-policy地深化模型的奖励格式遵循能力。
-
• 当GRPO进行K步数后,从训练集中随机采样出一批训练数据,并使用RL模型拒绝采样出若干回复。 -
• 使用reward函数对每个样本的若干推回复后面拼接对应样本的奖励准则与分数(例如,该样本格式正确,但是答案错误,因此奖励分数为0)。 -
• 我们根据奖励分数筛选出正负样例,并使用DPO方法在正负样本对上进行奖励感知训练。
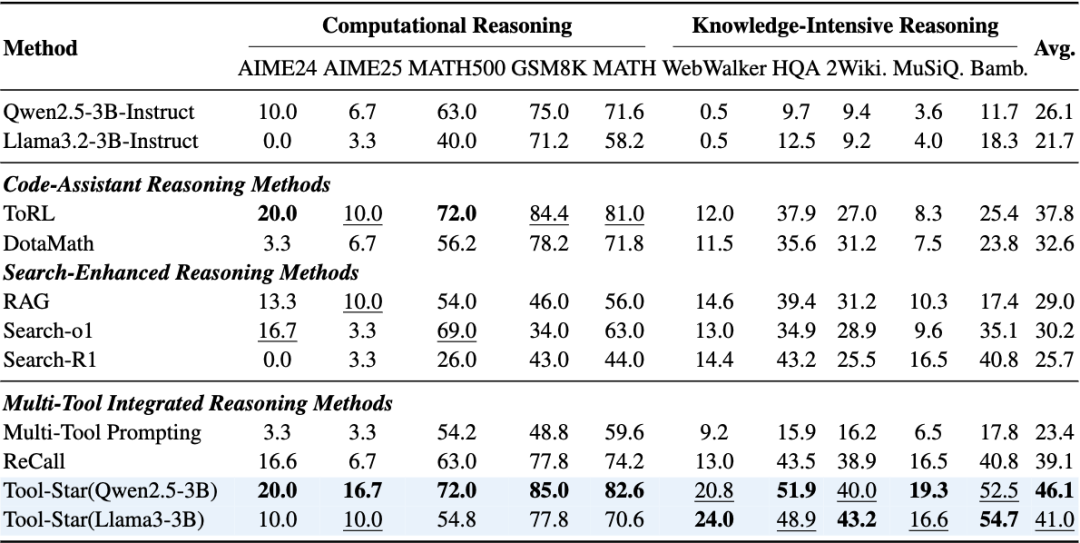
为了充分评估Tool-Star的泛化性和高效性,我们考虑以下两种测试集:
-
• 计算型推理任务:评估模型的计算推理能力,包括AIME24,AIME25,MATH500,GSM8K,MATH。 -
• 知识密集型推理任务:评估模型结合外部知识推理的能力,包括WebWalker,HotpotQA,2WIKI,MisiQue,Bamboogle。
从实验结果可以发现:
-
• 单纯基于prompt方法的局限性:对于诸如Search-o1或者直接基于多工具Prompting的方法,模型难以理解复杂的任务需求,同时主动调用工具的能力很差,从而性能表现较低。 -
• 单工具调用的RL方法泛化性较差:单纯针对搜索任务的强化学习模型(Search-R1)或者单纯针对数学任务强化学习模型(ToRL)在各自的领域都有着较好的表现,但是难以在两类推理任务上同时取得泛化能力。 -
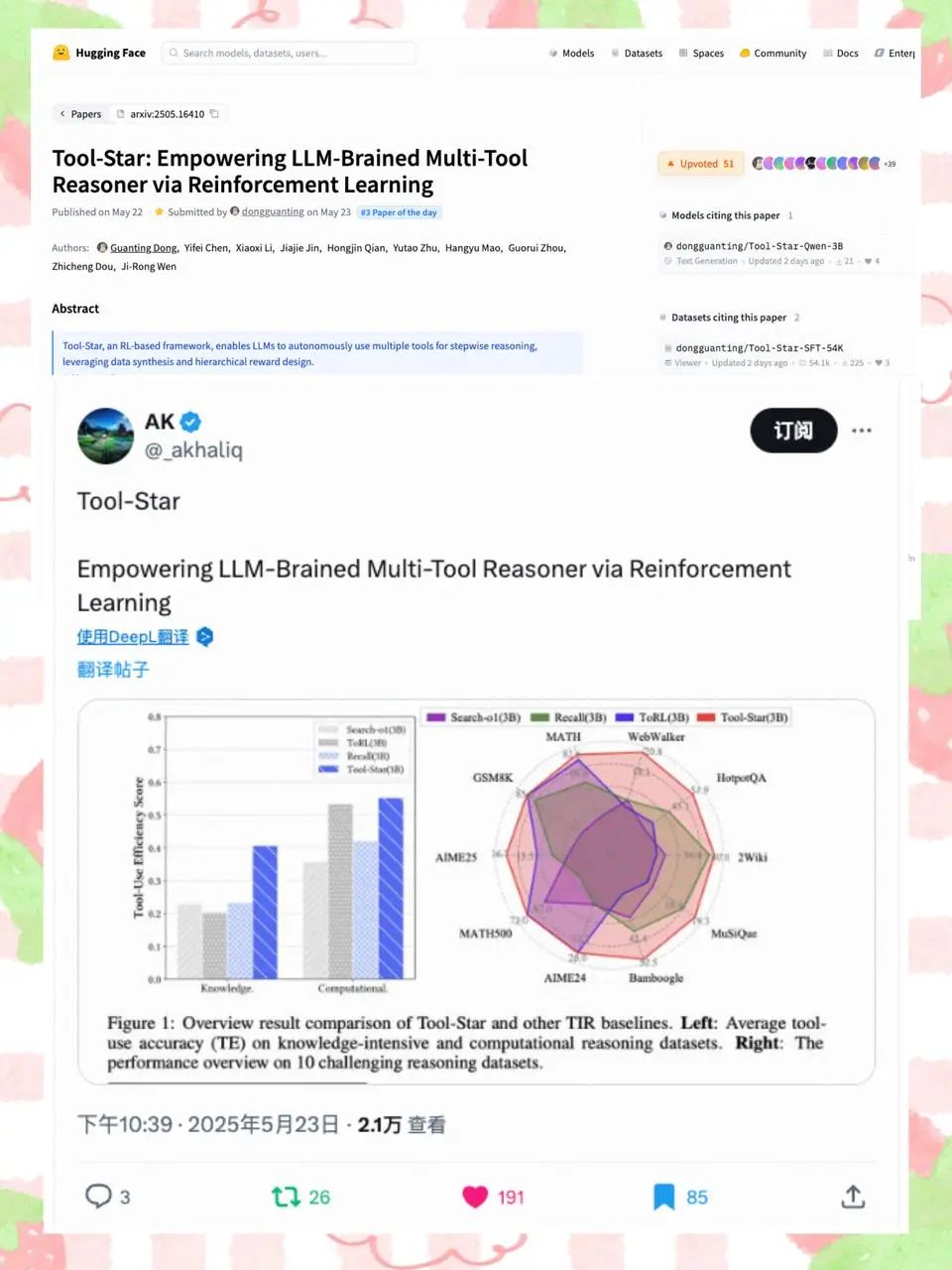
• Tool-Star展示了强大的推理能力以及稳定的泛化性:Tool-Star稳定地优于单一和多工具基线,在10个数据集上平均准确率超过40%,同时在子任务上也保持了强大竞争力表现。这些结果凸显了Tool-Star的高效性与通用性。
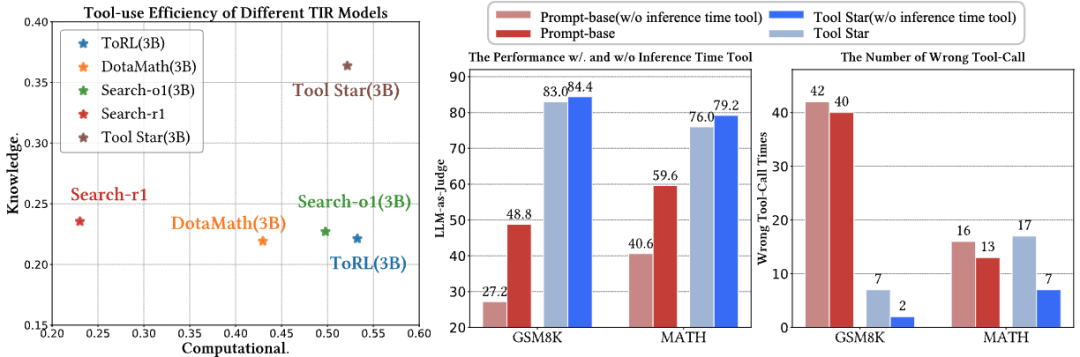
我们进行实验以验证Tool-Star的高效性与推理工具的有效性,我们进行了如下实验分析:
-
• 工具调用效率大幅领先:我们计算了Tool-Star方法和其他方法的工具使用效率,即当调用工具时回答问题的准确性。Tool-Star方法无论是在数学推理任务上还是知识密集型任务上,都取得了优秀的效果。 -
• 代码调试器帮助提升性能:相较于直接调用工具推理,引入Python调试器的方法能够很好地提升Tool-Star在数学推理任务上的能力。 -
• 代码调试器提升了工具使用效率:当引入Python调试器的时候,Tool-Star编写的代码出错的概率大大降低,这凸显了Python调试这一工具使用的必要性。
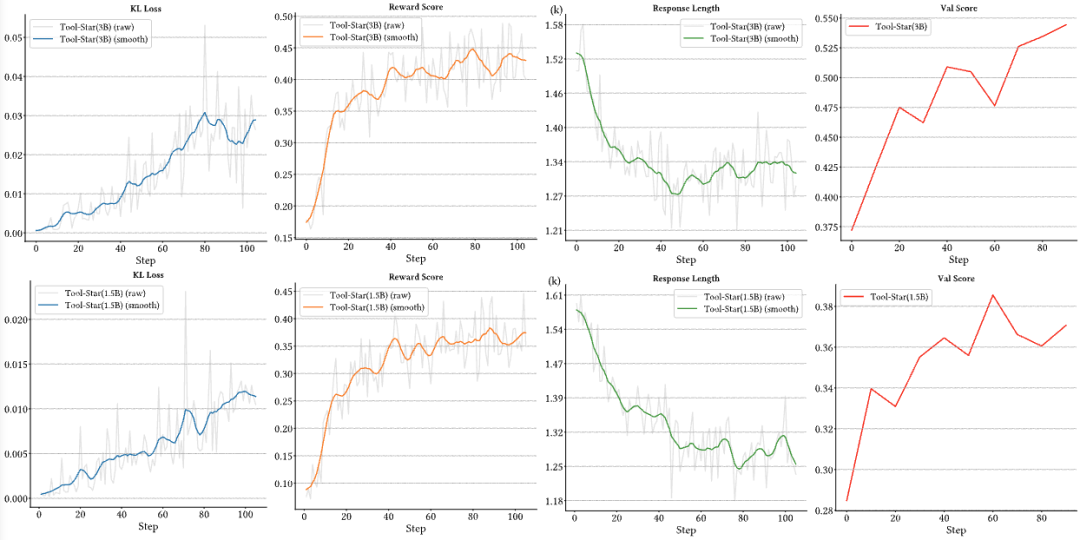
我们记录了在RL训练过程中同时监控了诸如奖励分数、相应长度的变化:
-
• 奖励分数逐渐提高:随着训练的进行,无论是训练集的奖励分数还是验证集的奖励分数,总体变化趋势都是在提高的,这充分说明Tool-Star的RL训练稳定有效。 -
• 输出长度稳定收敛:随着训练的进行,模型输出长度稳定收敛,也并不存在“顿悟时刻”。这说明冷启动让模型在RL阶段快速收敛到了更优工具调用的范式上,增强了RL阶段的稳定性。
Tool-Star框架成功地赋予了大模型多工具调用的能力,解决了模型在知识密集型真实世界任务中和数学推理型任务的局限性。通过多种工具适时调用,Tool-Star使模型推理能够在多种任务上生成稳定输出。未来,为持续提升TIR推理模型的能力,仍有很多方向值得探索:
-
• 多模态TIR任务:Tool-Star基于文本推理模型,难以处理图像等其他模态的信息。未来可以扩展到图像、视频等多模态内容的深度研究,在此任务重探究模型的多工具调用能力。 -
• 多工具扩展:Tool-Star成功展现了模型的多工具调用的潜能。未来可以通过工具学习来不断优化工具使用策略,并扩展更多工具,来支持更复杂的任务。
(文:PaperAgent)