

作者 | Kino
编辑 | 张洁
想用AI整活的玩家又有“新玩具”了。
这两天,腾讯混元最新开源了一款语音驱动的数字人模型:HunyuanVideo-Avatar。
只要上传一张图片和一段音频,就能让图中的人物说话、唱歌,生成一段音画同步、表情自然的高保真视频。
当然,国内外与HunyuanVideo-Avatar有相似能力的产品已有不少,此前“AI新榜”也进行过一些测试。
不过,考虑到腾讯官方表示“HunyuanVideo-Avatar在主体一致性和音画同步上,已经达到业内领先水平,超越现有开源和闭源解决方案;在动态表现和肢体自然度方面,也和多个闭源方案打成平手”,并放出效果不错的demo:
于是我们还是决定上手试试。
过去,AI数字人技术主要集中在让嘴动起来,但嘴型同步难、表情死板、头和身体比较僵硬。由于可控性有限,使用场景自然也受限。
但HunyuanVideo-Avatar称能够支持半身乃至全身驱动,让数字人视频不再局限于面部特写,从而大大提升真实感和表现力。
上手情况如何,我们来看一些案例。
ps. 目前HunyuanVideo-Avatar的单主体能力已经开源,并在腾讯混元官网(https://hunyuan.tencent.com/)开放体验。

实测混元语音数字人模型:
开源有诚意,但效果不够惊艳
HunyuanVideo-Avatar支持多风格、多物种与多人场景,包括赛博朋克、2D动漫、中国水墨画,以及机器人、动物等。
你可以上传音频文件,也可以直接输入文本,由系统提供的14种音色进行朗读,支持语速调节。不过目前系统只能处理和生成14秒以内的音频,超时会自动裁剪。
生成过程相对较慢,从提交到出结果大约需要30分钟-1个小时,对心急想要即时反馈的玩家不那么友好。
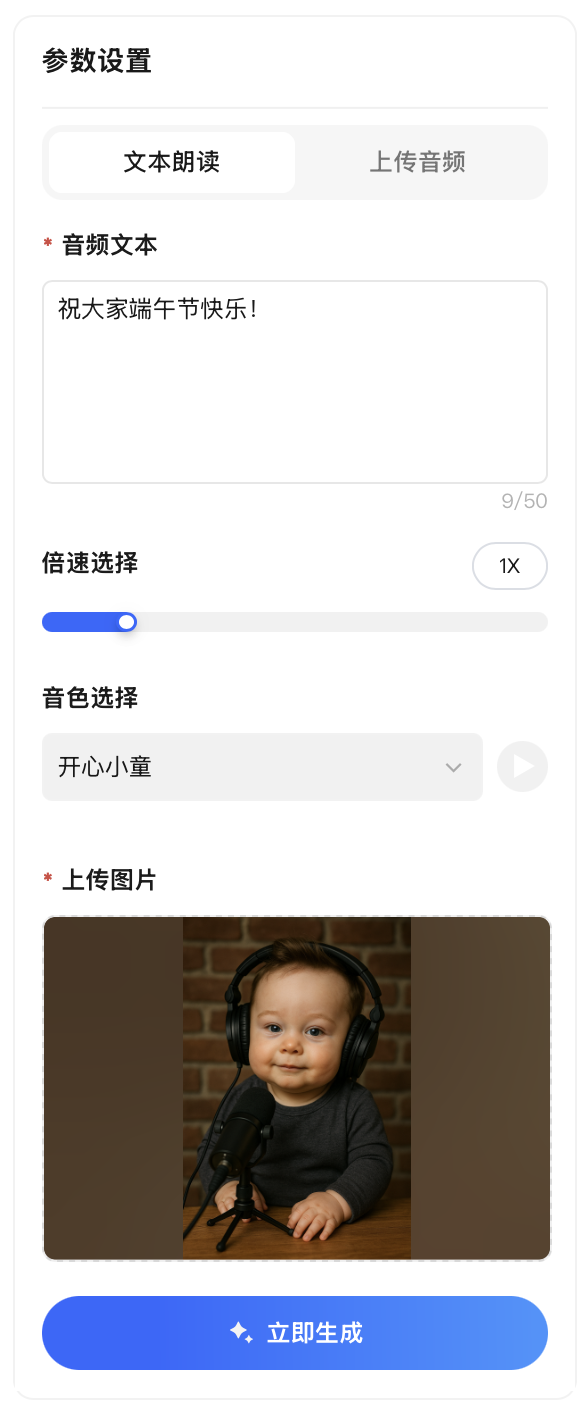
我们实测下来,用一句话总结就是:图片和音频质量直接影响成片效果,建议尽量选择五官清晰的正脸照,语音也尽量吐字清晰,这样生成出来的效果大概率不会差。
先说一个省流版整体感受:HunyuanVideo-Avatar的主体一致性和表情自然度确实都还不错;音画整体同步,但嘴型时有偏差,嘴部、牙齿等细节有瑕疵;动作幅度偏小,除了头部运动和上本身的呼吸起伏外,很少有其他肢体动作,运动过程一些细节有时会出现畸变。
我们先上传了一张AI生成的马斯克婴儿照,搭配“开心小童”音色,朗读“祝大家端午节快乐!”。
再来来试试让宠物、卡通角色和虚拟形象说话和唱歌。
我用AI生成了一张金丝熊在埃菲尔铁塔下的自拍照,配上朗读文本:“人,鼠鼠我呀,已经到法国啦。”
嘴型匹配度还是挺高的,但在说话过程中,金丝熊标志性的两颗门牙出现了模糊和变形。
让“前顶流”Loopy唱现任顶流拉布布的“拉布布之歌”,效果意外地还不错,唱歌过程中,Loopy呆萌的神情和脸型得到了比较好的保持,摇头晃脑的动作也自然流畅。
乐高小人报道上海乐高乐园开园:
让神探夏洛克唱中文Rap《因果》:“老天保佑金山银山前路有,老天教唆别管江湖龙虎斗。”
表情自然,口型也基本准确和同步,但除了夏洛克上本身的呼吸起伏外,没有其他肢体动作,少了点表现力。
女孩抱吉他盘腿坐在草地上弹唱《夏天的风》:
《老友记》中Joey的表情包,搭配《The Office》的名场面,这个“演技”不说是AI生成的还以为是原片呢:

美剧《亢奋》 Cassie的绝美流泪剧照,配上一段歌曲音频,秒变音乐剧。生成的视频自然延续了原图的悲伤情绪,表情和眼神都很自然生动,嘴型也基本同步:
目前,HunyuanVideo-Avatar已经在多个腾讯系产品上线应用。在QQ音乐中,用户播放“AI力宏”(腾讯音乐与王力宏工作室联手打造的“全AI”歌手)歌曲时,可以看到虚拟人物实时同步演唱动作;酷狗音乐的绘本功能中也融入了AI虚拟人讲故事的能力;全民K歌则支持用户上传个人照片,自动生成专属唱歌MV。
据介绍,在底层技术架构方面,HunyuanVideo-Avatar基于腾讯混元视频大模型与MuseV技术融合开发,具备多模态理解能力,可自动识别图像中的人物环境信息及音频情感内容,生成高度匹配的视频片段。

还有哪些玩家在卷同一赛道?
实际上,和HunyuanVideo-Avatar能力相似的同类产品,已经在国内外相继上线了不少。
海外有HeyGen、D-ID、Synthesia、Hedra、Meta的MoCha等;国内也有阿里的EMO和Animate Anyone、字节的OmniHuman-1、快手的LivePortrait等等。
其中,字节OmniHuman-1采用的是音频+图片的驱动方式,而LivePortrait则是通过参考视频+图片的驱动方式来生成对口型视频。
这类AI驱动的数字人技术,除了在直播带货、电商营销与广告、影视动画、游戏等行业的落地应用外,也是社交媒体内容创作的热门趋势。
阿里早前推出的Animate Anyone和Emote Portrait Alive(简称Emo)两款人物动作和表情生成框架,被整合进“全民舞台”App中,制造了一波一键让人物、宠物跳舞、唱歌的AI视频创作热潮。
MoCha是Meta今年4月发布的一款AI数字人生成模型,支持通过文本+语音输入,生成电影级别的数字人说话、唱歌视频,能控制脸部表情、嘴型动作、身体姿态,并支持多角色对话与互动,画面表现从近景到中远景都有。
跟之前只盯着脸的模型不同,MoCha能从各种角度渲染全身动作,包括嘴型同步、手势,还有多角色间的互动,系统会根据对话内容生成上半身的动作和手势,以配合台词。



来源:https://congwei1230.github.io/MoCha/
不过需要说明的是,MoCha当前仍处于技术展示阶段,尚未开放公测。Meta只在官网放了一些超强demo和技术细节,效果虽惊艳,但离实际使用还有距离,所以并非是现成可用的更优解。
相比之下,像HunyuanVideo-Avatar这类开源可直接使用的工具,虽然可能在生成质量上与MoCha等闭源模型还有差距,但对于很多企业和对创作者来说或许更具现实意义。
ps. 假期就要来了,祝大家端午安康~!



「
(文:AI新榜)