
编辑:+0、张倩
GPT 系列模型的记忆容量约为每个参数 3.6 比特。
语言模型到底能记住多少信息?Meta、DeepMind、康奈尔大学和英伟达的一项测量结果显示:每个参数大约 3.6 比特。一旦达到这个极限,它们就会停止记忆并开始泛化。
长期以来,记忆与泛化之间的模糊性一直困扰着对模型能力和风险的评估,即区分其输出究竟源于对训练数据的「记忆」 (对其训练数据分布的编码程度) ,还是对潜在模式的「泛化」理解 (将理解扩展到未见过的新输入)。 这种不确定性阻碍了在模型训练、安全、可靠性和关键应用部署方面的针对性改进。
这就好比我们想知道一个学生考试得了高分,是因为他真的理解了知识点(泛化),能够举一反三,还是仅仅因为他把教科书上的例题和答案都背下来了(记忆)。
基于此,研究团队提出了一种新方法,用于估计一个模型对某个数据点的「了解」程度,并利用该方法来衡量现代语言模型的容量。

-
论文标题:How much do language models memorize?
-
论文地址:https://arxiv.org/pdf/2505.24832
研究团队从形式上将记忆分为两个组成部分:
-
非预期记忆 —— 模型包含的关于特定数据集的信息;
-
泛化 —— 模型包含的关于真实数据生成过程的信息。
通过消除泛化部分,可以计算出给定模型的总记忆量,从而估计出模型容量:测量结果估计,GPT 系列模型的容量约为每个参数 3.6 比特。
研究团队在规模不断增大的数据集上训练语言模型,观察到模型会持续记忆,直到其容量饱和,此时「顿悟」(grokking)现象开始出现,非预期记忆随之减少,模型开始泛化。也就是说,在海量数据上训练的语言模型根本不可能记住所有训练数据,因为根本没有足够的容量。

研究团队训练了数百个参数量从 50 万到 15 亿不等的 Transformer 语言模型,并由此提出了一系列关于模型容量、数据规模与成员推断之间关系的 scaling law。
研究团队还借鉴了「信息论之父」 Claude Shannon 1953 的一项重要工作《The Lattice Theory of Information》的一些理论。该论文将他早期关于信息论中熵和信道容量的概念,与数学中的格理论联系起来,为理解和处理复杂信息系统提供了新的视角。
这项研究激发了社区对蒸馏、量化、模型安全等方面的思考。


两种「记忆」:非预期记忆和泛化
在论文中,作者希望找到一个方法来量化模型对特定数据点的记忆程度,并且这种记忆定义要满足以下几点:
-
与泛化区分开;
-
能够针对具体的数据样本;
-
不依赖于具体的训练算法;
统计学视角下的记忆定义
作者从信息论的角度出发,利用「互信息(Mutual Information)」来定义记忆。
在论文中,大写字母(例如 X、Θ)用来指代随机变量,小写字母用来指代随机变量的实例(例如 x ∼ X 和 θ ∼ Θ)。
信息论已经为随机变量发展出了被广泛理解的信息概念。对于随机变量 X,通常使用 H (X),即 X 的熵,来定义 X 中存在的信息量。此外,对于两个不同的随机变量 X、Y,可以将 X | Y 定义为在固定 Y 后 X 中剩余的不确定性。定义了这个量之后,现在可以通过从总信息中减去剩余信息来测量 X 和 Y 之间的互信息:I (X, Y) = H (X) − H (X | Y)。
现在假设有一个机器学习 pipeline。作者有一个关于底层模型的先验 Θ,它捕获了作者的数据集分布 X。作者有一个学习算法 L,它将来自 X 的样本映射到训练好的模型 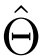 。为了理解有多少关于 X 的信息存储在 中,作者可以使用互信息的概念:
。为了理解有多少关于 X 的信息存储在 中,作者可以使用互信息的概念:
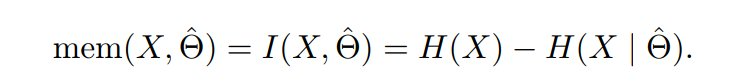
注意这捕获了存储在 中的关于 X 的所有信息。正如前面所讨论的,记忆的概念需要同时考虑泛化。因此,当测量非预期记忆时,作者只对 X | Θ 中存在的信息感兴趣,这是在固定 Θ 后 X 中剩余的不确定性。
因此,可以将非预期记忆化定义为:
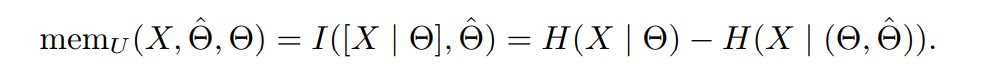
然后泛化(或预期记忆)应该是:
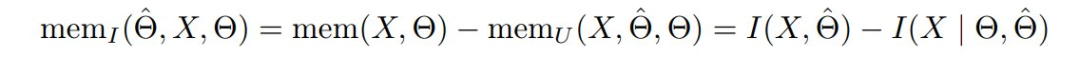
现在作者已经定义预期和非预期记忆的概念,作者将注意力转向实际测量它们。让作者首先陈述一个能够非预期记忆的命题:
命题 1(非预期记忆的 Super-additivity)。 假设 X = (X_1, . . . , X_n) 是 n 个独立同分布样本的数据集。作者有:
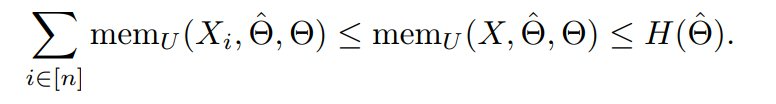
这个命题表明,为了测量数据集级别非预期记忆的下界,可以将每个样本的记忆相加。另一方面,训练模型本身的信息内容的熵作为非预期记忆的上界。这个命题的另一个含义是,非预期记忆应该随数据集大小 scale,但不能超过模型的总容量。
用 Kolmogorov 复杂度测量非预期记忆
到目前为止,论文对记忆和泛化的定义使用的是基于「熵」的信息概念。这意味着该定义只能用于随机变量。这在测量记忆方面带来了很大挑战。在记忆定义中,所有的变量都是单例。作者有一个单一的底层模型 θ,作者有一个单一的数据集 x = (x_1, . . . , x_n),作者有一个单一的训练模型  。使用单个样本测量底层变量的熵(更不用说条件熵)是不可能的。
。使用单个样本测量底层变量的熵(更不用说条件熵)是不可能的。
为此,论文转向另一种基于压缩的信息概念,然后展示这种概念如何密切近似上面定义的记忆概念。Kolmogorov 复杂度将字符串 x 的信息内容定义为 H^K (x),即 x 在给定计算模型中的最短表示长度。类似地,作者可以将剩余信息 x | θ 定义为当作者有 θ 作为参考时 x 的最短表示。而 x | θ 的信息内容,记为 H^K (x | θ),是这种描述的长度。然后,作者可以用类似的方式定义互信息:
定义 2(Kolmogorov 复杂度)。设 f 是一个任意的计算模型,它接受一组输入并返回一个输出(例如通用图灵机)。相对于计算模型 f 的 x 的最短描述定义为 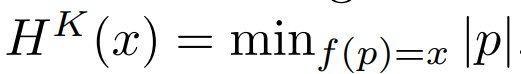 。同样,x 相对于另一个字符串 θ 的 Kolmogorov 复杂度定义为
。同样,x 相对于另一个字符串 θ 的 Kolmogorov 复杂度定义为 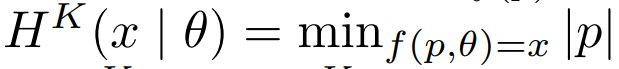 。论文通过
。论文通过 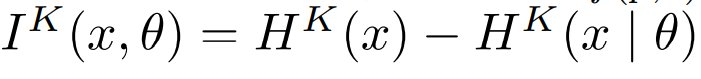 定义 x 和 θ 之间的 Kolmogorov 互信息。假设输入是比特串,|p | 是输入的比特长度。
定义 x 和 θ 之间的 Kolmogorov 互信息。假设输入是比特串,|p | 是输入的比特长度。
定义 3(Kolmogorov 记忆)。设 θ 是一个近似数据真实分布的参考模型,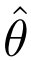 是在数据集 x = (x_1, . . . , x_n) 上训练的模型。对于每个 x_i,论文将 x_i 在 中的记忆定义为
是在数据集 x = (x_1, . . . , x_n) 上训练的模型。对于每个 x_i,论文将 x_i 在 中的记忆定义为 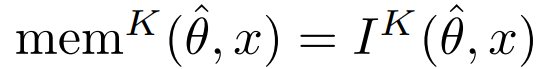 。论文还将记忆的预期与非预期变体定义为:
。论文还将记忆的预期与非预期变体定义为:
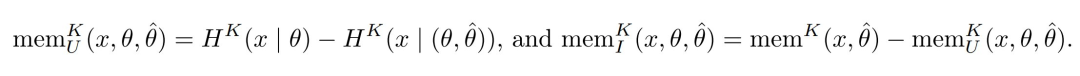
已知 Kolmogorov 复杂度和 Shannon 熵之间存在联系。这些结果指出了两个概念之间的概念联系,并暗示 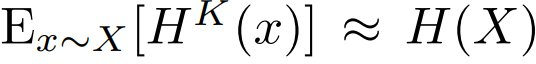 。有趣的是,这意味着论文中的 Kolmogorov 记忆概念密切近似 Shannon 记忆。
。有趣的是,这意味着论文中的 Kolmogorov 记忆概念密切近似 Shannon 记忆。
命题 4。设 X = (X_1, . . . , X_n) 是由真实模型 θ 参数化的独立同分布数据集分布。设 L 是将 X 映射到 的训练算法。假设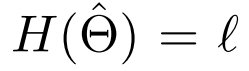 且
且 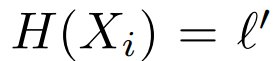 。那么有
。那么有
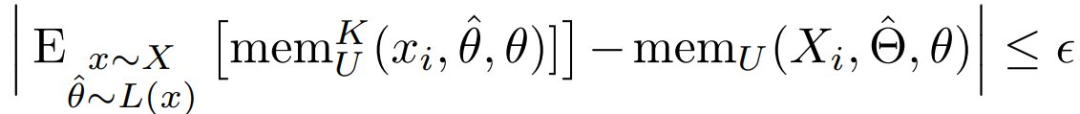
对于某个独立于 θ、ℓ、ℓ’ 和 n 的常数 ε。此外,有尾界:
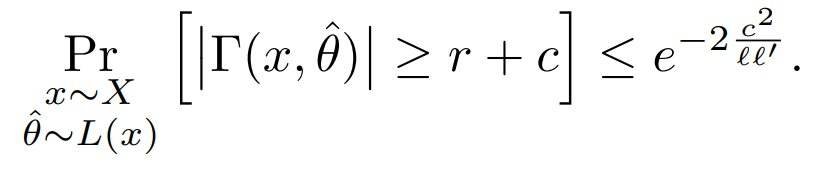
用似然度估计 Kolmogorov 复杂度
确定了 Kolmogorov 记忆概念后,现在描述如何在不同设置中估计 H^K。注意,Kolmogorov 复杂度的精确计算是已知不可计算的(其判定版本是不可判定的)。然而,仍然可以使用最佳可用压缩方案来近似它。在论文中, 作者总结了如何近似定义中的每个项。
模型记忆容量
非预期记忆为作者提供了一种有原则的方法,用以衡量模型 θ 对某一数据点 x 所掌握的确切比特数。
如果将数据集中每个数据点的信息加起来,就可以衡量模型对整个数据集所掌握的总比特数。并且,在由于每个数据点完全独立而无法进行泛化的情况下,可以通过对每个数据点的非预期记忆进行求和来估计给定模型 θ 的容量。
定义模型容量
作者首先对特定语言模型 θ 的这种记忆容量概念进行形式化。容量是指在 θ 的所有参数中可以存储的记忆总量。
定义 5 (容量):设 X 为一个分布, L:X→Θ 为一个学习算法。作者将学习算法 L 的容量定义为:
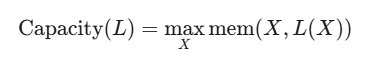
当达到模型容量时,mem (X,L (X)) 将不再随数据集大小的增加而增加。在实践中,作者可以通过在不同大小的 X 上训练至饱和,并计算最大记忆量来计算容量。
用合成序列测量模型容量
作者测量了 Transformer 语言模型的容量,目标是实例化多个数据集和分布,并在训练单个模型 θ 时测量它们所产生的记忆量。
然后,取所有数据集上的最大值来近似模型的容量。为了实例化数据集,每个标记都从一个预定义的标记集合中均匀采样,且与前面的标记无关。
为了近似 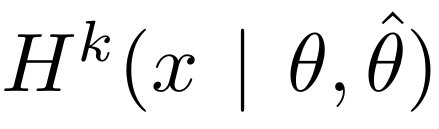 ,可以直接计算在训练好的模型下的熵,以计算以
,可以直接计算在训练好的模型下的熵,以计算以 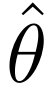 为条件的数据集的最短描述。将两者相减,可以近似得到非预期记忆
为条件的数据集的最短描述。将两者相减,可以近似得到非预期记忆 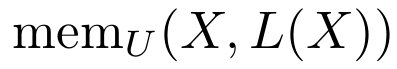 。由于采样数据的过程是完全随机的,因此在 中没有泛化信息可供存储,也就是说,
。由于采样数据的过程是完全随机的,因此在 中没有泛化信息可供存储,也就是说,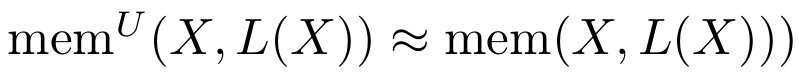 。
。
观察到当我们从均匀分布中采样合成序列时,可以精确地计算它们的香农信息。给定数据集大小 N,构建一个包含 N 个序列的数据集,每个序列包含 S 个标记。给定词汇表大小 V,可以通过 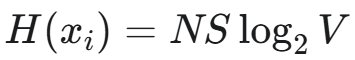 计算具有这些参数的数据集
计算具有这些参数的数据集  的总熵。然后,使用在
的总熵。然后,使用在 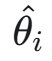 下的熵计算 的压缩形式,以计算编码长度,并将其用作
下的熵计算 的压缩形式,以计算编码长度,并将其用作 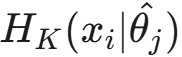 的近似值。接着,作者计算
的近似值。接着,作者计算 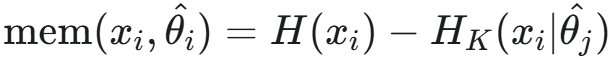 ,并将模型容量计算为所有数据集上的最大记忆量。
,并将模型容量计算为所有数据集上的最大记忆量。
实验
实验结果
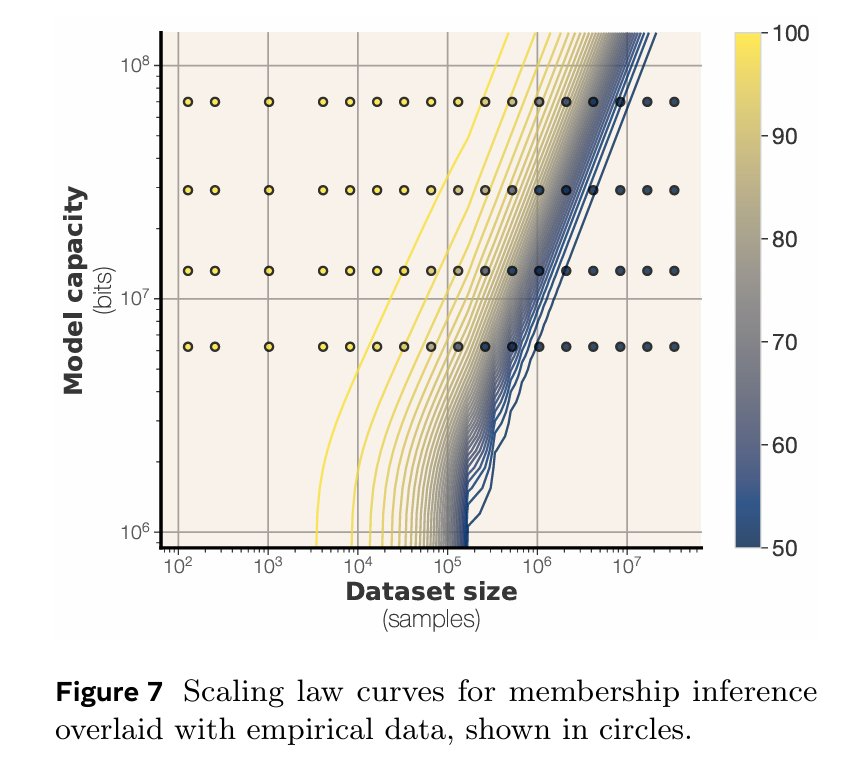
图 2 展示了不同模型规模和数据量下的记忆情况。这样,便可以将不同数据集规模 (x 轴) 下的非预期记忆量 (y 轴) 进行可视化,并按模型规模 (线条颜色) 分组。研究中观察到,一旦模型达到其容量上限,便会出现一个明显的平台期。当数据集足够大时,无论数据规模如何,模型的净记忆量都会达到一个上限。对于容量充足的模型而言,小型数据集会被完全记忆。
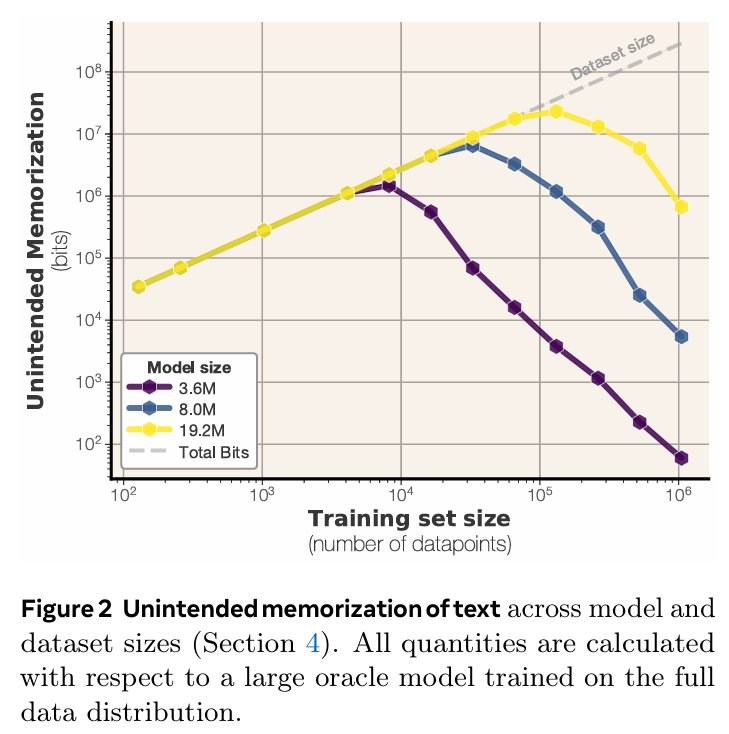
文中将每个模型的容量,估计为在所有数据集规模上测得的最大非预期记忆比特数。随后,在图 6 中将这一容量与模型规模进行了比较。有趣的是,即便在当前这种小规模实验中,也能观察到所测容量(即在所有数据集上测得的最大记忆量)与模型参数数量之间,存在一种非常平滑的对应关系。图 6 中呈现了这种关系:在当前的实验设置下,文中所述模型每参数能稳定记忆 3.5 至 3.6 比特的信息。
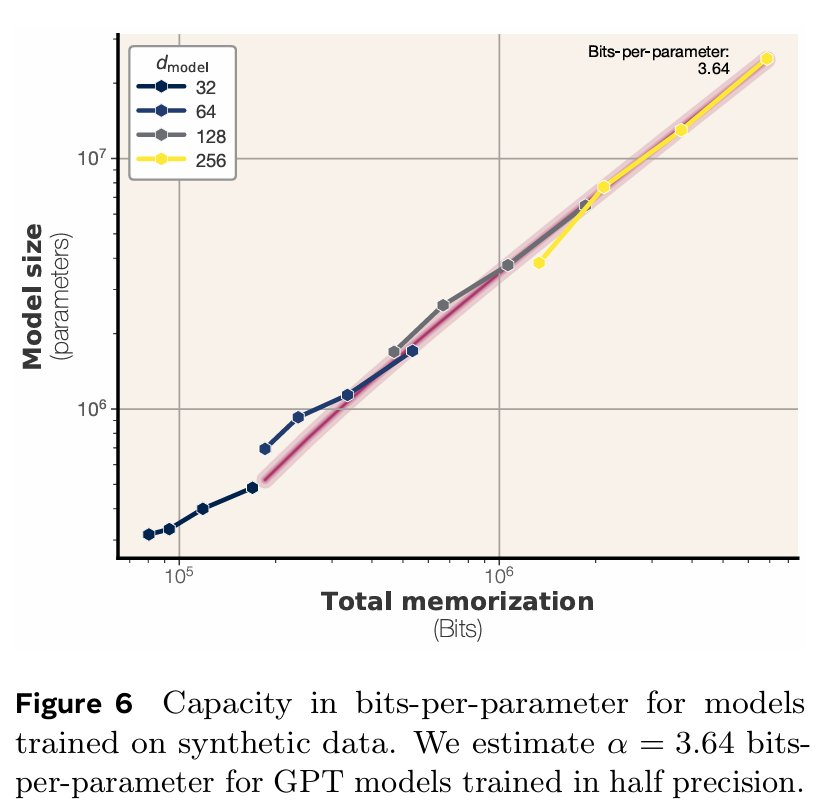
这印证了先前研究的发现,即事实性信息的存储量与模型容量成线性关系。文中的估计值略高于 Allen-Zhu & Li (2024) 的结果 —— 他们通过量化方法估计模型每参数约可存储 2 比特信息。
由于模型是通过梯度下降进行学习的,因此并不能保证找到全局最优解;所以,作者所测量的始终是模型容量的一个下限。作者进一步仔细研究了训练曲线,以分析一个包含 800 万参数的语言模型的收敛情况。图 6 展示了模型在训练过程中的收敛动态。
可以看到,对于样本量从 16,000 到 400 万的各个数据集,其记忆的比特数均在 3.56×10^6 到 3.65×10^6 的范围内。这表明测量结果在一个数量级内具有稳健性,并且作者认为,即使进行更多的训练迭代,模型能记忆的信息量也不会有显著增加。这一发现也印证了作者的假设:即模型的容量与参数数量大致成正比。
其中,两个最大的数据集(样本量分别为 400 万和 800 万),其收敛后的总记忆量分别为 2.95×10^6 和 1.98×10^6 比特。作者预计,若进行更多轮次的训练,这些模型所记忆的数据总量将继续向其容量上限增长。
精度如何影响容量?
一个很自然的问题是:对 α 的估计值,在多大程度上取决于语言模型训练时所用的精度?
事实上,尽管多数软件默认采用 32 位精度进行训练,但近期研究已表明,即使将语言模型量化到每参数不足 2 比特的水平,它们仍能保留大部分原有功用。
鉴于所有其他实验均在 bfloat16 精度下进行,作者特地在完整的 fp32 精度下重做了这些实验,以分析其对容量的影响。
结果显示,对于不同规模的模型,容量均略有提升,α 的平均值也从 3.51 比特 / 参数增加到了 3.83 比特 / 参数。
这一增幅远不及参数 θ 比特数实际达到的两倍增长,这表明,当精度从 bfloat16 提升至 float32 时,模型中增加的额外比特,大部分并未被用于原始数据的存储。
更多信息请参见原文。

©
(文:机器之心)