
小记:学会偷懒的AI,才是真智能
近日,快手Kwaipilot团队开源了KwaiCoder-AutoThink-preview自动思考大模型。这可不是一般的模型,堪称DeepSeek-V3 & R1合体,专门解决AI的过度思考问题。
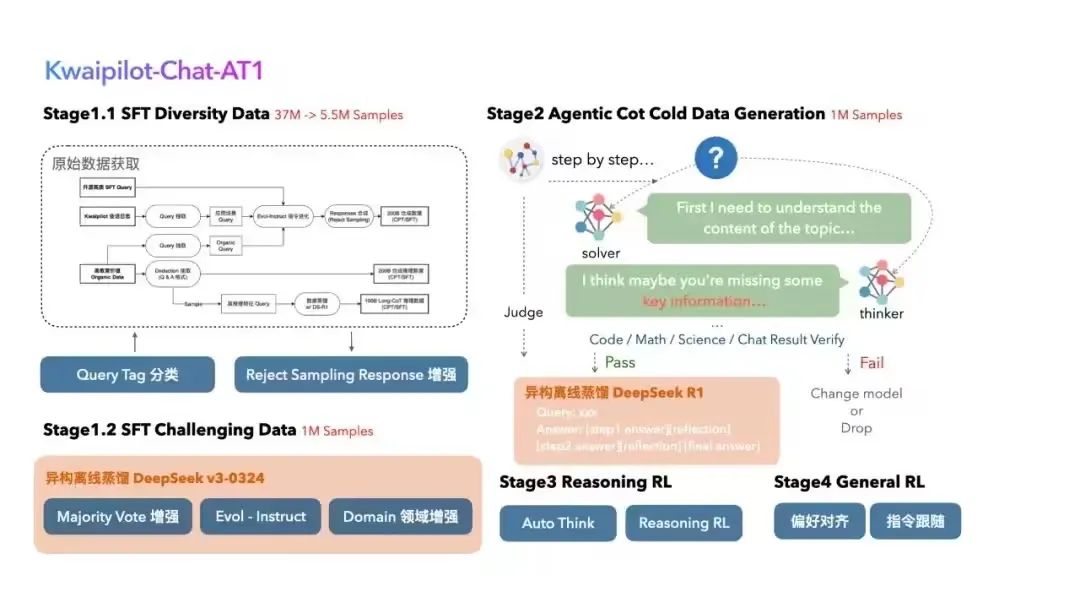
如今,很多科技公司都在拼模型的参数量和上下文长度,但快手却走了另一条路。让AI学会了“该思考时思考,该躺平时躺平”,个人觉得它会给大模型发展带来新的方向。
⋯ ⋯
大家有没有遇到过这样的情况,问AI一个特别简单的问题,回答却是无关紧要的。
比如“1+1等于几”,它却给你写了一大屏的推理过程。或者让你补全一段简单的代码,它却写了一大段不必要的注释。再或者问一个基础概念,它却给你生成了一篇长篇大论的论文。
这些都是AI过度思考的体现,不管问题难不难,AI都习惯性地开启深度推理模式。
快手的技术团队发现过度思考不仅浪费计算资源,还会让错误率上升。而且,随着大模型越来越复杂,这个问题也越来越严重。
在数学题里,简单的加减法被搞得特别复杂;在代码生成里,简单的API调用被写成冗长的代码;在知识问答里,直接回答问题变成了堆砌知识。当大家都忙着比谁的模型更大时,快手却发现了这个被忽视的效率问题。
⋯ ⋯
快慢双模的智能切换很关键,KwaiCoder-AutoThink的核心突破就是实现了双模思考。
快思考模式下,遇到简单问题,直接给出答案,不浪费时间。慢思考模式下,遇到复杂问题,再启动深度推理,确保答案准确。
神奇的是,这个模型能自己判断什么时候该用哪种模式。根据技术报告,在数学和代码任务中,开启自动思考模式后,性能提升了20分。就算不开启这个模式,因为底层推理优化,性能也有小幅提升。
实现这个能力的关键是团队创新的Step-SRPO强化学习框架,它的训练过程分三步。
• 阶段一:
模式分化,用一些特殊提示(比如省略号)引导模型分出快慢两种思维路径,先建立基础的模式切换能力。
• 阶段二:
能力强化,分别优化快思考和慢思考模式下的回答质量,让两种模式都能达到最佳效果。
• 阶段三:
路径精炼,把慢思考的思维链压缩,让它更聚焦;同时提高模式选择的精度,让切换更精准。
以上的训练方式需要很高的技术平衡能力,既要让“快思考”不草率,又要让“慢思考”不臃肿。最终效果很惊艳:处理简单问题时,响应速度提升了3-5倍。处理复杂问题时,排除干扰思维后,推理准确率反而提高了。
⋯ ⋯
AutoThink的成功其实延续了快手Kwaipilot团队一贯的高效益路线,也是低成本秘诀。
• 2024年12月:开源了OASIS代码嵌入模型,只用了5M数据,就在代码搜索任务中超过了OpenAI;
• 2025年1月:发布了KwaiCoder-23B,用1/30的成本训练出了SOTA级别的代码模型;
• 2025年4月:推出了SRPO强化学习框架,只用1/10的训练步数就复现了DeepSeek-R1的数学能力。
技术积累的延续性揭示了快手的独特研发哲学,当大家都痴迷于数据量和参数规模时,他们更关注算法效率和知识密度的提升。
AutoThink就是技术哲学的集大成者,通过优化思维路径,而不是堆砌参数,实现了质的飞跃。就像团队负责人说的:“让模型学会不做啥,比让它能做啥更难能可贵。”
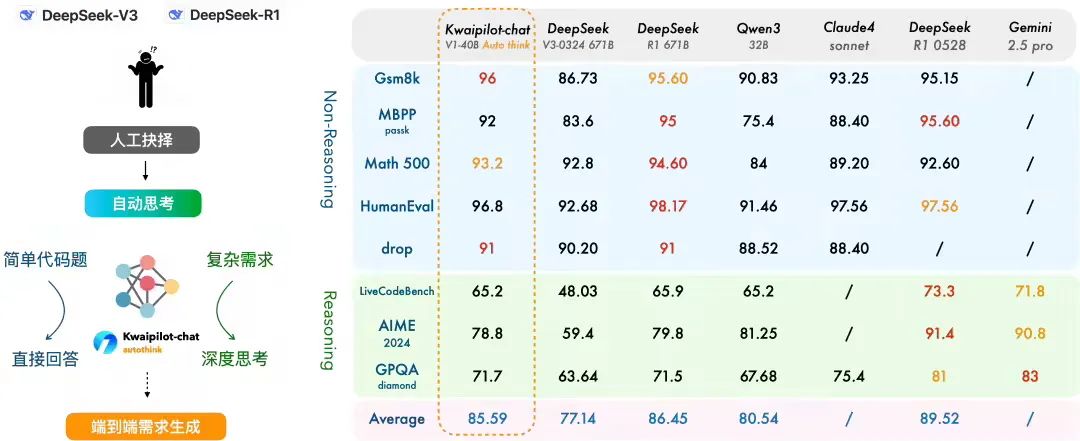
AutoThink的发布,我认为是大模型发展路径一个重要转折点。
(一)当GPT-5、Claude-3都在朝着万亿参数迈进时,快手证明了优化推理效率可以带来更显著的性能提升,为中小机构开辟了一条新赛道。
(二)通用能力到场景智能过程中,模型针对数学、编程等专业场景优化了思考模式,标志着大模型正从“通才”向“专才”转变。
(三)黑盒模型到透明过程中,思考路径的自主切换让模型的决策过程变得可解释,为解决AI黑箱问题提供了新思路。
随着AutoThink开源,它的技术应用范围也会超出代码生成领域。
⋯ ⋯
• 智能客服场景:简单问题秒回,复杂问题深度处理,资源消耗降低40%以上;
• 教育领域:根据学生水平调节讲解深度,构建个性化学习路径;
• 视频创作:简单镜头快速生成,复杂运镜精细推演;
• 医疗诊断:常规症状快速筛查,疑难病症深度推理,优化诊断资源分配。
有意思的是,AutoThink的技术路径和诺贝尔奖得主卡尼曼在《思考,快与慢》中提到的人类认知双系统理论很像。
⋯ ⋯
AI模型开始学会直觉和深思的平衡,我们不得不开始新的思考方式。
模型新能力是不是比堆砌万亿参数的全能模型,更接近真正的智能。当模型学会战略性偷懒,是不是意味着机器智能离人类智慧又近了一步?
快手团队在技术报告里提到,下一步要给模型赋予思考中使用工具的能力。当自动思考遇上工具调用,人机协作的新范式可能就要开启了。
KwaiCoder-AutoThink的开源特别有意义,在大模型赛道竞争这么激烈的时候,快手选择开放核心技术,会推动整个行业突破资源内卷的困境。
大模型的思考经济学中,用最小的计算成本获得最优的输出,比任何参数突破都更有革命性。当模型学会在快慢思考之间优雅切换时,它不仅是技术突破,更是机器智能向智慧蜕变的曙光。未来的AI王者,不是算力最强的,而是思考最巧妙的。
(文:陳寳)