
在信息爆炸的数字时代,如何从海量网络数据中高效获取有价值的信息,成为互联网技术领域的一道难题。
传统搜索引擎如同只能单次射击的猎枪,面对需要抽丝剥茧、层层深入的复杂问题时,往往显得力不从心。
而近期,阿里巴巴通义实验室带来的 WebDancer,如同一位训练有素的 “信息侦探”,以原生的 Agentic 能力,重新定义了复杂信息检索的游戏规则。
WebDancer 催生背景
传统搜索引擎处理任务只能返回零散的网页链接,却无法将这些碎片化信息串联成完整的逻辑链条。你需要手动在数十个网页间跳转,反复比对数据、验证逻辑,最终才能拼凑出答案的轮廓。
这种 “多步推理 + 跨页验证” 的需求,暴露了传统检索技术的核心短板:缺乏动态决策能力。
而随着大模型技术的发展,虽然 LLMs 和 LRMs 展现出一定的推理潜力,但直接应用于复杂任务时,要么受限于提示工程的精细度,要么困于简单训练数据的覆盖范围。
通义实验室的研究者意识到,解决这一问题需要从底层重构智能体的训练逻辑。于是,WebDancer— 一个基于 ReAct 框架的原生信息检索 Agentic Model应运而生。
它的目标很明确:让机器学会像人类研究员一样,在网络信息的迷宫中自主导航、思考和决策,完成类 DeepResearch 的复杂任务。
核心技术
WebDancer 的构建过程可以分为四个关键阶段:浏览数据构建、轨迹采样、监督微调以及强化学习。
(一)浏览数据构建
要让智能体学会复杂推理,首先需要为其提供高质量的 “思维训练素材”。WebDancer 采用两种创新方法合成数据集:
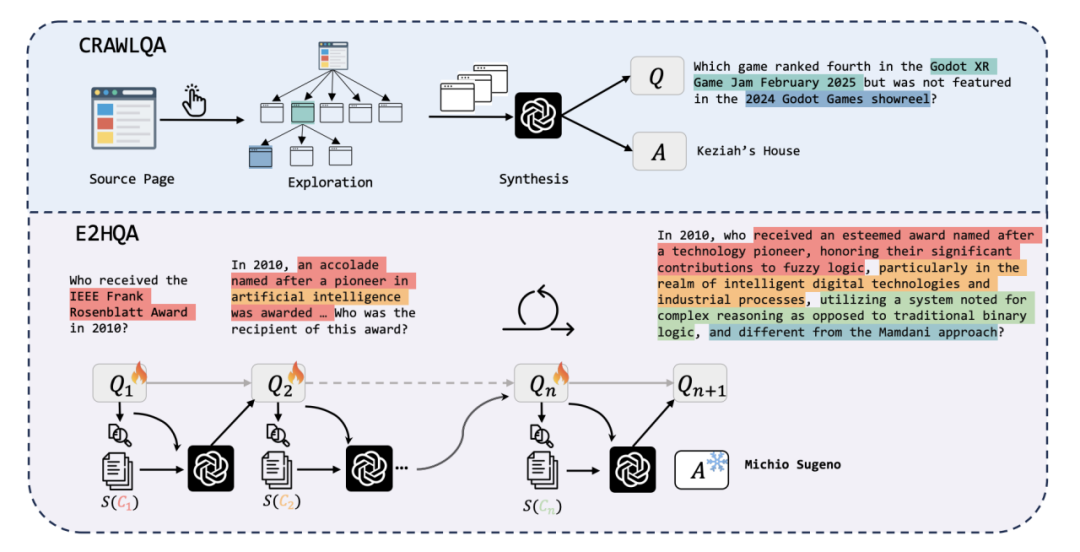
① CRAWLQA:模拟人类的 “知识勘探”
从 arxiv、github、wiki 等专业网站出发,WebDancer 像一位不知疲倦的爬行者,递归浏览网页,收集从主页面到子页面的层级化信息。
随后,借助 GPT-4o 的强大生成能力,这些信息被转化为涵盖计数问题、多跳问题、交集问题等多种类型的问答对。
② E2HQA:从简单到复杂的 “思维升级”
研究者发现,人类解决复杂问题往往遵循 “循序渐进” 的逻辑。E2HQA 正是基于这一洞察,从简单问答对出发,通过逐步引入技术细节、扩展问题维度,将单步问题转化为多步推理任务。
(二)轨迹采样
有了优质数据,如何让智能体学会 “行动策略”?WebDancer 采用拒绝采样机制,结合两种思考模式编织 “决策地图”:
① 短链思考:快速定位关键路径
利用AI大模型(如:GPT-4o)的强推理能力,直接生成 ReAct 轨迹,如同为智能体提供 “标准答案解析”。这种方式能快速获取高质量的短路径决策样本,让智能体掌握基础的 “问题 – 动作” 映射逻辑。
② 长链思考:模拟人类的 “试错探索”
通过推理模型(如:QwQ-Plus),逐步输入历史动作和观察结果,让智能体自主决定下一步行动。这一过程如同让新手研究员独立设计实验,允许其在试错中积累经验。
通过多次拒绝采样,研究者筛选出连贯、高效的长链轨迹,确保智能体学会应对复杂场景的 “迂回策略”。
(三)监督微调
在监督微调阶段,WebDancer 开始学习 “职业研究员” 的工作范式。
通过将采样得到的轨迹输入模型,智能体逐渐掌握 “推理 – 行动 – 再推理” 的循环逻辑:何时需要调用搜索工具获取新信息?何时应该基于已有知识进行归纳?这种 “边思考边行动” 的节奏,正是解决多步问题的核心能力。
(四)强化学习
如果说监督微调是 “理论学习”,那么强化学习就是 “实战演练”。
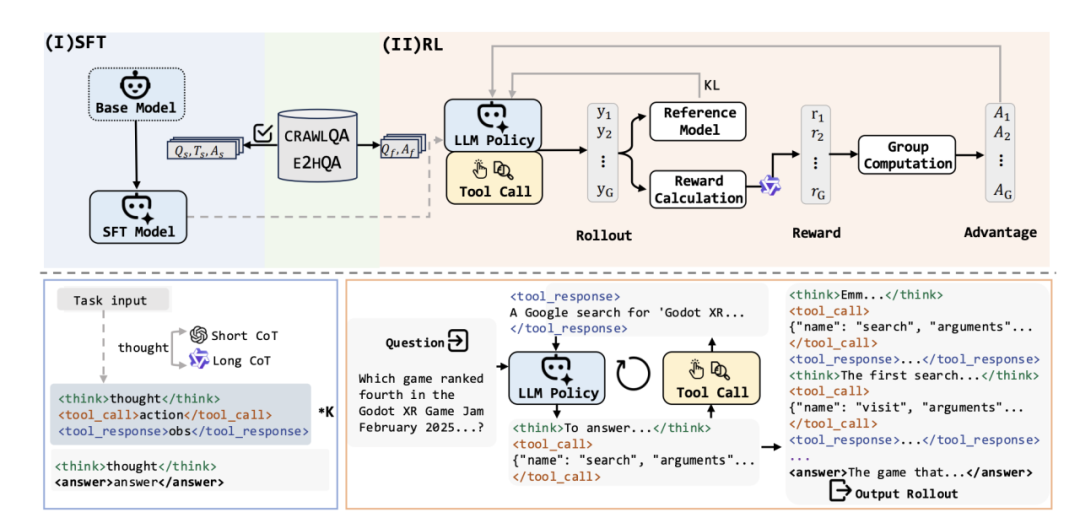
WebDancer 采用 DAPO 算法,通过动态采样机制激活那些在监督阶段未被充分利用的问答对。
不仅提高了数据利用效率,更让智能体在多工具协同、长程决策中展现出更强的鲁棒性。
实验分析
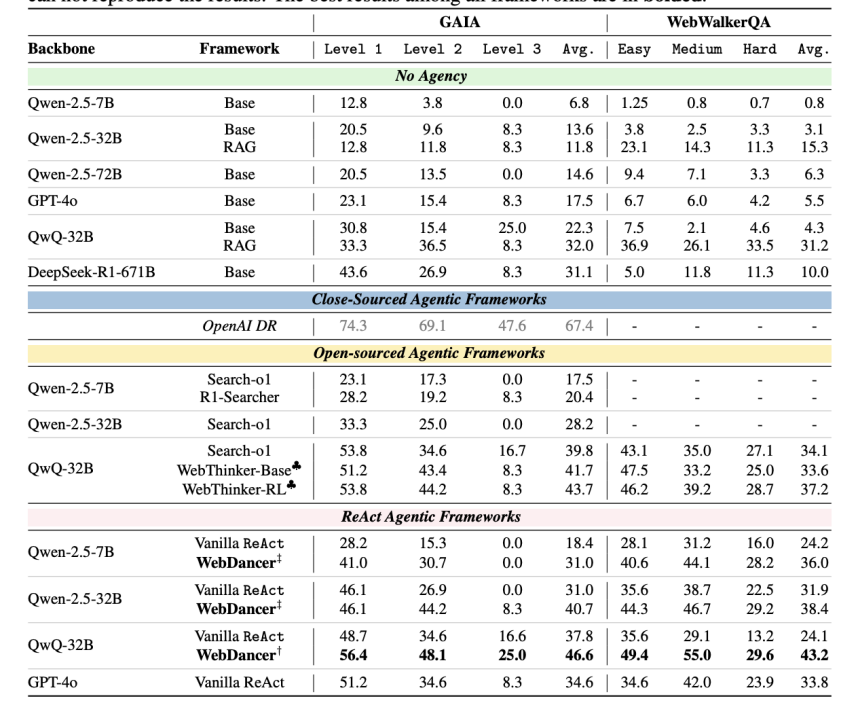
在GAIA和WebWalkerQA两个高难度基准测试中,对 WebDancer 进行了实战检验:
-
• 在 GAIA 基准中,WebDancer 以61.1% 的 Pass@3 分数刷新纪录,远超 Vanilla ReAct。 -
• 在 WebWalkerQA 测试中,其54.6% 的 Pass@3 分数同样领先多数对比模型,尤其在 “Hard” 难度任务中,优势更为显著。
未来展望
WebDancer 的诞生,只是智能体革命的序章。通义实验室的研究者们早已为其规划了更广阔的进化路径:
-
• 工具生态拓展:从基础的搜索和浏览工具,升级为支持浏览器建模、Python 沙盒环境等复杂工具。未来,WebDancer 将能直接执行网页交互、数据抓取、代码运行等操作,完成从信息检索到数据分析的全链条任务。 -
• 任务边界突破:当前聚焦于短答案检索的 WebDancer,将向开放域长文本写作进军。 -
• 泛化能力验证:参与更多跨领域基准测试,从科技领域拓展至人文、财经等场景,验证其在不同知识图谱中的适应性。
写在最后
从搜索引擎到智能体,我们见证的不仅是技术的迭代,更是 “机器辅助人类认知” 的范式升级。
在闭源模型主导 Agentic 能力的当下,WebDancer 的价值不仅在于技术突破,更在于其开源理念带来的范式革新。
未来,随着工具集成的完善和任务边界的拓展,我们有理由期待,这些不知疲倦、逻辑严密的 “数字研究员”,将在科研探索、商业决策、公共事务等领域大显身手,成为人类智慧的延伸,共同解锁更广阔的知识边疆。
正如通义实验室研究者所言:“WebDancer 不是终点,而是起点。它的每一次进化,都是对‘机器如何更懂人类需求’的深入回答。”
在这个信息过载的时代,这样的探索,或许正是我们穿越数据迷雾、抵达真知的关键钥匙。
参考资料:
-
• 阿里通义实验室投稿PR -
• 论文:https://arxiv.org/pdf/2505.22648 -
• GitHub 地址:https://github.com/Alibaba-NLP/WebAgent

(文:开源星探)