


引言:当视频生成遇见 “全能导演”
想象一下:输入一段文字描述、指定相机运动轨迹、上传人物照片、勾勒场景深度,AI 就能自动生成符合所有要求的高质量视频 —— 这不再是科幻!
可灵团队最新论文提出的 FullDiT,正是这样一款 “全能型” 视频生成基础模型,让多条件控制视频生成成为现实。
更重要的是,FullDiT 不仅仅是一个控制条件到视频生成的应用型工作,更是控制架构上的一次革新——使用全注意力机制统一引入所有控制条件。


论文链接:
https://arxiv.org/pdf/2503.19907v1
主页链接:
https://fulldit.github.io/
评测集合:
https://huggingface.co/datasets/KwaiVGI/FullBench

痛点直击:传统方法的三大瓶颈
从短视频爆发到 AI 视频生成效果飞升,视频内容生产领域正经历前所未有的变革。然而,当前主流的视频生成模型通常仅通过文本粗略控制内容,随着用户对于视频生成需求的提升,越来越多的控制条件被引入视频生成,多种条件的组合使用也逐渐成为刚需。
在这种情境下,过往基于 Adapter 的方法(如 ControlNet)虽能添加额外控制信号,却面临三大难题:
1. 分支冲突:独立训练的 Adapter 组合时相互干扰,导致生成效果混乱;
2. 参数冗余:每个 Adapter 都需额外参数,参数量飙升;
3. 性能局限:生成质量始终不如全模型微调,灵活性不足。

FullDiT 如何破局?
论文提出统一全注意力框架,将文本、相机、身份、深度等多模态条件直接融合为统一序列表示,从根本上解决上述问题,实现 “一次训练,多控全能”!
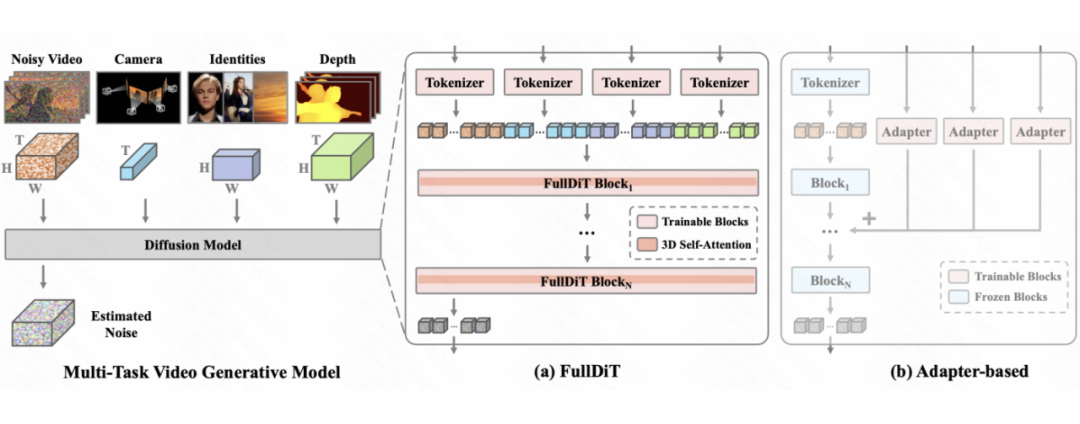
▲ 图1: 我们在左侧展示了多任务视频生成模型的扩散过程。出于研究目的,本文展示了仅包含时间维度的相机信息、仅包含空间维度的身份信息以及同时包含时间和空间维度的深度视频等输入条件。该模型架构还可以纳入额外的条件,以实现更广泛的应用。如图(a)所示,FullDiT 通过以下步骤对各种输入进行统一处理:(1)将输入条件进行 patchify 并转换为统一的序列表示;(2)将所有序列拼接成一个长序列;(3)利用全自注意力机制学习多种条件。相比之下,早期基于 Adapter 的方法(如图(b)所示)采用不同的 Adapter 独立运行以处理各种输入,导致分支冲突、参数冗余以及性能欠佳。每个模块的下标表示其层索引。

核心创新1:统一架构学习多种控制条件
FullDiT 摒弃传统基于 Adapter 方法的“补丁式”设计,采用 Transformer 的全注意力架构,将 3D 相机轨迹、参考图像、深度视频等多模态信号统一编码为序列 tokens,通过 3D 自注意力机制捕捉时空关联。
-
长序列建模:相机运动(提供场景整体运镜信息)、参考图特征(提供主体物体信息)、深度视频(提供结构和深度信息)统一编码为序列表征,在共享的注意力模块中联合处理条件,从而生成逻辑一致的视频序列;
-
无需额外参数:无需额外参数,仅通过共享注意力层实现多条件控制。
-
最佳效果:从根本上解决了基于 Adapter 的方法中常见的分支冲突问题,并通过有效的端到端训练实现了卓越的多任务可控生成。
-
Scaling Ability 和 Emergent Ability:该建模方式可以展现良好的 Scaling Ability 和 Emergent Ability,如使用更少数据达到更好的控制效果,训练中未见过的条件组合(如 “相机+身份” 联合控制)也能通过注意力机制推理生成合理画面。

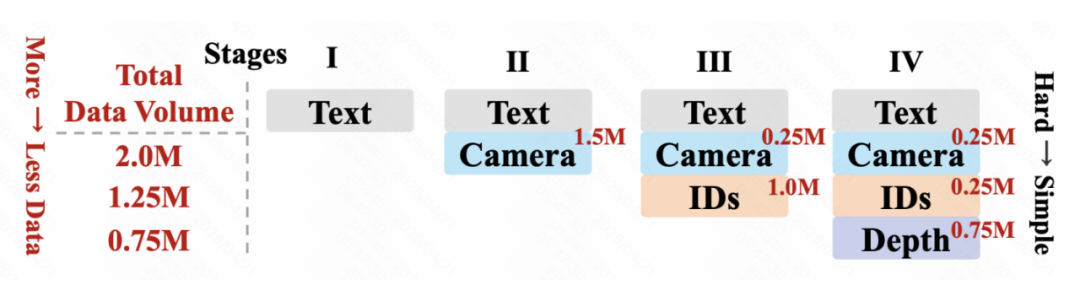
核心创新2:分阶段训练:从基础到复杂的渐进学习
在预训练期间,我们观察到更具挑战性的任务需要更多训练,并且应该更早地被引入。相反,过早引入较容易的任务可能会导致模型优先学习它们,从而阻碍模型更好的学习到具有挑战性的任务。
基于这一观察,我们 = 采用文本 → 相机轨迹 → 参考图片 → 深度视频的递进式训练顺序,先让模型掌握语义理解(文本),再逐步学习动态控制(相机轨迹)、特征保持(参考图片)和空间结构(深度视频)。

实验结果1:对比过往方法
我们在自动化指标上和视觉效果上展示了 FullDiT 与过往单控制条件到视频的对比,包括与 ConceptMaster 对比参考图到视频生成结果,与 Ctrl-Adapter 和 ControlVideo 对比深度视频到视频结果,以及与 MotionCtrl、CamI2V 和 CameraCtrl 对比的相机参数到视频结果。
结果表明,尽管 FullDiT 集成了多个条件,但在文本、相机轨迹、参考图和深度控制等指标上仍实现了最先进的性能,从而验证了 FullDiT 的有效性。
特别的,对于参考图到视频生成任务,我们使用 1B 参数的 ConceptMaster 作为基准,并与 FullDiT 使用完全相同的训练数据进行训练,这确保了在相同模型架构和训练数据下的公平比较,进一步验证了全注意力机制的优势。

▲ 图2:可视化对比结果
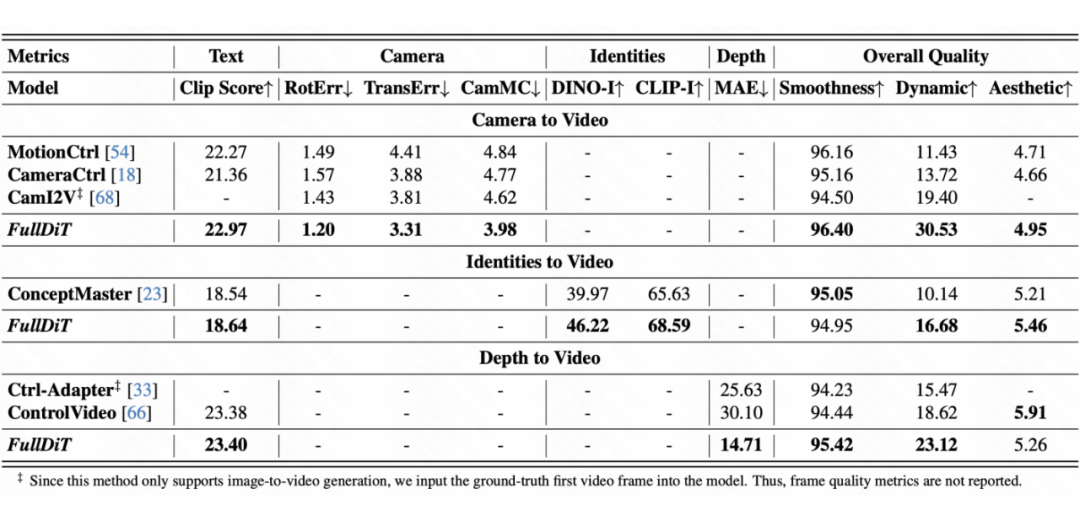
▲ 图3:自动化指标对比结果。我们采用涵盖五个方面的 10 项指标:文本对齐、相机控制、参考图相似度、深度控制和整体视频质量。我们使用 CLIP Similarity 评估文本对齐。对于相机控制,我们采用 CamI2V 提出的 RotErr(旋转误差)、TransErr(平移误差)和 CamMC(相机运动控制误差)。对于参考图相似度,我们通过 DINO-I 和 CLIP-I 进行评估。深度控制采用平均绝对误差(MAE)衡量。我们引入 MiraData 的三项指标评估视频质量:使用CLIP相似度衡量平滑度(smoothness)、使用光流衡量动态大小(Dynamic),以及使用 LAION-Aesthetic 模型衡量美学评分(Aesthetic)。

实验结果2:多控制条件效果
由于基准方法的缺失,我们主要在此展示可视化效果:






实验结果3:Scalability Ability
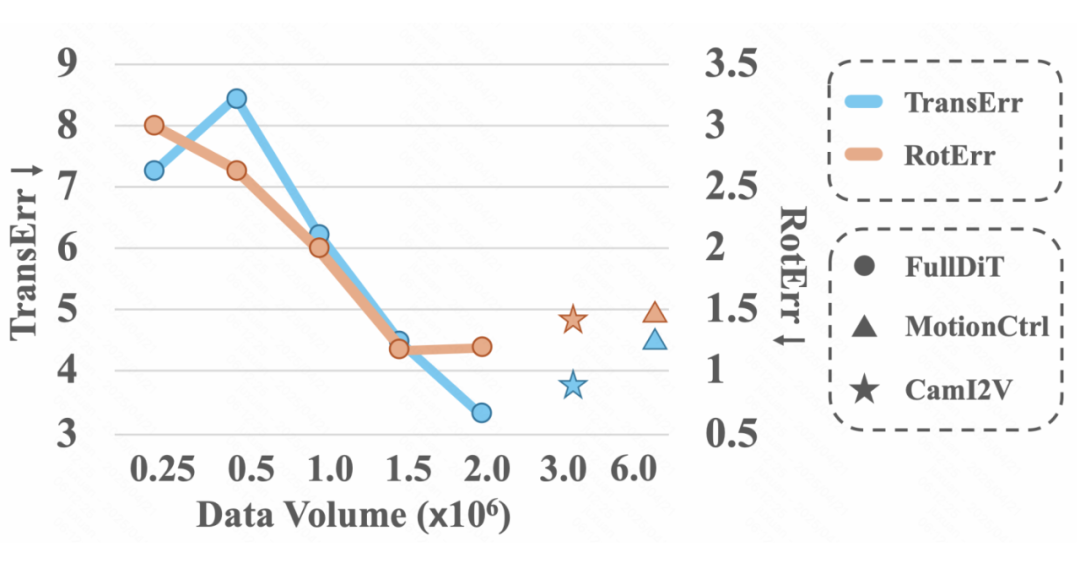
▲ 图4:相机参数到视频任务中随训练数据量增加的性能表现
如图 4 所示,随着训练数据量的增加,FullDiT 在相机到视频任务中的平移误差(TransErr)和旋转误差(RotErr)均显著改善,这体现了 FullDiT 的可扩展性。相比之下,MotionCtrl 使用了 640 万的数据量,CamI2V 使用了 320 万的数据量,但两者的表现均不如 FullDiT。这进一步证明了全注意力机制的有效性。

总结
本文提出了 FullDiT,利用统一的全注意力机制无缝集成多模态条件,解决了基于 Adapter 方法的局限性,如分支冲突和参数冗余,实现了可扩展的多任务和多模态控制。大量实验证明了 FullDiT 的先进性能和涌现能力。
进一步,通过引入 Any2Caption 作为通用条件理解器,将复杂的异构模态映射为结构化语言提示,显著提升 FullDiT 对新模态(如深度、相机参数、参考图像等)下的理解与生成质量。
实验证明,集成 Any2Caption 后的 FullDiT 在生成精度、控制稳定性以及任务泛化能力方面均取得了更优表现,验证了”结构化提示 + 统一架构”在可控生成任务中的协同优势。这一设计也为未来探索更多模态(如音频、语音、点云、光流等)的高效集成提供了新思路。
(文:PaperWeekly)