
编辑:张倩、+0
近日,新一届 ACM 博士论文奖正式公布。
该奖项每年颁发给计算机科学与工程领域最佳博士论文的作者。今年颁发的是 2024 年的奖项,包括一个博士论文奖和两个博士论文奖荣誉提名。
获得博士论文奖的论文非常有现实意义,它研究的是:现在心理健康问题越来越多,但专业心理医生不够用,怎么办?
我们知道,在 DeepSeek 等 AI 模型火起来之后,很多人都把 AI 当成了心理医生。但很多时候,AI 并不能像真正的心理治疗师一样提供专业指导。或许,「人机协作」是条更现实的折中路线。
在论文中,获奖作者 Ashish Sharma 探索了多种方法来实现更好的人机协作。他的方法类似于:
-
给志愿者配教练:让更多普通人能提供有效心理支持;
-
给用户配向导:让心理自助工具更容易上手;
-
给 AI 配监督员:确保 AI 心理咨询师的质量。
他最近开发的 AI 辅助心理健康工具已被公开发布,并有超过 16 万用户使用,其中大多数是低收入人群。使用这些工具的人群中,超过 50% 的家庭年收入低于 4 万美元。
除了这篇论文,还有两篇论文获得了博士论文奖荣誉提名,其中一篇研究的问题是「利用伪随机分布揭示低复杂度计算模型的固有计算局限性」;另一篇则专注于「大型语言模型如何利用它们在训练时学习到的海量文本数据」。

以下是获奖论文的详细信息。
ACM 博士论文奖

-
获奖者:Ashish Sharma(该论文是他在华盛顿大学攻读博士学位期间完成的,Sharma 目前是微软应用研究办公室的高级应用科学家)
-
论文标题:Human-AI Collaboration to Support Mental Health and Well-Being
-
论文链接:https://digital.lib.washington.edu/researchworks/items/2007a024-6383-4b15-b2c8-f97986558500
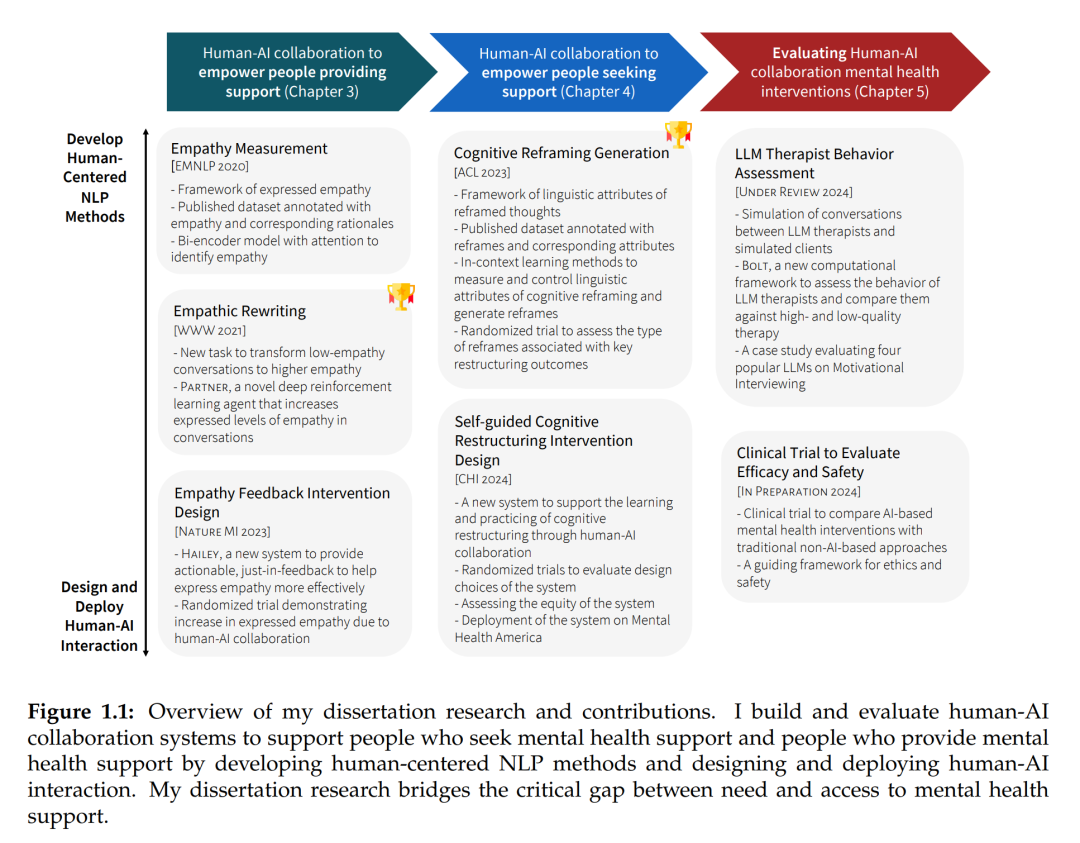
随着全球心理健康问题激增,医疗保健系统正在努力为所有人提供可及且高质量的心理健康护理。尽管医疗可以为面临心理健康挑战的人们提供支持,但临床医生短缺和心理健康污名等障碍通常限制了人们获得治疗的机会。在论文中,作者研究了人机协作如何改善心理健康支持的可及性和质量。
首先,他研究了人机协作如何帮助提供支持的人员进行有效且高质量的对话。具体而言,他关注了 Reddit 和 TalkLife 等在线同伴支持平台上的支持者。虽然支持者有动机且善意地帮助寻求支持的人,但他们通常缺乏训练,不了解促进有效支持的关键心理治疗技能,如共情。通过一种基于强化学习的方法,并通过对来自最大同伴支持平台的 300 名同伴支持者进行的随机试验进行评估,他证明了基于 AI 的反馈可以帮助支持者在对话中更有效地表达共情。
其次,他研究了人机协作如何使自我指导的心理健康干预更容易获得、更容易参与,从而增强寻求支持的人的能力。自我引导干预,如学习和练习应对技能的「自助」工具,往往在认知上要求较高且在情感上具有触发性,这造成了可及性障碍,限制了其大规模实施和采用。作者以消极思想的认知重构为案例研究,在一家大型心理健康网站上进行了一项有 15531 名参与者的随机试验。结果表明,人机协作支持人们克服消极思想,并为心理学理论提供了有关导致积极结果的过程的信息。
第三,作者系统性地评估了用于心理健康支持的人机协作系统。虽然人们对利用 AI 进行心理健康支持有很大兴趣,但缺乏评估其有效性、质量、公平性和安全性的方法。他研究了如何通过临床试验有效评估 AI 心理干预措施与传统方法相比的短期 / 长期疗效、公平性和安全性。此外,他还开发了一个计算框架,可自动评估大型语言模型(LLM)充当治疗师时的行为表现。通过分析 13 种不同的心理治疗技术,他将 LLM 治疗师的行为与高质量及低质量人类治疗师进行对比。分析表明,LLM 的行为模式往往更接近低质量治疗师 —— 例如当来访者倾诉情绪时,它们会更频繁地提供解决问题建议,这种做法明显违背常规治疗准则。
作者在论文中描述了他开发的两个支持心理健康和福祉的人机协作系统,以及此类系统的评估框架。这项研究让人和 AI 能够协作,既帮助需要心理支持的人掌握应对技巧,也辅助专业人员提升辅导能力。
ACM 博士论文奖荣誉提名
论文 1

-
获奖者:Alexander (Zander) Kelley(在伊利诺伊大学香槟分校获得博士学位)
-
论文标题:Explicit pseudorandom distributions for restricted models of computation
-
论文链接:https://www.ideals.illinois.edu/items/132651
为了理解具体计算模型的(可证明的)局限性,我们需要回答一个根本性的问题:某些计算任务是否存在低复杂度模型根本无法完成(甚至不能近似完成)的情形?
回答这一问题是解决复杂性理论中多个关键性未解难题(例如「P 与 NP 问题」和「P 与 BPP 问题」)所必经的步骤。
在众多应用中,尤其是密码学领域,我们更需要一种稳健的计算限制,即存在某种特定任务,使得任何受限于低复杂度的算法都无法成功执行,甚至无法做出可靠近似。
本论文研究的主题为伪随机分布(针对低复杂度模型),该工具为验证此类计算限制提供了一种特别清晰的方式。所谓伪随机分布,是指某种可高效生成的概率分布,其样本在分布上与某些「非目标样本」足够相似,以至于任何低复杂度的测试函数都无法可靠地区分它们。
本论文所研究的伪随机分布来自我们在一系列工作中的构造与分析,其结果均建立了一种面向特定计算模型的稳健性限制。这些模型包括:
-
(任意顺序)一次读取分支程序(Read Once Branching Programs):一种捕获某些小空间算法的计算模型;
-
常数深度电路(Constant-Depth Circuits):一种捕获某些高度可并行化算法的计算模型;
-
多项式阈值函数(Polynomial Threshold Functions):一种简单的几何计算模型,在学习理论等背景下自然出现;
-
多方通信协议(Multiparty Communication Protocols):一种抽象计算模型,用于研究主要受通信瓶颈限制的系统。
论文 2

-
获奖者:Sewon Min(在华盛顿大学获得博士学位,即将担任 UC 伯克利助理教授)
-
论文标题:Rethinking Data Use in Large Language Models
-
论文链接:https://digital.lib.washington.edu/server/api/core/bitstreams/76fbf5f7-b608-42a5-a513-a7c0218579f1/content
大型语言模型(如 ChatGPT)已经彻底改变了自然语言处理乃至更广泛的人工智能领域。在本论文中,作者讨论了她对理解和推进这些模型的研究,其核心在于它们如何利用其训练所用的超大规模文本语料库。
首先,作者描述了我们为理解这些模型如何在训练后学习执行新任务所做的努力,证明它们所谓的语境学习能力几乎完全取决于它们从训练数据中学习到的内容。

接下来,作者介绍了一类新型的语言模型 —— 非参数( Nonparametric )语言模型,这类模型将训练数据重新用作数据存储,从中检索信息以提高准确性和可更新性。

作者描述了在建立此类模型基础方面的工作,包括最早被广泛使用的神经检索模型之一,以及一种将传统的两阶段流水线简化为一阶段的方法。
作者还讨论了非参数模型如何为负责任的数据使用开辟新途径,例如,区分许可文本和受版权保护的文本并以不同方式使用它们。
最后,作者展望了我们应该构建的下一代语言模型,重点关注高效扩展、改进的事实性和去中心化。
(文:机器之心)