
松下控股株式会社(Panasonic HD)和松下美国研发公司(PRDCA)与美国加州大学洛杉矶分校(UCLA)的研究人员合作,开发了 OmniFlow,这是一种多模态生成式人工智能(AI),可以自由转换不同的数据格式,如文本、图像和音频(以下简称为“任意到任意”)。
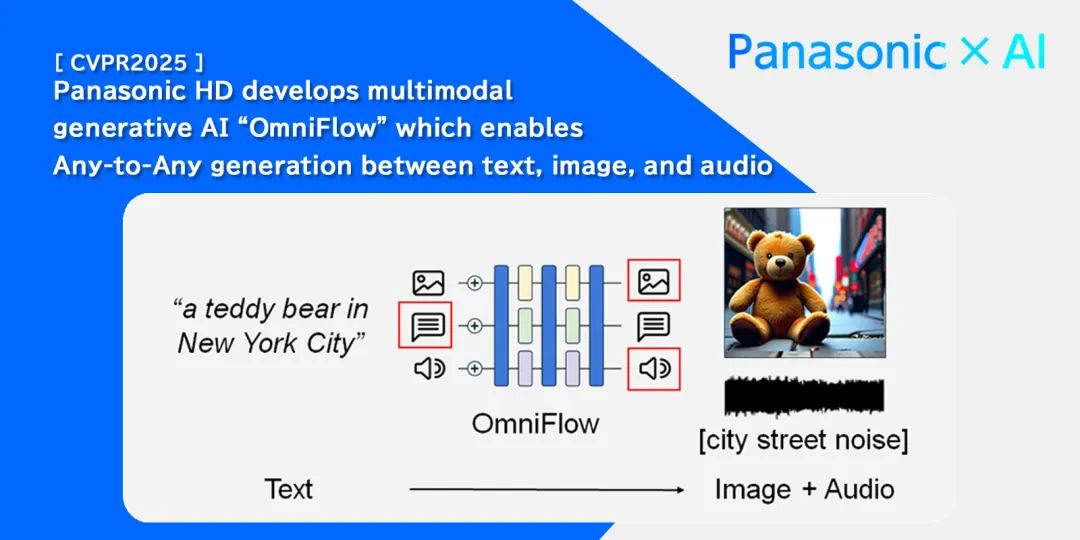
近年来,实现不同数据格式转换的多模态生成式 AI 研究非常活跃,但由于通常需要为处理的数据准备所有配对的数据作为训练数据,因此随着处理的数据类型增加,获取数据的成本也会增加。通过灵活组合针对每种数据格式的专业生成式 AI(文本 ↔ 音频,文本 ↔ 图像),OmniFlow 即使只有少量包含所有三种模态的数据(文本 ↔ 音频 ↔ 图像),也能学习高精度的任意到任意模型,并成功显著降低了创建训练数据的成本。(见图 1)
该技术因其先进技术而获得国际认可,并已被 2025 年计算机视觉和模式识别会议(CVPR 2025)—— 人工智能和计算机视觉领域的顶级会议之一 —— 接受。它将于 2025 年 6 月 11 日至 15 日在美国纳什维尔举行的全体会议上展示。

图 1 OmniFlow 生成示例
技术细节

Panasonic HD 和 PRDCA 正在进行多模态生成式 AI 的研究。近年来,除了文本和图像之外还纳入音频的多模态生成式 AI 引起了关注,但获取包含所有文本、图像和音频的数据的方法有限,且增加变化的成本很高。
解决这一问题的方法是加速多模态生成式 AI 使用的关键,近年来研究非常活跃。实际上,最近提出了一种即使处理的数据包括所有想要处理的数据格式的组合并不完全对齐也能学习的方法,但它是通过平均输入数据来实现的。可以说在表达能力方面仍有很大的改进空间。
另一方面,我们开发了 OmniFlow,它扩展了现有的图像生成流匹配框架*,并通过在生成过程中连接和处理三种不同数据特征来学习无法通过平均获得的复杂数据关系。(见图 2)
*一种使用 Flow 查找任意数据之间最优转换路径的技术。近年来,由于被各种生成模型(包括图像生成)采用而受到关注。
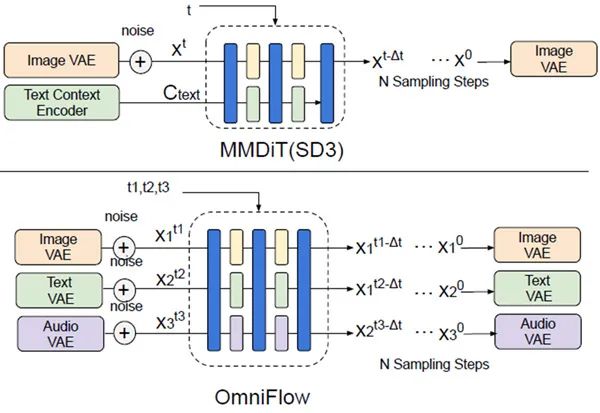
图 2 现有流匹配(上)和 OmniFlow(下)架构
OmniFlow 的一大优势是可以轻松将专门从事文本到图像和文本到音频生成的专业 AI 连接成一个单一的多模态生成式 AI。(见图 3)由于专业 AI 在生成每种数据方面表现出色,因此无需学习包含所有模态的大量数据,就能获得高多模态性能。
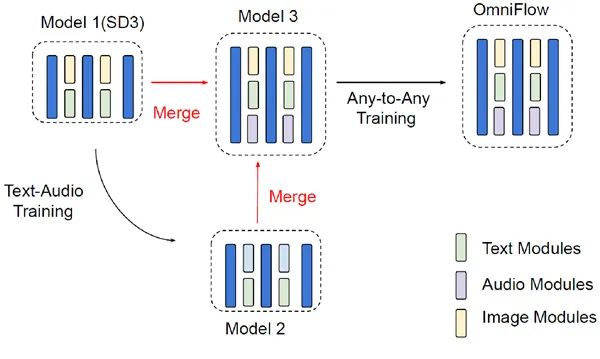
图 3 OmniFlow 学习过程
通过连接已经训练好的专业 AI,重新训练“文本→图像”任务和“文本→音频”任务。
在评估实验中,比较了“文本→图像”和“文本→音频”生成任务的性能与现有方法。(见图 4)结果表明,OmniFlow 在任意到任意方法(Generalist)和每个任务的专业方法中表现最佳。我们还发现,与其他任意到任意方法相比,训练 OmniFlow 所需的数据量可以减少至多 1/60。

图 4 评估结果(左:文本→图像,右:文本→音频)
Param 为模型参数数量,Images 为训练图像数量。Gen 是一个表示生成图像质量的指标,FAD 和 CLAP 表示生成音频的质量。↑ 表示数值越高性能越好,↓ 表示数值越低性能越好。
未来展望
新开发的 OmniFlow 是一种任意到任意方法,它灵活组合针对每种数据格式的专业生成式 AI(文本→音频,文本→图像),即使所有三种数据对(文本 ↔ 音频 ↔ 图像)的训练样本数量较少,也能实现高精度。通过在工厂和生活方式等各个领域学习这项技术,可以生成专门针对这些场所的各种类型数据,预计会扩大多模态 AI 的应用范围。
展望未来,Panasonic HD 将继续加快 AI 的社会实施,并推进有助于提高客户生活和工作场所实用性的 AI 技术的研发。
(文:AI音频时代)