

近期,社区开源了很多关于entropy在rl中的作用1[1]2[2]3[3]9[4],基本结论是:
合理的熵控制,可以让rl训的时间更久、效果越好(保持多样性,避免坍缩到某几个输出pattern)。输出多样性更容易提升模型的exploration效果(熵是一种衡量输出多样性的方法),其他多样性衡量的方法如smi/dpp/self-bleu等等,都需要在group-level计算(大部分通过reward-shaping控制熵的变化如6[5])
当然,[1][2]均是在off-policy的setting下给出的解决方案,[3][9]均验证了exact-onpolicy能够更好的保持policy的entropy(笔者日常实验都是exact-onpolicy,agent环境下会比较慢(加了acc-filter等等后,为了不浪费rollout样本,即使exact-onpolicy-setting也会变成offpolicy-setting,全看 rollout队列/exp队列的大小设置))
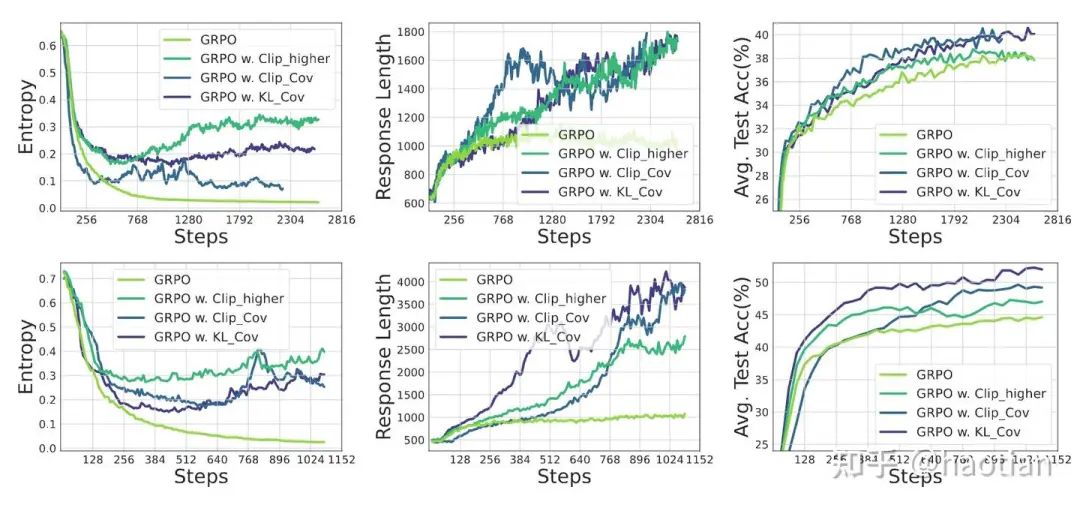
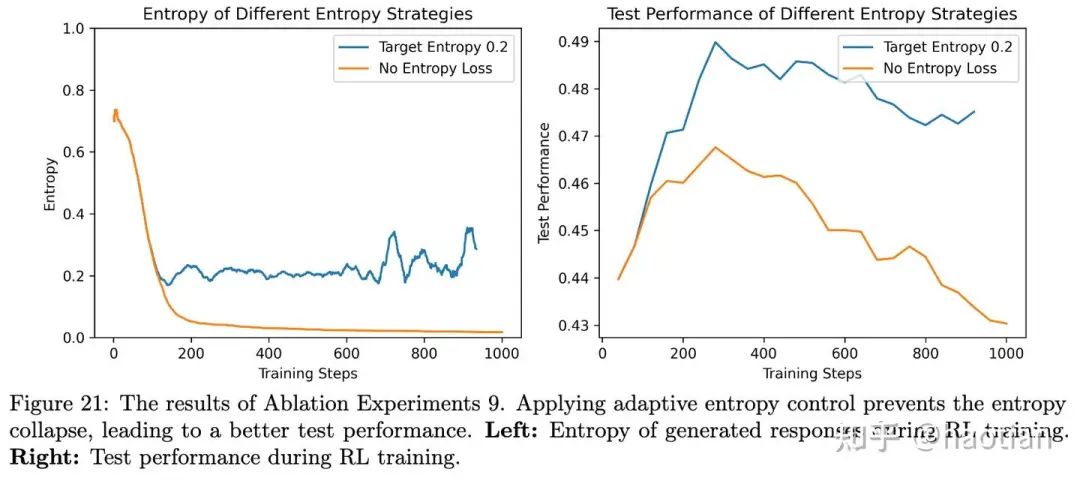
从优化目标入手,其优化目标是reverse-kl,优化过程会使得模型输出多样性下降,进而导致熵下降(熵下降几乎不可避免,但可以缓解(如clip-higher/entropy-loss/low-entropy-token-mask等等))。

4[6]5[7]则另辟蹊径探讨了negative-samples在policy-gradient中的作用。
[5]研究了instruct-model的负样本sft会带来怎样的影响(指标依然可以涨,但不如positive-samples-sft)
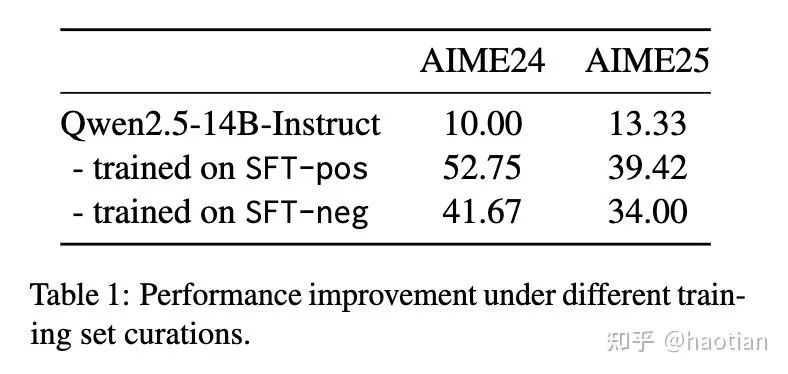
作者进一步对step做了segmentation,并通过llm-as-judge对negative-sample的step做了更细致的打分,避免过度惩罚负样本中的“正确step”(捞起来哪些思路正确的token)

[4]则进一步探讨了负样本在zero-rl中的作用(简而言之:负样本对于熵的保持有重要作用),且训练steps相对较少的情况下,可以提升效果(训的过多肯定会崩)
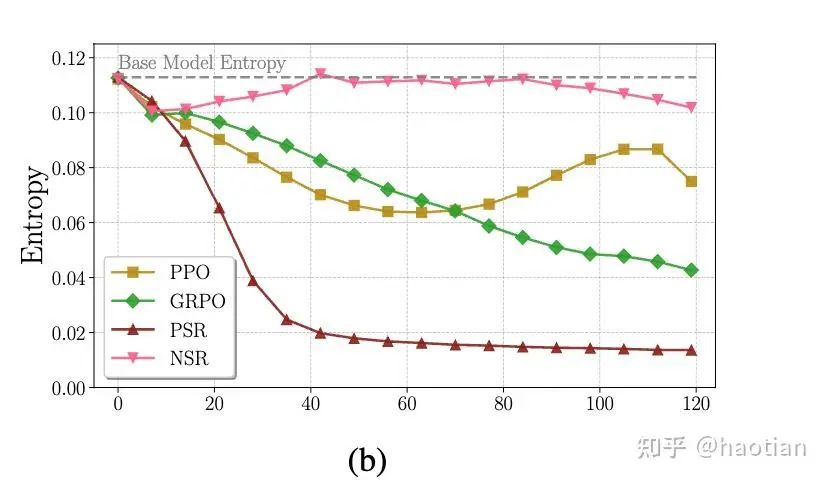
这里,nsr代表negative sample reinforcement(grpo/reinfroce等等critic-free的方法中,同一个response中每个token的advantages是一样的,对于答案错误的trajectory可以看成某种“NSR”)
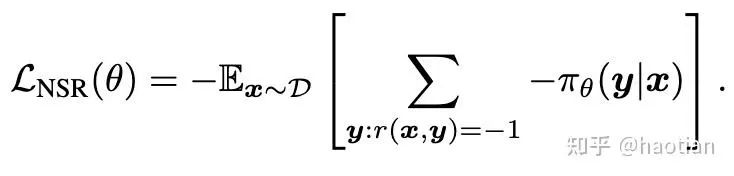
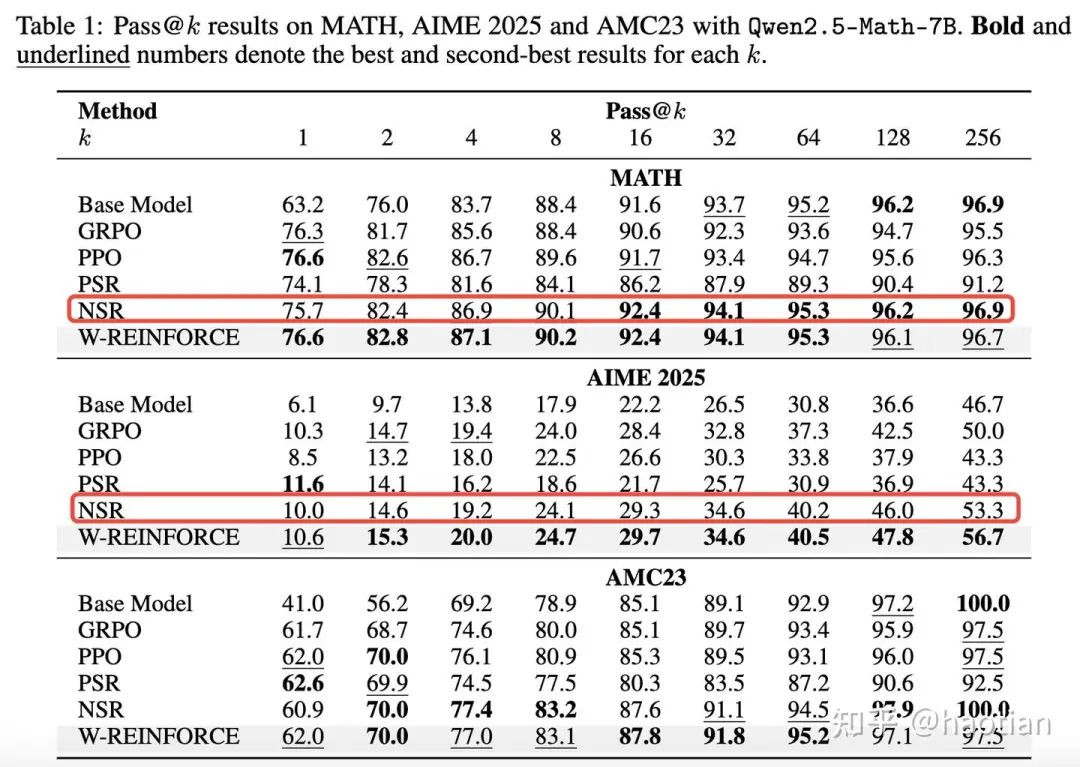
从[4]中可以看到,zero-rl-setting下,nsr在前100多个step保持着更好的entropy(几乎与base-model接近),而其他方法或多或少都会下降至某个区间(上下抖动)。
近期很多工作也会离线筛选rl-data(保留某个解决率区间的数据),结合[4]来看,也是期望能够引入一定比例的负样本,保持基线模型的熵较高(更容易探索)。
思考
从kl-divergence角度出发,reverse-kl不可避免降低输出多样性。从pg-loss出发,大概可以分出来两部分:positive-sample-reinforce以及negative-sample-reinforce。positive-sample-reinforce为sft,虽然是mle优化(有mode-coverage的效果),但受限于sft的response多样性,sft后的模型输出也会变窄(熵掉的比较多)。
而[4][5]则进一步探讨了negative-sample-reinforce的作用,即使答案错误的sft/zero-rl,在合适的训练setting下,也能让下游perfermance提升。[4]进一步使用negative-sample-reinforce在zero-rl-setting下,可以更好的保持base-model的entropy,并在合适的训练steps后效果提升显著
不从rl角度思考问题,以上工作大概都可以归结为某种 unlikelihood-training[6],即更为有效地使用负样本提升优化效率和效果(或者 unlearning)。
由于目前都在math/code上面实验(math/code也是各家base-model重点pretrain/ct/数据退火的重要组成部分),使用公开的math/code数据集基本都会被训进去(使得熵更容易下降),而一些合成的logic-game7[8]则较少地被用于base-model训练(体现为 起始的熵/熵下降都更缓慢)。
从数据角度来说,合成预训练阶段没见过的数据/更为合理的negative-sample保留(比如只保留acc在[0.1, 0.5]之间的数据、加入diversity-reward8[9])),可能可以更好地保持base-model的熵。
从算法角度,可能得找一个新的divergence,从根本上避免熵下降的问题。
(说明:由于都是基于qwen25系列模型的工作,实际上很多结论都是qwen25-based-xxx)
引用链接
[1] 1:https://arxiv.org/abs/2506.01939[2]2:https://arxiv.org/abs/2505.22617[3]3:https://arxiv.org/abs/2505.22312[4]9:https://arxiv.org/pdf/2505.23585[5]6:https://arxiv.org/abs/1908.04319[6]4:https://arxiv.org/abs/2506.01347[7]5:https://arxiv.org/abs/2505.14403[8]7:https://github.com/MiniMax-AI/SynLogic/tree/main[9]8:https://github.com/xiwenc1/DRA-GRPO
(文:机器学习算法与自然语言处理)