

在构建通用人工智能、世界模型、具身智能等关键技术的竞赛中,一个能力正变得愈发核心 —— 高质量的 3D 场景生成。过去三年,该领域的研究呈指数级增长,每年论文数量几乎翻倍,反映出其在多模态理解、机器人、自动驾驶乃至虚拟现实系统中的关键地位。
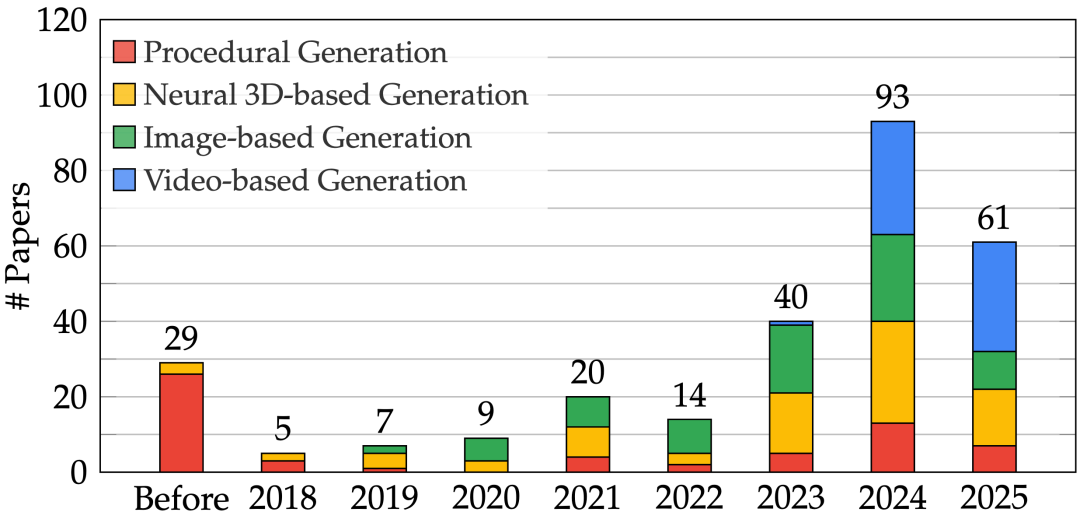
注:图中 2025 年的数据截至 4 月底
来自南洋理工大学 S-Lab 的研究者们全面调研了该领域最前沿的研究方法,发表了综述《3D Scene Generation: A Survey》,对 300+ 篇代表性论文进行了系统归纳,将现有方法划分为四大类:程序化方法、基于神经网络的 3D 表示生成、图像驱动生成,以及视频驱动生成。该综述还总结了 3D 场景生成在多个关键下游任务中的应用,包括 3D 场景编辑、人-场景交互、具身智能、机器人、自动驾驶等,并深入探讨了挑战与未来方向。
-
论文标题:3D Scene Generation: A Survey
-
论文链接:https://arxiv.org/abs/2505.05474
-
精选列表:https://github.com/hzxie/Awesome-3D-Scene-Generation
技术路线
四大生成范式全面解析
早期的 3D 场景生成工作主要通过程序化生成实现。自 2021 年以来,随着生成式模型(尤其是扩散模型)的崛起,以及 NeRF、3D Gaussians 等新型 3D 表征的提出,该领域进入爆发式增长阶段。方法日益多元,场景建模能力持续提升,也推动了研究论文数量的快速上升。这一趋势凸显出对对该领域进行系统化梳理与全面评估的迫切需求。
在本综述中,研究团队构建了一套系统的技术分类体系,将现有 3D 场景生成方法划分为四大主流范式,每类方法均结合代表性工作进行了深入梳理。
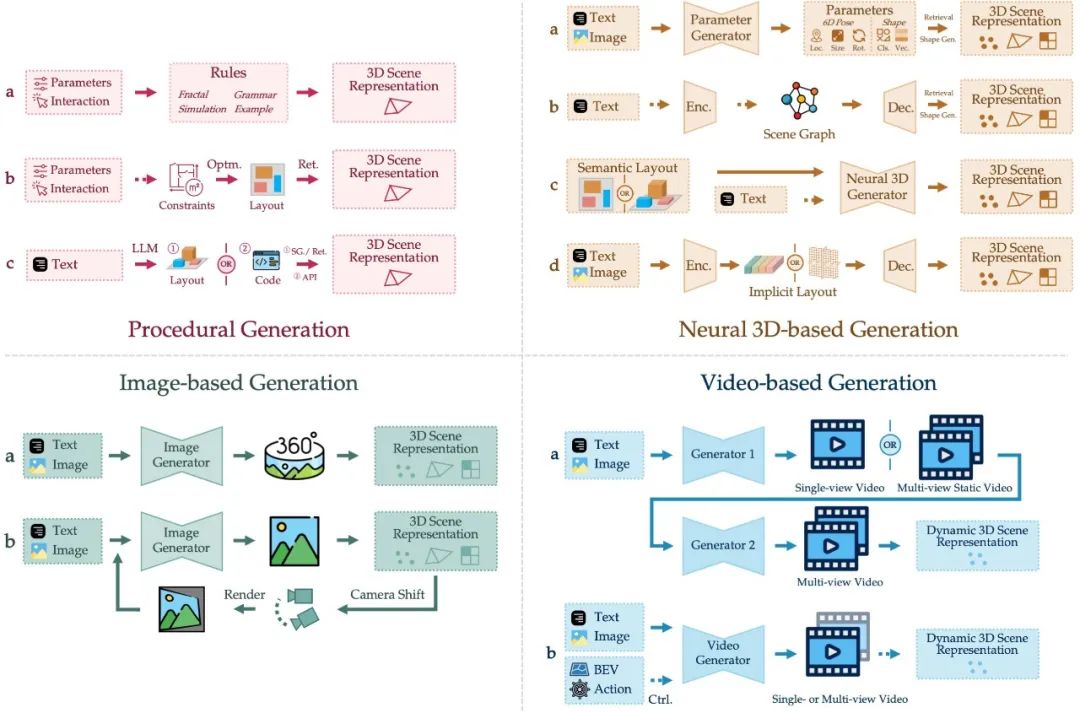
这四大范式为 3D 场景生成构建了清晰的技术路线,研究者还进一步对比了它们在多个维度下的性能指标,包括真实感、多样性、视角一致性、语义一致性、效率、可控性以及物理真实性。揭示了不同方法在可控性、真实性、效率与一致性之间的权衡。

程序化场景生成(Procedural Generation)
这类方法通过预定义的规则、物理或空间约束或借助大语言模型(LLMs)的先验知识,自动构建复杂的三维环境,如地形、建筑、道路、房间乃至整座城市。由于其良好的空间一致性,程序生成方法广泛应用于游戏和图形引擎中。根据具体范式,该类方法可进一步细分为:
-
基于规则的生成:通过预定义的算法或模拟过程进行生成;常用于地形或自然环境的生成;
-
基于约束优化的生成:通过物理规则、场景设计规则等约束设计目标函数,优化得到场景;常用于室内场景的生成;
-
大语言模型辅助生成:借助 LLM 生成场景布局,或作为智能体生成代码,控制程序化生成工具(如 Blender)进行生成。
基于神经网络的 3D 表征生成(Neural 3D-based Generation)
此类方法直接在三维空间中进行建模,生成 3D 场景的结构化布局(场景图、场景参数)或直接生成 3D 表征(点云、体素、网格、NeRF、3D 高斯等),具备强大的三维理解与表达能力。根据场景布局,可将其进一步分为:
-
参数控制:通过显式场景参数(如物体位置、方向、大小、几何 Embedding)控制场景布局,通过物体提取或物体生成完善细节;
-
图结构表示:使用场景图表达实体及其关系,通过物体提取或物体生成完善细节;
-
语义布局:通过二维或三维语义图提供布局,控制生成;
-
隐式布局:通过隐式布局控制场景布局,端到端学习生成空间结构和外观。
基于图像的生成(Image-based Generation)
图像生成技术的迅猛发展为 3D 场景建模带来了新的可能。该类方法以 2D 图像生成模型为基础,生成多视角图像后重建出场景的三维结构。它主要包括两种策略:
-
整体生成:一次性生成完整场景视图,通常表现为全景图。
-
迭代生成:逐步扩展场景视野,生成图像序列。通常通过深度估计方法获取显式 3D 表征来保证一致性。
基于视频的生成(Video-based Generation)
将 3D 场景视为时间序列展开的图像序列,视频生成范式融合了空间建模与时间一致性。借助视频扩散模型等新技术,这类方法能够合成带有视角移动或动态演化的沉浸式场景。根据生成流程的不同,可划分为:
-
一阶段方法:端到端生成视频,联合建模时间与空间信息。
-
两阶段方法:通过两阶段进行视频生成,分别控制场景的时间连续性与空间一致性。
当前面临的四大挑战
尽管 3D 场景生成取得了令人瞩目的进展,但距离真正 “可控、高保真、物理真实” 的三维世界建模仍有不小的鸿沟。
-
生成能力仍不均衡:目前不同方法各有擅长,程序化生成与神经 3D 方法擅长结构建模与空间控制,但难以实现真实的纹理与光照;图像和视频生成技术视觉效果逼真,但在保持空间一致性方面往往表现不佳,容易出现几何扭曲等问题。
-
3D 表征仍待改善:3D 表征形式持续演化,但在表达力、效率等方面各有短板。近年来,3D Gaussians 等新表征形式在效率方面取得进展,但不具备良好的物理支撑。如何构建既紧凑、高效,又具备物理意义和视觉真实感的场景级 3D 表征,仍是当前亟待突破的难题。
-
高质量数据仍是瓶颈:现有数据集两极分化,合成数据标注精细但缺乏多样性与真实感;真实世界扫描数据逼真却缺乏准确的结构语义信息。此外,现有数据很少包含物理属性、材质属性或交互信息,难以支撑物理真实的场景生成,进而支持机器人学习、具身智能等任务需求。
-
评估缺乏统一标准:目前评价指标分散,常依赖各自定义的视觉或几何指标,缺乏统一且兼具主观与客观的评估体系。近期出现的 Benchmark 主要关注图像或视频的评估,缺乏直接的对 3D 属性的评估,而如 Eval3D 等 3D Benchmark 局限于物体级建模,对完整场景的评估支持有限。
未来的四大发展方向
-
更高保真的生成:未来的 3D 生成模型应能同时在几何、纹理、光照和多视角一致性上做到协调统一,包括同时关注结构与外观,提升材质与光照建模质量、提升空间一致性、捕捉阴影、遮挡等细节场景要素。真正的场景级高保真还要求局部细节与全局空间和语义布局紧密协同,生成高真实度与沉浸感的 3D 场景。
-
引入物理约束:尽管目前的生成方法在视觉效果上已有显著进展,但往往忽略了物理真实性,例如物体的摆放、移动是否符合真实世界的物理规律。未来的研究应将物理先验、约束或模拟机制引入生成过程,以保证结果在结构、语义和物理行为上的一致性。例如,可借助可微分物理模拟器等手段引入物理反馈。这一方向对于需要在物理一致的环境中进行决策与控制的应用尤为关键,如具身智能和机器人等。
-
支持交互的场景生成:随着 4D 场景生成的发展,当前方法已经能够生成带有可移动物体的动态环境。然而目前的大多数场景生成仍缺乏响应能力,无法根据用户输入或环境变化做出反馈。交互式场景生成不仅要求实现 “被动式” 的动态,更能在物理交互、用户指令或环境条件变化下作出合理响应。这将要求模型具备理解物体可用性、因果关系以及多智能体之间的交互逻辑。
-
感知-生成一体化:统一感知与生成能力,是下一代 3D 场景建模体系的一个重要发展方向。分割、重建、生成等任务本质上都依赖相同的空间与语义先验信息,未来可通过统一架构实现双向能力:既利用感知能力提升生成的准确性,也通过生成能力增强对场景的理解。这类模型可作为通用的 “感知-生成” 主干网络,为具身智能体提供一体化的视觉、语言与 3D 空间推理能力。

©
(文:机器之心)